Topics 1-2 Flashcards
1. Estimating Market Risk Measures: An Introduction and Overview 2. Non-parametric Approaches (25 cards)
Geometric return
Assumption is that interim payments are continuously reinvested. Note that this approach ensures that asset price can never be negative.
Some important properties:
- The geometric return implicitly assumes that interim payments are continuously reinvested.
- The geometric return is often more economically meaningful than the arithmetic return, because it ensures that the asset price (or portfolio value) can never become negative regardless of how negative the returns might be. With arithmetic returns, on the other hand, a very low realized return – or a high loss – implies that the asset value P(t) can become negative, and a negative asset price seldom makes economic sense.
- The geometric return is also more convenient. For example, if we are dealing with foreign currency positions, geometric returns will give us results that are independent of the reference currency.
- Similarly, if we are dealing with multiple periods, the geometric return over those periods is the sum of the one-period geometric returns. Arithmetic returns have neither of these convenient properties.
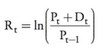
Estimate VaR using a historical simulation approach (formula, how to calculate)
The observation that determines VaR for n observations at the (1 — α ) confidence level would be: (α x n) + 1
Normal VaR
In equation form, the VaR at significance level α is:

Lognormal VaR
The lognormal distribution is right-skewed with positive outliers and bounded below by zero. As a result, the lognormal distribution is commonly used to counter the possibility of negative asset prices (Pt).
The calculation of lognormal VaR (geometric returns) and normal VaR (arithmetic returns) will be similar when we are dealing with short-time periods and practical return estimates.
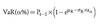
Expected shortfall
A major limitation of the VaR measure is that it does not tell the investor the amount or magnitude of the actual loss. VaR only provides the maximum value we can lose for a given confidence level. The expected shortfall (ES) provides an estimate of the tail loss by averaging the VaRs for increasing confidence levels in the tail. Specifically, the tail mass is divided into n equal slices and the corresponding n — 1 VaRs are computed.
Note that as n increases, the expected shortfall will increase and approach the theoretical true loss.
Coherent risk measures
A more general risk measure than either VaR or ES is known as a coherent risk measure. A coherent risk measure is a weighted average of the quantiles of the loss distribution where the weights are user-specific based on individual risk aversion.
ES (as well as VaR) is a special case of a coherent risk measure. When modeling the ES case, the weighting function is set to [1 / (1 — confidence level)] for all tail losses. All other quantiles will have a weight of zero.
Under expected shortfall estimation, the tail region is divided into equal probability slices and then multiplied by the corresponding quantiles. Under the more general coherent risk measure, the entire distribution is divided into equal probability slices weighted by the more general risk aversion (weighting) function.
This coherent risk measure is more sensitive to the choice of n than expected shortfall, but will converge to the risk measure’s true value for a sufficiently large number of observations. The intuition is that as n increases, the quantiles will be further into the tails where more extreme values of the distribution are located.
Properties of coherent risk measures
Where X and Y represent future values and rho, ρ(.), is the risk measure, a coherent risk measure must meet all four (4) of the following conditions:
- Sub-additivity (the most relevant condition): ρ(X + Y) ≤ ρ(X) + ρ(Y)
- Monotonicity: Y ≥ X → ρ(Y) ≤ ρ(X)
- Positive homogeneity: ρ(λ*X) = λ*ρ(X) for λ > 0
- Translation invariance: ρ(X + c) = ρ(X) – c for some certain amount of n
Both expected shortfall (ES) and value at risk (VaR) are special cases of the general risk measure, however only ES qualifies as a spectral measure; spectral measures are necessarily coherent because (in part) they reflect well-behaved risk-aversion. Expected shortfall is coherent, which implies ES is always sub-additive. Value at risk (VaR) on the other hand, is not a spectral measure: VaR is not always sub-additive (i.e., VaR is only sub-additive if the distribution is elliptical/normal) and therefore VaR is not coherent.
!Non-subadditivity is treacherous because it suggests that diversification might be a bad thing, which would suggest the laughable conclusion that putting all your eggs into one basket might be good risk management practice!

General risk measure
Coherent risk measure is a special case of general risk measure which itself is a weighted average of the quantiles (denoted by qp) of the loss distribution.
Spectral measures are coherent

Evaluate estimators of risk measures by estimating their standard errors
- What happens if we increase the sample size holding all other factors constant? Intuitively, the larger the sample size the smaller the standard error and the narrower the confidence interval.
- Now suppose we increase the bin size, h, holding all else constant. This will increase the probability mass f(q) and reduce p, the probability in the left tail. The standard error will decrease and the confidence interval will again narrow.
- Lastly, suppose that p increases indicating that tail probabilities are more likely. Intuitively, the estimator becomes less precise and standard errors increase, which widens the confidence interval. Note that the expression p(1 — p) will be maximized at p = 0.5
- The quantile-standard-error approach is easy to implement and has some plausibility with large sample sizes. However, it also has weaknesses relative to other methods of assessing the precision of quantile (or VaR) estimators – it relies on asymptotic theory and requires large sample sizes; it can produce imprecise estimators, or wide confidence intervals; it depends on the arbitrary choice of bin width; and the symmetric confidence intervals it produces are misleading for extreme quantiles whose ‘true’ confidence intervals are asymmetric reflected the increasing sparsity of extreme observations as we move further out into the tail.”
- Heavy tails might make ES estimators in general less accurate than VaR estimators. There are grounds to think that such a conclusion might be overly pessimistic.
- The standard error of any estimator of a coherent risk measure will vary from one situation to another, and the best practical advice is to get into the habit of always estimating the standard error whenever one estimates the risk measure itself.
- An alternative approach to the estimation of standard errors for estimators of coherent risk measures is to apply a bootstrap: we bootstrap a large number of estimators from the given distribution function (which might be parametric or non-parametric, e.g., historical); and we estimate the standard error of the sample of bootstrapped estimators.



Quantile-quantile (QQ) plot
The quantile-quantile (QQ) plot is a straightforward way to visually examine if empirical data fits the reference or hypothesized theoretical distribution.
A QQ plot is useful in a number of ways:
- First, if the data are drawn from the reference population, then the QQ plot should be linear. We can therefore use a QQ plot to form a tentative view of the distribution from which our data might be drawn. In this way, a linear QQ plot indicates a good fit to the distribution.
- Second, because a linear transformation in one of the distributions in a QQ plot merely changes the intercept and slope of the QQ plot, we can use the intercept and slope of a linear QQ plot to give us a rough idea of the location and scale parameters of our sample data.
- Third, if the empirical distribution has heavier tails than the reference distribution, the QQ plot will have steeper slopes at its tails, even if the central mass of the empirical observations is approximately linear. A QQ plot where the tails have slopes different than the central mass is therefore suggestive of the empirical distribution having heavier, or thinner, tails than the reference distribution.
Other:
- Like kurtosis, skew CAN be visualized and manifests as an arched pattern.
- We can use the intercept and slope of a linear QQ plot to give us a rough idea of the location and scale parameters of our sample data.
- QQ plot is good for identifying outliers even if the other observations are broadly consistent with the reference distribution
Parametric approaches to estimating VAR
We can think of parametric approaches as fitting curves through the data and then reading off the VaR from the fitted curve.
In making use of a parametric approach, we therefore need to take account of both the statistical distribution and the type of data to which it applies.
Bootstrap historical simulation
- The bootstrap historical simulation is a simple and intuitive estimation procedure. In essence, the bootstrap technique draws a sample from the original data set, records the VaR from that particular sample and “returns” the data. This procedure is repeated over and over and records multiple sample VaRs. Since the data is always “returned” to the data set, this procedure is akin to sampling with replacement. The best VaR estimate from the full data set is the average of all sample VaRs.
- Empirical analysis demonstrates that the bootstrapping technique consistently provides more precise estimates of coherent risk measures than historical simulation on raw data alone.
- A bootstrapped estimate will often be more accurate than a ‘raw’ sample estimate, and bootstraps are also useful for gauging the precision of estimates.
- Perhaps the main limitation of the bootstrap is that standard bootstrap procedures presuppose that observations are independent over time, and they can be unreliable if this assumption does not hold
Describe historical simulation using non-parametric density estimation
- The clear advantage of the traditional historical simulation approach is its simplicity.
- One obvious drawback, however, is that the discreteness of the data does not allow for estimation of VaRs between data points. With n observations, the historical simulation method only allows for n different confidence levels.
- One of the advantages of non-parametric density estimation is that the underlying distribution is free from restrictive assumptions. Therefore, the existing data points can be used to “smooth” the data points to allow for VaR calculation at all confidence levels. The simplest adjustment is to connect the midpoints between successive histogram bars in the original data sets distribution. See Figure for an illustration of this surrogate density function. Notice that by connecting the midpoints, the lower bar “receives” area from the upper bar, which “loses” an equal amount of area. In total, no area is lost, only displaced, so we still have a probability distribution function, just with a modified shape.

Age-weighted Historical Simulation
- The decay parameter, λ, can take on values 0 < λ < 1 where values close to 1 indicate slow decay.
- The implication of the age-weighted simulation is to reduce the impact of ghost effects and older events that may not reoccur. Note that this more general weighting scheme suggests that historical simulation is a special case where λ = 1 (i.e., no decay) over the estimation window.
- This approach is also known as the hybrid approach.
- It generalizes standard historical simulation (HS) because “we can regard traditional HS as a special case with zero decay, or λ →1.
- A suitable choice of lambda (λ) can make the VaR (or ES) estimates more responsive to large loss observations: a large loss event will receive a higher weight than under traditional HS, and the resulting next-day VaR would be higher than it would otherwise have been.
- Age-weighting helps to reduce distortions caused by events that are unlikely to recur, and helps to reduce ghost effects.
- We can modify age-weighting in a way that makes our risk estimates more efficient and effectively eliminates any remaining ghost effects. Age-weighting allows us to let our sample period grow with each new observation, so we never throw potentially valuable information away. So, there would be no ‘jumps’ in our sample resulting from old observations being thrown away.
- However, age-weighting also reduces the effective sample size, other things being equal, and a sequence of major profits or losses can produce major distortions in its implied risk profile.
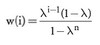
Volatility-weighted Historical Simulation
Another approach is to weight the individual observations by volatility rather than proximity to the current date. The intuition is that if recent volatility has increased, then using historical data will underestimate the current risk level. Similarly, if current volatility is markedly reduced, the impact of older data with higher periods of volatility will overstate the current risk level.
This approach can be combined with the age-weighted approach to increase the sensitivity of risk estimates to large losses, and to reduce the potential for distortions and ghost effects. It can also be combined with order statistics or bootstrap methods to estimate confidence intervals for VaR or ES.
There are several advantages of the volatility-weighted method:
- First, it explicitly incorporates volatility into the estimation procedure in contrast to other historical methods.
- Second, the near-term VaR estimates are likely to be more sensible in light of current market conditions.
- Third, the volatility-adjusted returns allow for VaR estimates that are higher than estimates with the historical data set.
Algorithm:
- Each historical return(t) is replaced by: return(t)*volatility(0)/volatility(t).
- Then conduct typical historical simulation (HS) on adjusted return series

Correlation-weighted Historical Simulation
- This methodology incorporates updated correlations between asset pairs. This procedure is more complicated than the volatility-weighting approach, but it follows the same basic principles.
- Intuitively, the historical correlation (or equivalently variance-covariance) matrix needs to be adjusted to the new information environment.
- The correlation-weighted simulation is an even richer analytical tool than volatility-weighted simulation because it allows for updated variances (volatilities) as well as covariances (correlations).
- If correlation is ρ then the corresponding coorelation matrix for is (Choleski decomposition):
1 0
ρ (1-ρ2)0.5
- To get the evolution of a state vector from then (At-1) to now (At), multiply At x At-1-1
- A-1 = 1/(a11a22-a12a21) x B where B is
a22 -a12
-a21 a11
Filtered Historical Simulation
- The filtered historical simulation is the most comprehensive, and hence most complicated, of the non-parametric estimators. The process combines the historical simulation model with conditional volatility models (like GARCH or asymmetric GARCH). Thus, the method contains both the attractions of the traditional historical simulation approach with the sophistication of models that incorporate changing volatility. In simplified terms, the model is flexible enough to capture conditional volatility and volatility clustering as well as a surprise factor that could have an asymmetric effect on volatility.
- In sum, the filtered historical simulation method uses bootstrapping and combines the traditional historical simulation approach with rich volatility modeling. The results are then sensitive to changing market conditions and can predict losses outside the historical range. From a computational standpoint, this method is very reasonable even for large portfolios, and empirical evidence supports its predictive ability.
- The benefits of this approach are as below.
- enables to combine the non-parametric attractions of HS with a sophisticated (e.g., GARCH) treatment of volatility, and so take account of changing market volatility conditions;
- fast, even for large portfolios;
- allows to get VaR and ES estimates that can exceed the maximum historical loss in the dataset;
- maintains the correlation structure in return data without relying on knowledge of the variance–covariance matrix or the conditional distribution of asset returns;
- can be modified to take account of autocorrelation or past cross-correlations in asset returns;
- can be modified to produce estimates of VaR or ES confidence intervals by combining it with an OS or bootstrap approach to confidence interval estimation;
- there is evidence that FHS works well.
Key steps of the Filtered HS:
- 1st step (VOLATILITY SPECIFICATION): fit a conditional volatility model (e.g., GARCH) to our portfolio-return data.
-
2nd step (TRANLSATE ACTUAL INTO STANDARDIZED RETURNS):
- 2a: use the model to forecast volatility for each of the days in a sample period.
- 2b: These volatility forecasts are then divided into the realized returns to produce a set of standardized returns. These standardized returns should be independently and identically distributed (i.i.d.), and therefore be suitable for HS.
- 3rd step (BOOTSTRAP): “Assuming a 1-day VaR holding period, the third stage involves bootstrapping from our data set of standardized returns: we take a large number of drawings from this data set, which we now treat as a sample, replacing each one after it has been drawn, and multiply each random drawing by the GARCH forecast of tomorrow’s volatility. If we take M drawings, we therefore get M simulated returns, each of which reflects current market conditions because it is scaled by today’s forecast of tomorrow’s volatility.”
- 4th step (COMPUTE VaR): “Finally, each of these simulated returns gives us a possible end-of-tomorrow portfolio value, and a corresponding possible loss, and we take the VaR to be the loss corresponding to our chosen confidence level.”
Filtered historical simulation is a form of semi-parametric bootstrap which aims to combine the benefits of HS with the power and flexibility of conditional volatility models such as GARCH.
Identify advantages and disadvantages of non-parametric estimation methods
Advantages of non-parametric methods include the following:
- Intuitive and often computationally simple (even on a spreadsheet).
- Not hindered by parametric violations of skewness, fat-tails, et cetera.
- Avoids complex variance-covariance matrices and dimension problems.
- Data is often readily available and does not require adjustments (e.g., financial statements adjustments).
- Can accommodate more complex analysis (e.g., by incorporating age-weighting with volatility-weighting).
Disadvantages of non-parametric methods include the following:
- Analysis depends critically on historical data.
- Volatile data periods lead to VaR and ES estimates that are too high.
- Quiet data periods lead to VaR and ES estimates that are too low.
- Difficult to detect structural shifts/regime changes in the data.
- Cannot accommodate plausible large impact events if they did not occur within the sample period.
- Difficult to estimate losses significantly larger than the maximum loss within the data set (historical simulation cannot; volatility-weighting can, to some degree).
- Need sufficient data, which may not be possible for new instruments or markets.
Absolute vs relative VaR
absolute VaR = -µ + σ*α; i.e., worst expected loss relative to the current position (before the mean)
relative VaR = σ*α; i.e., worst expected loss relative to the future (end of period) position
Ghost effects
Ghost effects – we can have a VaR that is unduly high (or low) because of a small cluster of high loss observations, or even just a single high loss, and the measured VaR will continue to be high (or low) until n days or so have passed and the observation has fallen out of the sample period. At that point, the VaR will fall again, but the fall in VaR is only a ghost effect created by the weighting structure and the length of sample period used.
Abrupt change in n-day HS estimate as extreme loss moves from (t-n) to (t-n-1)
Spectral Risk Measure and its features
- An advantage of SRM over ES and VaR is that SRMs are not bound to a single confidence level.
- Spectral risk measures are a promising generalization of expected shortfall. The main advantages are improved smoothness and the intuitive link to risk aversion. If the underlying risk model is simulations-based, the additional calculation effort as opposed to ES seems negligible.
- The weight, w, must be (weakly) increasing over [0,1].
- An increasing weight, w, over [0,1] ensures the SRM is coherent.
- The increasing weight is significant: “This restriction [i.e., weakly increasing weight] also implies that larger losses are taken more seriously than smaller losses and thus the function establishes a relationship to risk aversion. The intuition is that a financial institution is not very risk averse for small losses, which can be absorbed by income, but becomes increasingly risk averse to larger losses.”

Does delta-normal (parametric) absolute VaR always increase with a longer holding period?
While absolute VaR always increases with higher confidence levels, the impact of holding periods is ambiguous because the return (drift) scales linearly with time but volatility scales with square root of time
Component VaR
Component VaR/Portfolio VaR = position weight * beta
