lecture 12: pharmacoeconomics of type 2 diabetes treatments Flashcards
What are types of economic evaluation?
- is there good evidence on effectiveness of interventions being compared?
- no: costing study
- yes: is effectiveness of interventions equal?
- yes: costminisation study
- no: can all outcomes be valued in monetary terms (e.g. willingness to pay)?
- yes: cost benefit analysis
- no: can outcomes be measured as quality adjusted life years?
- no: cost-effectiveness analysis
- yes: cost-utility analysis
What is an example of cost-effectiveness analysis?
- cost-effectiveness of lowering blood pressure with a fixed combination of perindopril and indapamide in type 2 diabetes mellitus: an ADVANCE trial-based analysis
- intervention involved use of blood pressure drugs in diabetes
- intervention cost $1350 (over four years)
- intervention group experienced lower hospital and other health care costs ~$800 in savings
- net cost was around $502
- increase in life expectancy 0.05 life years over remaining lifetimes
What is a cost effectiveness plane?
- Y axis = cost of new treatment (more or less costly)
- X axis = effectiveness of new treatment (more or less effectiveness)
- NW: existing treatment dominates
- SW: new treatment less costly, but less effective
- disinvesting
- govts in australia generally don’t work in this quandrant
- NE: new treatment more effective but more costly
- SE: new treatment dominates
- this particular treatment in northeast: $10,040 per life-year gained
- point of origin = placebo group
- most of the action in health economics takes place in the NE quadrant

How do we use QALYs to measure health gain?
- QALY = quality adjusted life year
- Y axis = quality of life scale
- 1 = full health
- 0 = state equivalent to death
- X axis = years
- create health profiles on this QALY scale with and without intervention
- how do you try and capture that?
- can use time to first event
- can use life expectancy: might capture a small change but that change could be a very different experience (one with significantly greater quality of life
- can use sequence/number of events
- can value the events
- integrate under the curve to get QALY difference

Why do economists want to do simulation modelling?
because they want to get QALYs
Why do we need complex diabetes simulation models?
- in chronic diseases like diabetes it takes time (sometimes more than a decade) for treatments to work
- there are many different types of diabetes-related complications (including cardiovascular disease, eye and kidney disease)
- many different factors influence the risk of developing complications (HbA1c (measure of blood glucose exposure); blood pressure; measures of kidney function)
- helps you answer “what ifs”, based on a synthesis of available data
What is a history of diabetes simulation models?
- health economists have been developing simulation models since the Eastman model of the mid 1990s
- need simulation models to evaluate the impact of interventions on the progression of the disease
- many diabetes simulation models have been developed, but tend to have common origins
How do simulation models work?
- many different varieties, but all have common features
- developed from literature or data, regarding what is known about epidemiology and clinical progression of the disease
- a series of health states (often associated with complications) that are important in terms of costs or impacts on quality of life
- risk factors of “treatment effects” that influence the transition to these health states
- capture outcomes in measures such as life-expectancy of QALYs
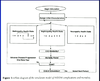
example of model structure:
- begin simulation: assign initial characteristics (population level model?)
- three different states: retinopathy model, neuropathy model, nephropathy model
- model to look at CVD morbidity, mortality,
- cycle round and try to capture the different elements of the disease in the lead up to death
What did George E.P. Box say and what did it mean?
- “all models are wrong but some are useful”
- what we are doing is trying to capture the essence of the disease and hopefully get more signal than noise
What were the UKPDS OM I methods?
- estimate an integrated set of parametric proportional hazard models using UKPDS data
- these predict absolute risk of furst occurrence of 7 major diabetes-related complications, based on:
- patients’ characteristics (e.g. age and sex)
- time varying risk factors (e.g. HbA1c)
- patients start with specified health status and can have one or more non-fatal complications or die in many model cycle
- result - a “probabilistic discrete-time model” with annual cycles
summary of model equations
- each box is a health state for representing different aspects of diabetes e.g. ischaemic heart disease (non-acute), myocardial infarction, heart failure, stroke,
- under this is a bunch of characteristics with known hazard ratios that affect your chance of getting that particular disease state
- how your relative risk changes
- e.g. in IHD each year of age adds about a 3% increased risk
- but in high glucose expsure your risk increases about 13%
- so a 1% change in HBA1c is equivalent to a person being about 4 years older
- potentially having one health state means you have a higher chance of getting another e..g. heart failure contributes a 5fold increase risk in MI and almost 6 fold risk of stroke → heart failure itself doesn’t kill you but its conferred risk to other disease states does

Why do we ‘link’ the equations?
- Jonathon Brown has noted that: “the difficulty is not just there are so many potential events, but the occurrence of one event substantially increases the likelihood of the other events… under these circumstances it can be catastrophically inaccurate to simulate each kind of event as if it were statistically independent”
What is an algorithm of model process?
- start: define the following characteristics for each patient in the simulation:
- age at diagnosis
- ethnicity
- sex
- BMI
- HbA1c
- total: HDL
- blood pressure
- smoking status
- atrial fibrillation at diagnosis
- peripheral vascular disease (PVD) at diagnosis
- history of diabetes-related events
- ischaemic heart disease (IHD)
- congestive heart failure
- blindness
- amputation
- renal failure
- MI
- stroke
- commence yearly model cycle
- randomly order and run event equations
- dead? yes/no
- if yes calculate life years and QALYs
- if no update patient risk factors using risk factor equations, update history of diabetes-related events
- repeat

What is an example of model process?
- patient at year 1:
- white male, 65 years of age (diabetes diagnosed at 60), BMI of 33, HbA1c of 7.6%.. Total/HDL of 5.6%, BP 143mmHg, smoker, no atrial fibrillation and no PVD at diagnosis
- no history of diabetes-related events
- commence model cycle 1
- random order of event equations
- Probability is calculated and compared to a random number: if the random number is greater than the probability assume the event didn’t happen and vice versa
- is the patient dead? no
- upate patient risk factors usuing equations
- patient at year 2:
- white male; 66 years of age (diabetes diagnosed at 60); BMI of 33; HbA1c of 9.9%, Total/HDL of 5.5%; BP 164mmHgm; smoker, no atrial fibrillation and no PVD at diagnoses, CHF developed in year 1
- model cycle 2
- died
- calculation of benefit measures: life years: 1 + 0.5 years = 1.5, QALYs: 0.677 + 0.311 = 0.988
Why create models?
- in diseass like diabetes other factors can take a long time to appear
- e.g. first major RCT in Type 2 diabetes
- intensive vs conventional blood glucose control - 1% difference in effect
- very long term follow-up (median 10.3 years)
- produced big changes in weight (higher weight with more intesive treatment
- at the end of the follow-up: no difference in death rate until about year 9
- P value not really significant
- over time the curves continued to separate but it wasn’t until about 25 years that you could see change in rate of mortality
What is seen when simulating lifetime outcomes?
- gains in intensive blood glucose therapy
- 1/3 QALY over time
- made predictions with simulation model based what was seen in the trial

What were cost-utility results (circa 2005)?

- intensive blood glucose control with sulphonylurea/insulin 6000 pounds per QALY
- blood pressure intervention that gave slightly greater effects and was cheaper (tight blood pressure control 370 pounds per QALY)
- metformin: intensive blood glucose control where it was actually greater effects and lower costs (SE quadrant)
What was seen in a more recent study?
- look AHEAD study
- intensive lifestyle intervention for people with Type 2 diabetes with BMI greater than 25 (average BMI was over 35)
- had a large effect on some risk factors which continued over 10 year follow-up
- dramatic effect on waist circumference, weight
- glycated haemoglobin
- effects on CVD was zero
- unfortunately no effect on hard outcomes
- primary outcome:
- death from CVD;
- nonfatal myocardial infarction; stroke, angina
- could we have predicted this outcome?
How can we adapt diabetes simulation models for different populations?
- cost-utility analysis of liraglutide versus glimepiride as add-on to metformin in type 2 diabetes patients in china
- already evaluations in asia are using off-the-shelf computer simulation models to undertake evalutions
- how should we adapt them?
What are differences in the cost of drugs?
- Atorvastatin
- australia: current $52; $38 wholesale price
- prices on 1 december $19.32
- new zealand: ~$2
- england: ~$3
- australia: current $52; $38 wholesale price
- clearly some issues between healthcare systems
How may intervention costs vary?
- good example are generic drug prices
- seems to be significant variation within Asia:
- PSS lists the price of Atorvastatin (40mg) $SG3.08 - $8.25 per tablet
- philippines $US 0.40
- as a tax payer might feel slightly ripped off, might make different decisions
- lets use drugs differently, ration them

What are cost savings?
- high proportion of health costs of type 2 diabetes are due to complications
- make-up of the complication costs differs across regions
- basically 80% of health care costs are these limited number of complications
- if you can prevent these complications potentially you can have big offsets
- in different regions of the world things can cost different amounts

Is quality of life consistent across populations?
- considerable regional variation when responding to quality of life questions
- asian populations consistently report less problems
- cannot be explained by demographic or clinical differences
- depending on your culture you tend to respond reasonably differently to these questions

What impact could this make?
- recent work by Hayes using ADVANCE data suggest that changes in utilities do NOT vary by region



