Lecture 5 Descriptive Statistics Flashcards
(46 cards)
What are measures of central tendency include
they are descriptive statistics
mean
median
mode
what is N
number of values
what is the symbol for sum

what is the formula to calculate mean?

how is the mean often written?
The mean is often written as X̄ (“x bar”) — meaning it is the average value of a given variable X.
calculate median
–So, if all values are ranked from 1 to N, the median is the (N+1)/2th value.
–In this case the median is the (25+1)/2th = 13th value: –
what about if the N is odd?
–the median is the average of the two whole numbers either side of this value (e.g., the average of the 12th and 13th values).
what is the mode
value that occurs most frequently
what does the relationship between mean,mode and median depend on
what are distribution of most psychological variables described by?
on the overall distribution of responses.
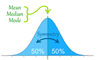
the bell curve
The relationship between measures of central tendency and a response distribution
–When a distribution is skewed the mean, median and mode **will not all be the same. **
–In cases of skew, generally the mean is extremitized in the direction of skew more than the median which is extremitized in the direction of skew more than the mode.
when there is a skew, what is more appropriate statistic to describe central tendency?
why?
the median may be a more appropriate statistic to describe central tendency than the mean
. This is because
(a) the median falls between the mean and mode and (b) the mean can be a very misleading statistic if it differs appreciably from the median or mode.
what does it mean for data to be skewed?
what are two types of skewed data
Data can be “skewed”, meaning it tends to have a long tail on one side or the other:
negative and positive skew
what is a negatively skewed
Because the long “tail” is on the negative side of the peak.
The mean is also on the left of the peak.
distribution is negatively skewed

positively skewed
positive skew is when the long tail is on the positive side of the peak, and some people say it is “skewed to the right”.
The mean is on the right of the peak value.
distribution is positively skewed

normal distribution/ no skew
not skewed.
It is perfectly symmetrical.
And the Mean is exactly at the peak
measures of dispersion
the typical distance of responses from one another.
how tightly clustered are they around the central point?
Measures of dispersion
- Range
The range is simply the difference between the maximum and minimum values.

Measure of dispersion
Mean deviation
average distance of all scores from the mean score

Measures of dispersion
Variation
drawback
drawback: the variance is represented in square units of x, (i.e. x2 )

standard deviation formula
σ = square root (variance)
overcomes the drawback of variance
what does standard of deviation show
if distribution is normally distributed.
but when making statements about samples, the standard deviation will be adjusted by
–sample SD slightly underestimates the SD for the population so an adjustment is required where the SD formula is divided by N-1
standard of deviation formula

statistical inferences
inferential statistics allows us to estimate whether observed diffs between groups are “real” (meaningful) or due to chance.
–We do this by estimating the likelihood of observing the same result purely by chance
Aim of research is to reduce uncertainty to make confident conclusions


