Supervised Learning Flashcards
(102 cards)
Model Evaluation Metrics - Which beta to use(high or low) - Fraud Detection
need a high recall, so need a high beta.
Model Evaluation Metrics - R2
comparing model MSE from basic model MSE. The idea is that the model MSE should be lower than basic model MSE. If so, the ratio is small and 1 - ratio is close to 1.

Ensemble Methods - Introducing Randomness to high variance models before ensembling. Two common options
Bootstrap the data - that is, sampling the data with a replacement and fitting your algorithm to the sampled data.
Subset the features - in each split of a decision tree an ensemble of only a subset of the total possible features are used.
Decision Tree - Entropy - How to turn a bunch of products into sums? To make the probability calculate more manageable.
Take the log of each item and sum everything together

Support Vector Machines - Which equation will help us split the data?

The function that splits the data will be x2 + y2 = 10 (10 being in the middle of 2 and 18)

Decision Trees - Entropy - Confirm how to calculate probabilities of recreating ball sequence

Since you grab the ball, and put it back each time, these are independent events and probabilities are multiplied by each other. *blue on first row should be zero
PyTorch - Batch Size?
Download and load the training data
trainset = datasets.MNIST(‘MNIST_data/’, download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
Each run through the network will use 64 images, then matrix where first column is a flattened vector version of one image
Ensemble Methods - Adaboost hyperparameters
base_estimator: The model utilized for the weak learners (Warning: Don’t forget to import the model that you decide to use for the weak learner).
n_estimators: The maximum number of weak learners used.

Bayes Theorem - Naive Bayes Fip Step. Use example below

Flip the event and conditional.
P(A | B) becomes P(B|A) * P(A). Think in terms of a diagram.

What is feature scaling, two common scalings?
transforming your data into a common range of values. There are two common scalings:
Standardizing
Normalizing
Allows faster converenge, training less sensitive to the scale of features
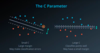
Support Vector Machines - Describe C Parameter
- C hyper-parameter determines how flexible we are willing to be with the points that fall on the wrong side of our dividing boundary
- Constant that attaches itself to classification error
- Large C = forcing your boundary to have fewer errors than when it is a small value. If too large, may not get converence with small error allotment
- Small C = Focus on large margin
Ensemble Methods - Explain Bias
When a model has high bias, this means that means it doesn’t do a good job of bending to the data. An example of an algorithm that usually has high bias is linear regression. Even with completely different datasets, we end up with the same line fit to the data. When models have high bias, this is bad.

Linear Regression - Describe the Square Trick
Its the absolute trick and some. Multiply the distance of the point from the line against the scaled slope and y-intercept. More smart as it gives the line a smarter distance to change to get closer to the point.
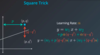

make a prediction, calculate the error, update weights and bias with gradient of error(scaled by learning rate)

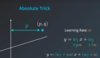
Linear Regression - Describe the absolute trick
Adding values to the slope and y intercept to make the line come closer to points. The value added to the slope should be the horizontal distance(p) and the value added to the y-intercept is arbitrary, but typically use 1. Then, must down scale these added values by a learning rate so the line doesn’t overshoot the point.
Support Vector Machines - Describe Margin Error
norm of the vector W squared. AKA, square all coefficients and sum. You want a small error as this indicates a larger margin.

Support Vector Machines - Describe the Kernel Trick
Transforming data from lower dimensions to higher dimensions in order to split with higher dimensional hyperplane. Then, project back to lower dimensional world with polynomial of certain degree.

Describe Lasso Regularization
Allows for feature selection
Formula squishes certain coefficients to zero, while non zero coefficients inidcate relevancy
use an alpha(lambda) multiplied by sum of the absolute value of each coefficient. Adds this to error
Ensemble Method - Boosting Simple Example
Instead of just taking most common answer, use answers from friends who are well versed in each question. Use answer from philospher friend for philosohy question, use answer from sports friend for sports question etc

Support Vector Machines - Define gamma in terms of sigma
If gamma is large, the sigma is small(curve is narrow). Vice Versa
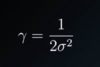
Ensemble Methods - Basic idea of Random Forest
Take Subset of data and build decision tree of these columns. Repeat process with other random subset, then use most popular prediction as the prediction
Model Evaluation Metrics - What is recall


Ensemble Methods - High level what are they and name two popular options
Take a bunch of models and join together to get a better model
Bagging(Bootstrap aggregating) and Boosting

Bayes Theorem - Naive Bayes - Normalize Step
Take conditional probabilities for all events(Spam and Ham), then normalize the values. (each probabilty over the sum of possible probabilities)