Language Flashcards
(51 cards)
What are the building blocks of language? (state)
Words
Phonemes (sound units)
Morphemes (smallest units of language)
Syllables (rhythmic units)
Stress (relative emphasis of syllables)
Words (language building blocks)
Representations stored in mental lexicon:
- catalogue of words - mental dictionary
- average person has 40,000-50,000 words
- ML contains spelling, pronunciation, meaning, grammar category
Phonemes (language building blocks)
- sound units of language - smallest units of speech that allow word discrimination
- ~100 phonemes across world - ~40 in English
- words not monolithic units of info - there are subcomponents
- Spoonerisms (William Spooner)
- in toast the the queen: ‘queer old dean’ not ‘dear old queen’
- shows you can replace sound units
- phonemes are cognitively real
- Kuhl et al., (1992) - infants can distinguish between most phonemes
- tune in to native language by age 1
Morphemes (language building blocks)
- Smallest units that carry meaning
- ’s’, ‘ing’, ‘ly’, ‘ness’, ‘er’
- words can be morphologically complex or simple
- complex = has multiple morphemes
- morphological overlap (share morpheme)
- will be faster to recognise the second
- stored in ML somewhere?
- morphological stranding = speech error where morphemes stay in the same place even if words swap
- ‘a geek for books’ –> ‘a book for geeks’
Syllables (language building blocks)
- rhythmic units - one vowel with or without surrounding consonants
- expletive infixiation rule
- can only insert expletive if there is a certain syllabic structure
- ‘fan-fucking-tastic’
- McCarthy (1982) - multiple syllables, word has main stress preceded by secondary stress
Stress (language building blocks)
- relative emphasis of certain syllables - can alter meaning (CON-tent vs con-TENT)
- Cappa et al., (1997) - aphasic CV
- can produce individual phonemes but the stress is wrong
- produces speech errors when stress fell on wrong syllables
- dissociates phonemes from stress
Cognitive neuroscience of language:
- Broca’s area
- Wernicke’s area
Broca (1824-1880)
- impaired language production, relatively intact comprehension (patient Tan)
- left inferior frontal gyrus
Wernicke (1848-1905)
- fluent (but disordered) production, impaired comprehenaion
- left posterial temporal lobe
Classical language model
- Wernicke-Geschwind model
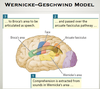
Proposed by Wernicke (1874), extended by Geschwind (1970)
spoken word –> area 41 (auditory cortex) –> Wernicke’s area –> hear + comprehend word
cognition –> Wernicke’s area –> Broca’s area –> facial area of motor cortex –> cranial nerves –> speak
written word –> area 17 (V1) –> areas 18+19 (V2) –> area 39 (angular gyrus) –> Wernicke’s area –> read
(NB: typically left-lateralised)

Current views of language model
(neurobiological architecture)
Commonly activated regions:
- left inferior frontal gyrus (Broca’s area)
- superior, medial, inferior temporal gyri (L+R)
- frontal regions in L hemisphere
White-matter tracts:
- arcuate fasiculus –> links temporal + frontal regions (dorsal stream)
- sound –> articulatory representations
- L more prominent
- extreme capsule –> links frontal to temporal regions (ventral stream)
- speech –> conceptual representations
- Hickok & Poeppel, 2004
- some degree of bidirectionality in D+V streams
Vigneau et al., (2006) - meta-analysis of 128 imaging studies
- prominent L frontotemporal network (also significant R hemisphere involvement)
- highly interconnected regions - LH dominant but RH too
- different parts of network activated based on task + input modality
- phonological clusters, semantic clusters, sentence clusters
- all partially overlapping
- no strict modularity - interactions are key
Properties of written language
- writing systems
- role of regularity
Writing systems:
- logographic = unique symbol per word/morpheme (Chinese)
- syllabic = symbol for syllable (Japanese)
- alphabetic = unique unit for each phoneme (english)
- Dehaene (2009) –> diverse but all share visual features
- recurring shapes, contrasting contours, average of 3 strokes per character
Role of regularity
- Deep orthography (English/Hebrew)
- letters/groups of letters have different sounds in different contexts
- Shallow orthography (Finnish/Spanish)
- consistent correspondence between letters and phonemes
Visual word recognition process:
- Process
- state components
Process:
- extract from visual input
- letter recognition
- orthographic lexicon AND/OR grapheme –> phoneme conversion
Components:
- Eye movements
- Letter recognition
- Orthographic lexicon
- Grapheme –> phoneme conversion
Eye movements (visual word recognition)
- fixation and saccades
- fixation brings text into foveal vision
- high concentration of photoreceptors
- average fixation = 200-250ms
- average saccase length = 8 letter hop
- 10-15% of time they move backwards
- fixation brings text into foveal vision
Letter recognition (visual word recognition)
- recognise visual characteristics THEN identify
- Miozzo & Carmazza (1998) - alexic patient RV
- fine with visual characteristics
- impaired at identifying words
- alexic patients with lesions in L posterior regions - issue with identity
- Visual word form area (L fusiform gyrus)
- extracts identity of letter string
- regardless of size/shape/position/language
- Dehaene et al., (2001): visual priming
- if prime with target word - reaction time decreases
- subconscious early processing (implicit memory)
Orthographic lexicon (visual word recognition)
stores representation of spelling
- activated when we read a familiar word
- then obtain meaning from semantic systems
Grapheme to phoneme conversion (visual word recognition)
When reading novel words or pseudowords –> need to assemble the pronunciation from its letters
- suggests word-processing models need partially distinctive mechanisms for regular vs irregular vs pseudowords
Dual-route model of written language processing
- Coltheart et al., (2001)
- evidence for separate systems
- problems
Lexical route
- faster for words
- frequency-weighted
- faster for regular words
Non-lexical route
- faster for pseudowords and irregular words
- assemble from letters and rules
- if issue: problem with assembly
- so retrieve closes real world word instead
Evidence for separate:
- Patterson (1982) - AM –> problems with pseudowords
- lexicalisation –> read it like closest legical item
- 83-95% accuracy on normal words
- 0-37% accuracy on pseudowords
- Shallice et al., (1983) - HTR –> problems with irregular words
- surface dyslexia
- 79% accuracy on regular, 84% on pseudo, 48% on irregular
PROBLEM:
- DRC fully hardwired –> can’t learn new rules (for non-lexical)
- focus on English
- doesn’t explain HOW implemented in brain
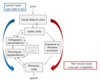
Triangle models (written word processing)
- overview
- pseudowords
- irregular words
- experimental data
Seidenberg & McClelland (1989); Harm & Seidenberg (2004)
- orthography (letters); meaning (semantic units); phonology (sounds)
- visual input –> O –> M/P
- P –> output
- same mechanism for words + pseudowords; irregular words + regular words
- system picks up correspondences between specific orthographic units and phonological units
- strong connections between units more often co-activated
Pseudowords –> O + P (no M because not real) –> if P damaged, need to rely on O-M correspondence –> so lexicalisation
Irregular words –> O + M (no P because irregular) –> if O damaged, need to reply on P-M (phonology) - so regularisation
BUT: focus on English AND doesn’t explain HOW implemented in brain
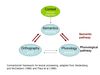
Written word processing in the brain
Marinkovic et al., (2003): MEG
- activation starts in occipital lobe, spreads temporally
- occipital-temporal junction
- spreads temporally down ventral route (meaning) + frontal (top-down processing)
Dehaene et al., (2009):
- ventral stream:
- frontotemporal network (meaning)
- bidirectional (top-down, bottom-up)
- frontotemporal network (meaning)
- dorsal stream:
- occipital –> parietal –> articulation/pronunciation
- occipital lobe activation - low-level processing visual input
- VWFA - binds lower-level processing to language network
Neuronal recycling hypothesis
Dehaene et al., (2009)
- really high correlation between naturally-occuring image fragments + their frequency of occurence in written symbols
- maybe we use visual image processing for language
- reading co-opted evolutionarily-older brain functions - for visual object processing
- explains why symbols are what they are
- explains why we’re so good at reading even though evolutionarily new
Properties of spoken language
- problems to solve
- speech recognition - extracting invariant representations from continuous variable input
- speech signal = continuous, distributed in time, fast-fading and variable (IDs)
- word-segmentation problem - where do words start + end
- word co-articulation problem - blending of sounds from one word to the next
- child’s paradox - how do children separate words if they don’t know them
Major elements of speech recognition (state them)
- word segmentation
- lexical selection
- access to meaning
- context effects
Word segmentation (speech recognition)
- MSS
- evidence
- evaluation
- Cutler & Norris (1988) - metrical segmentation strategy
- stressed syllables at onset of words
- continuous speech segmented at stress syllables
- stressed syllables more likely to be content words (have full vowels)
- unstressed syllables more likely to be grammatical words
- Cutler & Carter (1987) - evidence supporting MSS:
- English syllable distribution
- 3/4 of time: stressed = content, unstresses = grammatical
Evaluation:
- not infallible - just a strategy
- need other sources of info to supplement
- language-specific
- solves child’s paradox
Lexical selection (speech recognition)
- shadowing paradigm
- gating paradigm
- cohorts
- salience of onset
- late activation
- Searching process - determine best fit between input + lexical representations
- fast - words in context can be recognised 175-200ms from onset (only part of content presented)
- Marslen-Wilson (1975) - shadowing paradigm
- hear sentence + repeat
- sentence has some mispronunciations
- people correct when repeating even before full presentation
- not just representation
- Tyler & Wessels (1983) - gating paradigm
- presented with parts of a word - get progressively longer
- decreasing cohorts of possible endings as word gets longer
- uniqueness point = point at which the word can be disambiguated from all others in the cohort
- Marslen-Wilson & Welsh (1978) - cohort models
- when we hear a word we start a parallel search consistent with the onset
- as more info comes in, words drop off + cohort gets narrower
- Tyler (1984) - set size decrease happens faster in context
- Marslen-Wilson (1980) - ~150ms needed to set up a cohort
- Cole & Jakimik (1980) - salience of onset makes it more likely to detect mispronunciation at start of word than end
- lexical search starts immediately
- Allopenna et al., (1998) - additional late actication - info at later points can still activate lexical selection
- increase in fixation probability for word that rhymes
Access to meaning (speech recognition)
Deciding which meaning of a word is correct
- Swinney (1979) - ambiguous vs disambiguous context - bug = ant or spying device
- for early target - both dominant + non-dominant meanings activated by the prime
- for later (200ms) target - dominant meaning is only one activated –> has had time to disambiguate
- different meanings initially activated but context helps select


