Natural Language Processing Flashcards
(57 cards)
1
Q
NLP method summary
A
- find data: instead of spending months on unsupervised machine learning, take a couple weeks to label data
-
clean data (CTWMLL):
- irrelevant Characters
- Tokenize by separating into individual words
- irrelevant Words (such as twitter mentions or urls)
- consider Misspelled
- Lowercase
- consider Lemmatization
- find good data representation: i.e. - bag of words
- classification: stick with simplest for needs (I.e - logistic regression)
- inspection: confusion matrix
-
leveraging semantics
- method like Word2Vec (maybe average sentence representations)
- lose explainability, thus we should use tools like LIME
- end-to-end syntax: use convolutions or transformers where order matters
2
Q
term-document
A
- bag of words method
- n-terms by m-documents
- raw word count
- binary: 1 if the word appears in document else 0
- word frequency: 100*(raw count)/(total count)
- TF-IDF
3
Q
term frequency–inverse document frequency (TF-IDF)
A
- increases proportionally to the number of times a word appears in the document and is offset by the number of OTHER documents in the corpus that contain the word
- idf = log(N/{d∈D:t∈d}), denominator is number of documents with term
- shape V x D
4
Q
problem with wordcount
A
- stopwords like “the” occur in all documents
- really long documents have really big eigenvalues
5
Q
lemmatization
A
- determining the lemma of a word based on its intended meaning
- depends on correctly identifying the intended part of speech and meaning of a word in a sentence
- more accurate than stemming
6
Q
main areas of NLP
A
- sentiment analysis: determine writer’s positive, negative, or neutral feelings towards a particular topic, product
- named entity recognition: breaks sentences into names, organizations, etc…
- part of speech tag: label the noun, pronoun, adjective, determiner, verb, adverb, preposition, conjunction, and interjection (i.e. use vertirbi)
- latent semantic analysis: use methods like PCA get representation in a smaller domain (embeddings)
7
Q
word embedding
A
- equates to mapping of words
- can use GloVe or Word2Vec into new net
- can perform word analogy on these words
- idx is the word2idx position
- word along row, document along column
- latent feature D, We=V x D, D << N
- autoencoders/PCA/SVD create embedding
8
Q
cosine distance
A
- find similtude between two vectors
- used instead of euclidean distance for words
- cos_dist = 1 - aTb/(||a|| ||b||)
- aTb = ||a|| ||b|| cos(a,b)
9
Q
one hot encoding
A
- s = [0, 0, …, 1, …, 0] (1 x V)
- x = sWe
- the input returns row of encoded vector
- significantly reduces data size
- X is an index instead of a matrix
10
Q
t-SNE
A
- t-distributed stochastic neighbor embedding
- non-linear; no transformation model (modifies output itself)
- no train and test set
- no transforming after fitting
11
Q
n-gram models
A
- a sequence of consecutive words
- bigram: use past as inputs p(w|w_n-1)
- trigrams: use past and future words as inputs p(w|w_n-1, w_n+1)
12
Q
chain rule of probability
A
- apply bayes rule again and again: p(A, B, C, D)=p(D|C)p(C|B)p(B|A)p(A)
- p(A) = word count / corpus length
- p(B|A) is part of the bigram model
- p(C|A, B) is trigram: count(A, B, C) / count(A, B)
13
Q
markov assumption
A
- current state only relies on previous state
- 1st order Markov: condition on 1 word (bigram)
- this is typically what we consider markov model
- 2nd order Markov: condition on 2 words (trigram)
14
Q
recursive neural tensor network (RNTN)
A
method for state of the art sentiment analyzer
15
Q
training sentence generator
A
- tokenize each sentence
- map word to index
- save each sentence as a list of indices
- INPUT: [START, x0, x1, …, xN]
- TARGET: [x0, x1, …, xN, END]
- accuracy is number of words guessed correct out of all of the number of words
16
Q
how to calculate probability of word sequence
A
- chain rule
- log likelihood to deal with small numbers
- random note: reverses softmax operation
- normalize the make all make comparable
- T-1log p(w1, … wn)=T-1[log p(w1)+∑log p(wt|wt-1)]
17
Q
Word2Vec
A
- is an extension of the bigram model
- y = softmax(W1W2x)
- W1W2 = V x V matrix like markov matrix
- ROW is probabilities of next word
- 2 parameters instead of 1 (Wx) makes smaller
- word drop threshold: p = 1 - np.sqrt(threshold/p_unigram)
18
Q
continuous bag of words (CBOW)
A
- list of words to predict word in the middle
- context size refers to the number of words surrounding
- brown fox jump over the
- some authors call 2 (or 4)
- this number is usually between 5 and 10 on either side
- there are better models than this
- approximating softmax is heirarchical softmax
19
Q
heirarchical softmax
A
- dealing with low probability words
- form a tree
- decide which branch using sigmoid as probability
- other branch is 1 - sigmoid
- multiply along path using chain rule
- frequent words closer to the top
20
Q
negative sampling
A
- the other solution to low probability of being correct
- using 5-25 negative samples (optimize though)
- input words: jump
- target words: brown fox over the
- negative samples: apple orange boat tokyo
- J = ∑logσ(W(2)cTW(1)in)+∑log[1-W(2)nTW(1)in]
- c = context
- n = negative samples
- raw form (what we use): J = ∑tnlogpn+(1-tn)log(1-pn)
- ∂J/∂W(2)=HT(P-T)
- H size 1 x D (as opposed to usual N x D)
21
Q
negative sampling updates
A

22
Q
multiclass versus binary classification
A
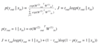
23
Q
GloVe versus Word2Vec
A
- Word2Vec is predictor
- GloVe is a word count method
- both perform similarly
- GloVe is much more efficient
24
Q
matrix factorization update equations
A

25
HMMs for POS tagging
1. find the probabilities
1. for observation: p(walk|verb)
2. for state transition: p(noun|verb)
2. use vertirbi to match a sequence of words to an unknown sequence
26
HMM POS tag model

27
named entity recognition (NER)
* similar to POS but with entities
* TRAINING THE SAME!!
* nouns: person company, location
* very imbalanced (~90%)
* using capatializing is cheating!
28
recursive neural network (RNN)
* don't need a bunch of trees with recursion
* uses linear: hj=f(WTx+b)=
* linear discrimination analysis
* 2 Gaussian w/ same covariance
* x = w1=word embedding for w1
* h1=f(Wleftxleft+Wrightxright+b)
* W = R x D x D
* binary R=2, can be N-ary
29
recursive neural tensor network (RNTN)
* h = f(WTx + b), W (2D x D)
* uses quadratic: hj'=f(xTAjx+WjTx+b), A (D x 2D x D)
* quadratic linear discrimination
* 2 Gaussian w/ diff covariance
* hj'=f(xLTALLxL+xLTALRxR+xRTARRxR+WLTxL+WRTxR+b)
* lists: words, left children, right children
*
30
parse tree

31
sentiment analysis trees
* parse by good and bad
* can catch the dependency
* "this is kind of bad, but overall it is good"
32
recursive nn to RNN
1. put children on left side
2. store relations array
3. -1 goes wherever there is not word
* 3 arrays to store trees
* parent: where to find parent node
* relations: how a child is related to a parent
* words: words associated? & index
* post order traversal: parent comes after children
33
CNN for NLP

34
sequence-to-sequence
* len(output) ≠ len(input)
* encoder
* no output
* encoding: only keep final state (h and c)
* decoder
* encoder h(Tx) = decoder s(0)
* start with 'START' tag as x1
* teacher forcing for training
35
different techniques for language model
1. text generation: sample randomly
2. machine translation: take argmax
36
seq2seq architecture

37
attentions vs seq2seq
* attention
* set s(0) = 0
* all of hidden states are stored
* determine which one we care most about
38
attention
* attention weights
* αt'=*N*([st-1,ht']), t' = 1, ..., Tx
* copy s(t-1) and concat for each step
* t' is for input sequence t' = 1, ..., Tx
* t is for output sequence t = 1, ..., Ty
* context = ∑α(t')h(t')
* teacher forcing
* training: concat context and target
* prediction: concat context and previous word
* each relies on previous state
39
attention model

40
attention update model

41
visualizing attention
1. each time step requires context vector, Tx
2. each context step requires an attention weight, Ty
3. plot TxTy as an image
4. should follow a somewhat linear pattern
42
memory network
* parts 1) story, 2) questions, 3) answer
* single supporting fact, 2 supporting, etc...
* only produces single output
* for 2-support, pass "hop"
* replaces question embedding
* reuse embedding for second hop creation of weights
* can add dense layer after hop
* everytime it reads the story it learns something new
43
memory network steps
Find part of story, then find relevant part of sentence
1. sum word vectors for sentences
2. sum word vectors for question
3. dot story with the question = story weights
* softmax
* ~=represent important sentence
4. dot story weights back with stories (softmax)
1. output is V (vocab size)
44
memory network architecture

45
automating text analysis
* dictionaries: word count of psych. terms
* co-occurance: compare distances
* feature extraction:
* expressions
* ngram
* syntax
* POS
46
latent semantic analysis (LSA)
* measure the distance to some target document
* measure similarity to pregraded documents (analogies)
* can lead to similar results as a human grader
47
latent dirichlet allocation (LDA)
* find the topic that generates the given collection of documents
* relies on statistical dependence among words
* unlike LSA, topic have meaning
* semi-supervised: create topics related to different moral concerns
48
cohesion
* examines how a writer writes
* structural and lexical properties
* lexical: relating to words or vocabulary
* linguistic features
* lexical diversity
* semantic overlap
* connections b/w propositions
* causal links
* syntactic complexity
49
knowledge base method

50
entity linking
1. remove POS: verb, adverb, adjective, pronoun, determiner and predisposition
2. properties: keep office, role, etc.. entities, discard rest
3. remove those with ρ \< 0.1
4. merge abstract and properties
5. filter out words not related to morality
6. cosine similarity b/w feature and word in BK
7. threshold 0.6 regarded word as occurance of feature
51
bidirectional encoder representation from transformers (BERT)
* reads entire sequence of words at once
* masked LM: predict masked word
* loss calculated on 15% of tokens replaced with mask
* repredict the masked tokens
* next sentence prediction
* tokens at beginning and ends of sentence
* sentence embeddings
* position embedding
* loss calculated as subsequent sentence
52
masked LM architecture

53
next sentence prediction

54
NLP tests
1. **Google sensibleness and specificity average**: measure whether text makes sense in current context
2. **Winogrande**: 44,000 size dataset to determine common sense with human
1. humans = 94%, machine ~80%
3. **Rogue**: a proxy for how well the generated summary exactly matches the unigrams and bigrams in a reference summary
4. **WikiText-103**: perplexity
5. **LAMBADA:** next word prediction accuracy
55
generative model
* finish sentence
* answer questions
* summarize content
56
biggest networks (Feb 2020)
1. Turing-NLG (Microsoft): 17 billion parameters
2. MegatronLM (NVidia): 8.3 billion
3. GPT-2 (OpenAI): 1.5 billion
4. Grover-Mega (U of W): 1.5 billion
5. ElMo (AI2): 465 million
6. RoBERTa (Facebook): 355 million
7. BERT large (Google): 340 million
57
biggest network training data
1. T-NLG
1. trained on 100k direct answers
2. finetuned multitasked fashion all public summarization datasets (~4 million training instances)
2. GPT-2: 40GB of data
3. Google Mina: 341 GB social media chatter
