Hypothesis Testing Flashcards
(10 cards)
hypothesis tests
A hypothesis test is a formal procedure for comparing observed data with a claim (also called a hypothesis) whose truth we want to assess vs. a contradictory claim (hypothesis)
- Confidence intervals are appropriate when our goal is to estimate a population parameter
- But when your goal is to assess the evidence provided by data about some claim concerning a population, then hypothesis tests (or tests of significance) are the appropriate statistical method to use
- A statistical hypothesis is a claim about the value(s) of a single parameter or several parameters or about the form of an entire probability distribution
null hypothesis and alternate hypothesis
The alternative hypothesis (HA) is usually the hypothesis that the researcher would like to prove is true – Can be “two-sided” or “one-sided”
The null hypothesis (H0) is the opposite to the alternative hypothesis and is the hypothesis of no change (from current opinion), no difference, no improvement, etc.
– The null hypothesis, denoted by H0 , is the claim that is initially assumed to be true and the alternate hypothesis, denoted by HA , is the assertion that is contradictory to H0
– If sample evidence suggests H0 is false, we reject H0
– If the sample evidence does not strongly contradict H0 , then we fail to reject H0
general procedure for hypothesis tests
The basic steps for hypothesis testing are:
- State a null and alternative hypothesis, H0 vs. HA
- Collect data and calculate the test statistic
- Determine the P-value associated with the test statistic
- Reach a decision/conclusion based on the P-value: reject or fail to reject H0
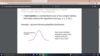
test statistic
a test statistic is a standardized score of our sample statistic, that helps conduct the hypothesis test
example: assume normal probability distribution
how many standard deviations away is the statistic from the mean if H0 is true?
P-value
A P-value is the probability (computed assuming that H0 is true) of obtaining a value of the sample statistic that is at least as extreme or more extreme (as defined by the alternative hypothesis) as the value actually observed
use the magnitude of the P-value as a measure of the strength of evidence against the null hypothesis
- large P-values fail to give convincing evidence against H0, because they say that the observed result could have occurred by chance if H0 were true
- small P-values are evidence against H0, because they say that the observed result is unlikely to occur when H0 is true (i.e., we observed something rare by chance or the null hypothesis is not correct)

statistically significant
“Statistically significant” is an adjective used to describe a sample that seems too unlikely to have occurred just by chance alone
example: researcher compares mean weight loss for a diet treatment to that for an exercise treatment, and reports a P-value of 0.036. She concludes these sample data are “statistically significant”.
But, we never know whether the null hypothesis is true or not, nor does the P-value tell us why we observed the sample we did
at most only one type of error is possible at a time

power of the test
The power of the test is the probability of rejecting H0 , when H0 is false; it measures the ability of a hypothesis test to find evidence against a null hypothesis that is actually incorrect
power is influenced by:
- # of observations in the sample
- the magnitude of the effect size to be detected
just because we fail to find strong evidenve against the null hypothesis doesn’t mean it’s true
effect size
The effect size (magnitude of effect) is the magnitude of the difference between groups or deviation from expected null value
example: a completely randomized experiment compares a current insomnia treatment to a newly developed treatment. researchers observe a statistically significant increase in mean hours slept for the new treatment (P-value = 0.002)
“statistically significant” does not necessarily imply “practical” significance
multiple comparisons
Multiple comparisons: Conducting multiple hypothesis tests increases the likelihood of type I error
– Rare statistics are unlikely to occur in a single sample, but more likely to occur in repeated sampling
– Multiple tests is analogous to repeated sampling
researchers conducting multiple comparisons should control for overall type 1 error rate
take home message
don’t fall victim to (nor contribute to) the misunderstanding of P-values and “significance”
we never know if a hypothesis is true or not
the results of a hypothesis test depend on:
- study design
- sample size
- effect size (magnitude effect)
- power
- number of comparisons
