general Flashcards
(51 cards)
Does the Random Contraction Algorithm always gives you the minium cut?
No this is a random algorithm. It will return the minimum cut solutions only on average!
What is the complexity of addition of 2 array of n-digits N+N?
It is O(n) or O(logN) where N is the actual value of the number. Indeed the number of digits n is n= is log10(N)
What is the fastest you can be in sorting an array (theoretical bound)?
Nlogn you can never ever get linear time in sorting! So you should love merge sort quick sort etc!
What is the complexity of a simple sorting algorithm? name a few of them
They are all n^2 like insertion bubble sort etc. Merge sort a recursive algorithm is actually a n*logn +n algorithm
High-level description of a partition with linear time and no memory loss (in place)
See image below, go through the swapping in your mind

For an array n what is the maximum number of inversions?
eVERY COUPLE you peek would bein the wrong order with i>j so it is the number of paris (n 2) n(n-1)/2
What is the maximum and the minimum number of edges in a graph connected undirected with no parallel edges?
Minumum is n-1 maximum is n(n-1)/2
What is the worst case time for a random selection algorithm if the pivot is chosen poorly?
It is O(n^2) like for quicksort. The size of the array you re recursing on reduce as n, n-1, n-2 .. and every time you do a partition which is an O(n) algorithm
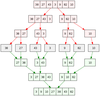
How does merge sort work?
Like QuickSort, Merge Sort is a Divide and Conquer algorithm. It divides input array in two halves, calls itself for the two halves and then merges the two sorted halves. The merge() function is used for merging two halves. The merge(arr, l, m, r) is key process that assumes that arr[l..m] and arr[m+1..r] are sorted and merges the two sorted sub-arrays into one. See following C implementation for details.
MergeSort(arr[], l, r)
If r > l
- Find the middle point to divide the array into two halves: middle m = (l+r)/2
- Call mergeSort for first half: Call mergeSort(arr, l, m)
- Call mergeSort for second half: Call mergeSort(arr, m+1, r)
- Merge the two halves sorted in step 2 and 3: Call merge(arr, l, m, r)
Karatsuba multiplication: simple way to see the formual and a bit of details
it is a n^log_2(3) n^1.6 algorithm compare to the simple quadratic one. Just write x= 10^n/2 a +b y= 10^n/2 c +d and go from there
What is the best case scenario (in the choice of the pivot) in random selection? what is its time?
As usual, you want to reduce the size of the problem. So best case scenario is in balance, split the array in equal sizes sooo… the median
if you do that then each iteration
T(n)<t></t>
<p>note now is T(n/2) not 2*T(n/2) like in quicksort. We only need to look at one sort of the subarray</p>
<p>from master method --><strong> linear time O(n)</strong></p>
</t>
Counting inversions: given array count how many object i,j with i>j not adjiacent!! Speed, use etc
with divide and conquer you can get to n*log(n) (as usual we want to have a almost linear algorithm) This is good for similarities say you rank movies and want to check how much 2 lists are close (zero inversion mean very close.)
High level description of quick sort?

Partition (around a pivot): what is the running time? what about memory
They are linear O(n) and need no memory needed just swap!
What is the complexity of merge sort?
n*logn +n
Quick sort worst and best case behaviour?
n^2 for the worst n logn for best case scenario but on average very close to best behaviours (decomposition principle)
How many different minimum cuts are there in a tree with n nodes (ie. n−1 edges)
Any edge is a minimum cut if you think about it cause every vertex is connected to the graph by one edge
so there are n - 1 minimum cuts.
What is the key of the so called decomposition principle for a randomized algorithm?
- Identify what is the random variable Y you are really interested in
- Express that as a sum of simpler (indicator i.e variables that takes the )
- Apply linearity of expectation E[sum(x)] = sum(E(x)) that works even for dependent variables.
What is the pivot element in quick sort?
It is an element of the array you pick such that all the elements to the left are smaller than the pivot while all the element on the right are bigger (note they are not ordered!)
Also, note the pivot ends up being in the right place (the finally place it will be in the array after sorting)
What is the best way to analyze a recursive algorithm?
Use a recursive tree, find the number of levels (depth) it is usually log(n) at each level j you have 2^j cases that operate on array of size n/2^j then you only have to know the complexity/time of level j (hopefully it is independent of the level)
What is O() of nested loops if for i to n; for j i+1 ..n ?
The same still O(n^2) you just save a factor of 2 or so
Can integers overflow in python?
Short answers: No if the operations are done in pure python, because python integers have arbitrary precision Yes if the operations are done in the pydata stack (numpy/pandas), because they use C-style fixed-precision integers
Results of master method!!
if the recursive time at one step T(n) is < aT(n/b) + O(n^d) i.e the recursive plus the merging step time. Now we have three cases
- 1) a=b^d time is n^d log n
- 3) ad we have O(n d)
- 2) a>b^d here how many recursion is crucial time is n^(log_b(a))
Minimum cut graph random contraction algorithm!
First, Random sampling very efficient for sorting and graph problem.
Pick a random edge uniformly. Fuse the 2 vertexes into one. You can create parallel loops (keep) or self loop(kill them).
Once you get the last 2 vertices that is the cut: the one represented by the vertices fused with 2 vertices.


