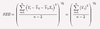Quantitative Methods Flashcards
(195 cards)
In linear regression what is the confidence interval for the Y value
CI = Y +/- (tcritical) x (SE forecast)
What does the t-test evaluate
Statistical significance of an individual parameter in the regression
What does the F-test evaluate
The effectiveness of the complete model to explain Y
Is the dependent variable X or Y in a linear regression
Y
Explain what it means to say a “critical t-stat is distributed with n-k-1 degrees of freedom”
This is the t value that is compared with the measurements of the data.
The t-critical is taken from the standard table for the n and significance level.
What expression does the line of best fit for a linear regression minimise
Sum of the squared errors between Y theoretical and Y estimated.
What is the SSE of a linear regression
Sum of the squared residuals
Sum of the squared errors between Y theoretical and Y estimated.
What is the first of six classic normal linear regression assumptions, concerning parameter independence
- The relationship between Y and X is linear for the parameters and:
(1a) -the parameters are not raised to powers other than 1 and
(1b) - are parameters are separate and not functions of other parameters. - X can be powers other than 1
What is the second of six classic normal linear regression assumptions, concerning X, the independent variable
X is NOT RANDOM
X is not correlated with the Residuals
(note that Y can be correlated with the residuals)
Describe the relationship between “total variation of dependent variable” and “explained variation of dependent variable”
It is the change in observed value of Y for a change in value of X
Vis a vis the
Expected change in Y given the regression model
Explain covariance X and Y
Its the sum of the cross products of the difference from the mean of X and Y
Divided by n-1
Cov(X,Y)=(X-Xmean)(Y-Ymean)/(n-1)
What is the correlation coefficient of X,Y
Its the Cov(X,Y) divided by the product of sqrt(sum deviations of X from X_mean) and sqrt(sum deviations of Y from Y_mean)
For the error term of a linear regression what are the assumptions concerning correlation and variance
- Errors are uncorrelated
- Variance is the same for any observation
What 3 criteria must be satisfied for sample correlation coefficient to be valid
- Mean and Variance of X and Y are finite and constant
- The covariance between X and Y is finite and constant
Re Correl=cov(X,Y)/(sX.sY)
What is the t-staristic compared with?
How is it calculated
t statistic is compared with t-critical from tables
t-stat =
(b1 measured - value of b1 theoretical given null hypothesis) / (SE of b1 measured)
When b1 theoretical = 0 t=(b1_est / SE b1_est)
What is the similarity of an F-test with a t test in a simple regression
F-test = t-test of the slope coefficient
Define “dependent variable”
The variable Y whose variation is explained by the independent variable, X.
Give three other names for the dependent variable.
Explained variable
Endogenous variable
Predicted variable
Define the “Independant variable”
The variable used to explain the dependent variable.
Give three other names for the Independent variable.
Explanatory variable
Exogenous variable
Predicting variable
What is the second of six classic normal linear regression assumptions, concerning the Independent variable and the residuals
The independent variable X is uncorrelated with the residuals
(note Y can be correlated with the residuals)
X must not be random
What is the third of six classic normal linear regression assumptions, concerning the expected value of the residual
The expected value of the residual=zero
[E(ε) = 0].
What is the fourth of six classic normal linear regression assumptions, concerning the variance of the residual
The variance of the residual is constant for all values of residual
Homoskedasticity.
NO HETEROSKEDASTICITY .e.g where residuals change and get more or less noisy
What is the fifth of six classic normal linear regression assumptions, concerning the distribution of residual values
The Residuals are not correlated with each other (this means they are independently distributed)
e.g. NO SERIEL CORRELATION