Regression Analysis Flashcards
(81 cards)
what does covariance measure?
Measures the direction of linear relationship between two (continuous) variables.
Can be positive or negative
Positive: as x increases, y tends to increase
Negative: as x increases, y tends to decrease
what does correlation coefficient measure?
strength (and direction) of the linear relationship between two variables, X and Y.
Indicates the degree to which the variation in X is related to the variation in Y.
is correlation coefficient is measured for population, it is called?
ρ
is correlation coefficient is estimated for a sample,
use r; i.e. r estimates ρ
describe results from correlation coefficient
Always between -1 and +1.
ρ =+1: perfect positive linear relationship
ρ =-1: perfect negative linear relationship
ρ =0: no linear relationship (could be a different sort of relationship between the variables)
what is covariance and correlatoin coefficient is not used with continuous variables and the variables are not normally distributed?
r will be “deflated” and underestimates ρ.
E.g. in marketing research, often use 1-5 likert scales: if rating scales have a small number of categories, data is not strictly continuous, so r will underestimate ρ
covariance and correlation coefficient are appropriate for use with
continuous variables whose distributions have the same shape (e.g. both normally distributed).
describe hypothesis test for correlation
1. Hypothesis
- Test statistic
- Decision rule
- Conclusion
H0: ρ=0 (if correlation is zero, then there is no significant linear relationship)
H1: ρ≠0
describe hypothesis test for correlation
- Hypothesis
2. Test statistic
- Decision rule
- Conclusion
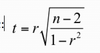
describe hypothesis test for correlation
- Hypothesis
- Test statistic
- Decision rule
4. Conclusion
in terms of whether a significant linear relationship exists.
describe hypothesis test for correlation
- Hypothesis
- Test statistic
3. Decision rule
- Conclusion
: Compare to a t-distribution with n-2 degrees of freedom
if correlation is positive, conclude that?
the greater the increase in A, the greater the increase in B
describe moderate to weak relationship of r
r is around 0.4-0.5
why do we use regression analysis?
whether and how (cts) variables are related to each other
“Whether” – does the value of one variable have any effects on the values of another?
“How” – as one variable changes, does another tend to increase or decrease?
what data is used in regression analysis?
One continuous response variable (called y - dependent variable, response variable)
One or more continuous explanatory variables (called x - independent variable, explanatory variable, predictor variable, regressor variable)
what regression does
Develops an equation which represents the relationship between the variables.
- Simple linear regression* – straight line relationship between y and x (i.e. one explanatory variable)
- Multiple linear regression* – “straight line” relationship between y and x1, x2, .., xk where we have k explanatory variables
- Non-linear regression* – relationship not a “straight line” (i.e. y is related to some function of x, e.g. log(x))
what is the objective of regression?
Interested in predicting values of Y when X takes on a specific value
model relationship through a linear model
Express random variable Y in terms of random variable X
feature of the population/ true regression line
β0 and β1 are constants to be estimated
εi is a random variable with mean = 0
Yi = β0 + β1xi + εi
response of particular retail spending to a particular value of disposable income will be in two parts – <strong>an expectation (β0+β1x) which reflects the systematic relationship</strong>, and a <strong>discrepancy (εi) which represents all the other many factors</strong> (apart from disposable income) which may affect spending.
what is the residual?
Vertical distance between observed point and fitted line is called the residual.
That is ri=yi-(b0+b1xi)
ri estimates εi, the error variable

how do you determine values of b0+b1 that best fit the data?
choose values of slope and intercept which minimise

describe the residual sum of squares method
Choose our estimates of slope and intercept to give the smallest residual sum of squares
Uses calculus to find estimates
residual sum of squares method
how do you estimate slope and intercept?
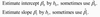
how can we show that residual sum of squares is minimised by solution?
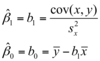
what is a residual?
ri= yi - yhat is a residual
Residuals are observed values of the errors, εi, i=1, 2, …, n.
The error sum of squares is then
The procedure gives the “line of best fit” in the sense that the SSE is minimised