MR Chapter 3 Flashcards
(13 cards)
Why R2+ r2+r2
R2 also depends on the correlation between the independent variables
What is the formula for R2
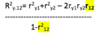
What happens when the IVs do not correlate?
- If the IVs don’t overlap (don’t correlate), then R2 will equal r2+r2.
- When the IVs correlste, ß’s are not equivalent to and are usually smaller than the original r’s. When the IVs are uncorrelated, the ß’s are again equal to the correlations, as in simple regression.

Is R2 less or more than r2+r2?
As a general rule, the R2 will be less than the sum of the squared correlations of the IVs with the DV. (r2+r2). The only time R2= r2+r2 is when the IVs are uncorrelated.
How do you get to predicted scores in SPSS?
When you go ‘save’ -> tick Predicted values: Unstandadised, and then also tick Residuals: Unstandardised.
How can we calculate the residuals?
The residuals are the left over part when we compare the actual minus the predicted grades.
Y = a + bX1 = bX2 + e
Y’ = a + BX1 + BX2
Y-Y’ = e
Another way of thinking about it is residuals are the original DV (grades) with the effects of the IV (pared and HW) removed.
What does optimally weighted mean?
It would not be accurate to just weight the IVS by half, or a logical amount. If you did this, the (explained variance) R2 will not be as high and the unexplained variance, 1 – R2 will be higher.
If the two IVs are optimally weighted, the line is best fitting to the data of all straight lines.
Why is it called least sqaures regression?
The regression weights the IVs so as to minimise the squared residuals, thus least squares.
- If you add up all the residuals, they equal zero.
- Pos and neg cancel out. If you first square them, then add them up, the number is smaller than for any other possible straight line.
Also called OLS (ordinary least squares) regression
What happens if you presume the weighting of variance?
If you logically said that HW explained 75% of the variance in grades, and pared explained 25%, the solution would actually explain slightly less of the variance than the least squares method.
What happens if you have few residuals?
Because the F equation depends on the residuals, the regression is likely to be significant the smaller the residuals. It will be less biased data, and will more strongly represent the population.
Regression Equation = creating a composite?
Is it possible to make a single IV that matches the predicted score?
Yes, instead of weighting HW and Pared by .75 and .25, we could have weighted them by ßs from multiple regression equation to create a composite.
MR provides an optimally weighted composite, a synthetic variable, of the IVs and regresses the DV on this single composite variable.
