HBX- BA - 2 Flashcards
Samples vs. Populations (and their symbols)
- Sample- A group of observations selected from a population. We generally compute statistics based on a random sample to help us estimate the parameters of a population.
- Population- The complete set of individuals or items in which an analyst or researcher is interested. When it is difficult to learn about every member of a population, random samples are often drawn from a population and analyzed in order to draw inferences about the population.

When we take a sample, we need to have a very clear understanding of the problem that we need to address. Based on that understanding, we need to do 2 things:
- What is the target population?
- What question do we want to ask?
Ex: Who will attend a conference that we are planning? Don’t ask the people planning the conference if they are going! Select 100 people at random! THEN see. Their answer is relative to the large group of people in attendance

What are parameters and statistics?
The numerical properties of a population are called parameters and those of a sample are called statistics.
A statistic is an estimate of a true value of a parameter. If a sample is sufficiently large and is representative of the population, the sample statistics should be reasonably good estimates of the population parameters.
How to enter random numbers in excel…
=RAND() to generate a random ID number between 0 and 1
- Copy and past this in other cells (or drag)
- Then you can sort them if you choose! in numerical order
DATA -> SORT ASCENDING
Suppose a college has asked you to conduct a survey to determine the percentage of 8:00 AM classrooms that were full on a given morning. The college has three classroom buildings, each containing two lecture halls. Each lecture hall has a capacity of 100 students. You randomly choose one of three buildings, and stand outside the entrance when classes let out. You ask the first 60 students leaving the building how full their class was. However, you soon realize that this sample is not random because you only went to only one of the buildings and the classes at that building may not be representative of all 8:00 AM classes. Moreover, since the students you surveyed were the first to exit the building, it’s also quite possible that they all came from the same class!
Realizing that your survey approach would not produce a random and representative sample, you gather some friends to help sample. You place one surveyor outside each building. You each randomly select 20 students leaving the buildings that morning and tally the results: 5 people decline to participate, 35 tell you that their class was full, and 20 tell you that their class was not full. Is your sample now representative of all classes that morning?
No
This question is a bit tricky. This sample still may not be representative of all classes because there is a bias in the approach. When you sample students leaving each of the buildings, you will, on average, select more people from full classes, simply because there were more people in those classes. Imagine that of the 6 classes that took place that morning, 4 were full (each having 100 students) and 2 had only 40 students each. In this case, most of the students, 400 of the total 480, were in full classes. Your sample would include more students from the full classes and therefore is not representative of all classes that took place that morning.
In addition to deciding how to select a random sample, we also must determine how large the sample should be. The appropriate sample size depends on how accurate we want our estimates of the population parameters to be. Suppose we want to sample from two populations—the first population comprises 5,000 observations and the second population comprises 5 million. If we take a sample of size 1,000 from the first population, how many times larger does the sample need to be from the second population to ensure the same level of accuracy?
No larger
We might expect that for a larger population, a larger sample size is needed to achieve a given level of accuracy, but this is not necessarily true. A sample of 1,000 is often a satisfactory representation of a population numbering in the millions, as long as the sample is randomly selected and representative of the entire population.
How big does a sample need to be to be accurate?
Sample size does not necessarily depend on population size. The right sample size depends on desired accuracy and in some cases, the likelihood of the phenomenon we wish to observe or measure.
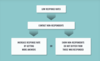
The graphic below suggests the general relationship between accuracy and sample size. Later in this module, we will learn how to calculate the minimum required sample size to ensure a specified level of accuracy.
Although we don’t necessarily have to increase the sample size for larger populations, we may need a larger sample size when we are trying to detect something very rare. For example, if we are trying to estimate the incidence of a rare disease, we may need a larger sample simply to ensure that some people afflicted with the disease are included in the sample.

What happens to the sample mean and standard deviation as you increase the sample size?
- The sample mean and standard deviation remain the same
- The sample mean and standard deviation generally become closer to the population mean and standard deviation
- The sample mean and standard deviation generally move further from the population mean and standard deviation
- The sample mean and standard deviation vary, but do not follow a consistent pattern
The sample mean and standard deviation generally become closer to the population mean and standard deviation
- As we increase the sample size, the sample includes more members of the population, so it is less likely to include only unusual values. Therefore, as the sample grows, the sample mean and standard deviation approach the population mean and standard deviation.
What are the steps to make sure that you avoid bias in samples/surveys?
- phrasing questions neutrally- welfare vs. poor
- ensuring that the sampling method is appropriate for the demographic of the target population; choose members randomly
- pursuing high response rates. It is often better to have a smaller sample with a high response rate than a larger sample with a low response rate.
- Surveyors wish to get as high a response rate as possible. Low response rates can introduce bias if the* non-respondent’s answers would have differed from those who responded—that is, if the non-respondents and the respondents represent different segments of the population. If we do not represent a segment of the population, then our sample is not representative of the population. If resources are limited, _it is often better to take a small sample and relentlessly pursue a high response rate than to take a larger sample and settle for a low response rate_. If we have a low response rate, we should contact non-respondents and try to either increase the response rate or demonstrate that the non-respondents’ answers do not differ from the respondents’ answers.
How to make sure that you can make sound inferences from your samples:
- Make sure the sample is representative of the population by choosing members randomly to ensure that each member of the population is equally likely to be included in the sample.
- Choose the right sample size: Sample size does not necessarily depend on population size. The right sample size depends on desired accuracy and in some cases, the likelihood of the phenomenon we wish to observe or measure.
- Avoid biased results by
- phrasing questions neutrally;
- ensuring that the sampling method is appropriate for the demographic of the target population; and
- pursuing high response rates. It is often better to have a smaller sample with a high response rate than a larger sample with a low response rate.
- If a sample is sufficiently large and representative of the population, the sample statistics, x¯ and s, should be reasonably good estimates of the population parameters, μ and σ, respectively.
Sample mean
Just a single point (a point estimate). The sample mean does NOT give us an accurate representation of the true population mean.
However we can use the normal distribution to help us create a range around the sample mean that is very likely to contain the true population mean. The properties of the normal distribution help us determine how confident that we can be in our estimate.
Horizontal Axis= the VARIABLE that we are studying.
Vertical Axis= the LIKELIHOOD the different values of that variable will occur.
Formal definition: The mean, or average, value of a variable in a sample. The sample mean is denoted by x-bar. For a given sample, the sample mean is the best estimate of the true population mean, provided that the sample is randomly selected. The sample mean varies for different samples drawn from a population. For a given population, the accuracy of a sample mean generally increases as the sample size increases. In general, the lower the variability in a population, the more accurate the sample mean is as an estimate of the population mean.

Normal distribution
The normal distribution is a symmetric, bell-shaped continuous distribution, with a peak at the mean. The mean, median and mode of a normal distribution are equal.
- How wide or narrow the curve is depends on the standard deviation. (see above)
- The location & width are completely specified by 2 parameters
- Mean
- Standard deviation
- About 68% of the probability is contained in the range reaching one standard deviation away from the mean on either side:
- *P ( μ − σ ≤ x ≤ μ + σ ) ≈ 68%**
- About 95% of the probability is contained in the range reaching two standard deviations (1.96 to be exact- which is the # we’ll use in excel for calculations) away from the mean on either side:
- *P ( μ − 2σ ≤ x ≤ μ + 2σ ) ≈ 95%**
- About 99.7% of the probability is contained in the range reaching three standard deviations away from the mean on either side:
- *P ( μ − 3σ ≤ x ≤ μ + 3σ ) ≈ 99.7%**
The amazing thing about normal distributions is that these rules of thumb hold for any normal distribution, no matter what its mean and standard deviation are. Because the normal distribution is a continuous probability distribution, the probability of the normal distribution equaling any particular value is zero (this is why we only assess the probability of a range for a continuous distribution). Because of this, we can use the terms “less than” and “less than or equal to” interchangeably when calculating probabilities for continuous distributions. Likewise we can use the terms “greater than” and “greater than or equal to” interchangeably. For example, because we know that the probability of the normal distribution equaling its mean exactly is zero, P(x=μ)=0, we can say 50% of the probability is less than the mean or 50% of the probability is less than or equal to mean: P(x
*

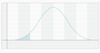
The standard normal curve
The standard normal curve is a normal distribution whose mean is equal to zero (μ=0), and whose standard deviation is equal to one (σ=1).
Notice that in the graph above we have labeled the x-axis twice—the upper scale shows which values are one standard deviation above or below the mean, which values are two standard deviations above or below the mean, and so on. The lower scale references those same locations on the standard normal curve, which is often easier to work with. These standardized values are known as z-values.

Cumulative Probability
- The probability of all values less than or equal to a particular value is called a cumulative probability.
- Note that cumulative probabilities are conceptually related to the percentiles of a distribution. For example, the value associated with a cumulative probability of 90% is the 90th percentile of the distribution.
To find a cumulative probability, the probability of being less than a specified value on a normal curve, we use:
Excel’s NORM.DIST function
=NORM.DIST(x, mean, standard_dev, cumulative)
- x is the value at which you want to evaluate the distribution function.
- mean is the mean of the distribution.
- standard_dev is the standard deviation of the distribution.
- cumulative is an argument that specifies the type of probability we wish to calculate. We insert “TRUE” to indicate that we wish to find the cumulative probability, that is, the probability of being less than or equal to the x-value. (Inserting the value “FALSE” provides the height of the normal distribution at the value x, which we will not cover in this course.)
For a standard normal curve, we know the mean is 0 and the standard deviation is 1, so we could find a cumulative probability using =NORM.DIST(x,0,1,TRUE). Alternatively, we use:
Excel’s NORM.S.DIST function
=NORM.S.DIST(z, cumulative)
- The “S” in this function indicates it applies to a standard normal curve.
- z is the value (the z-value) at which we want to evaluate the standard normal distribution function.
- cumulative is an argument that specifies the type of probability we wish to calculate. We will insert “TRUE”.
YOU CAN ALSO TAKE THE NORMAL DISTRIBUTION AND SUBTRACT IT FROM ONE (TO NOT DO THE CUMULATIVE)
Z-Vaule
The z-value of a data point is the distance in standard deviations from the data point to the mean. Negative z-values correspond to data points less than the mean; positive z-values correspond to data points greater than the mean.
How to find the z- value in Excel
=STANDARDIZE(x, mean, standard_dev)
- x is the value to be standardized.
- mean is the mean of the distribution.
- standard_dev is the standard deviation of the distribution.
- After standardizing, we can insert the resulting z-value into the NORM.S.DIST function to find the cumulative probability of that z-value.

What probability falls within one standard deviation of the mean?
Approximately 68%
- The phrase “within one standard deviation of the mean” means “between one standard deviation below the mean and one standard deviation above the mean.” This answer can be found using the rules of thumb for the normal distribution or by using the previous interactive. 68% of the probability lies within one standard deviation of the mean.
What is the probability of obtaining a value less than or equal to two standard deviations below the mean?
Approximately 2%
- You can use the interactive to solve this problem. If you position the slider so that it highlights the range from the far left side to “z=−2z=−2”, you can see that the area under the curve over than range is approximately 2%. This is the cumulative probability associated with z=−2z=−2. Therefore, the probability of obtaining a value less than or equal to two standard deviations below the mean is approximately 2%.
If the average height of all women is 63.5 inches and the standard deviation is 2.5 inches, approximately what percentage of women are between 58.5 and 68.5 inches tall?
95%
- 58.5 and 68.5 inches are two standard deviations from the mean, that is 63.5±2(2.5). According to the rules of thumb, approximately 95% of women’s heights fall within two standard deviations of the mean.
Recall that the z-value associated with a value measures the number of standard deviations the value is from the mean. Given that the average height of all women is 63.5 inches and the standard deviation is 2.5 inches, what z-value corresponds to 61 inches?

Suppose we want to know the percentage of women who are shorter than 63 inches. Since the mean is 63.5 inches, we can estimate that less than 50% are shorter than 63 inches. How do we calculate the exact percentage What excel function can we use to help us solve this?
To find a cumulative probability, the probability of being less than a specified value on a normal curve, we use:
Excel’s NORM.DIST function
=NORM.DIST(x, mean, standard_dev, cumulative)
- x is the value at which you want to evaluate the distribution function.
- mean is the mean of the distribution.
- standard_dev is the standard deviation of the distribution.
- cumulative is an argument that specifies the type of probability we wish to calculate. We insert “TRUE” to indicate that we wish to find the cumulative probability, that is, the probability of being less than or equal to the x-value. (Inserting the value “FALSE” provides the height of the normal distribution at the value x, which we will not cover in this course.)
For a standard normal curve, we know the mean is 0 and the standard deviation is 1, so we could find a cumulative probability using =NORM.DIST(x,0,1,TRUE). Alternatively, we use:
Excel’s NORM.S.DIST function
=NORM.S.DIST(z, cumulative)
- The “S” in this function indicates it applies to a standard normal curve.
- z is the value (the z-value) at which we want to evaluate the standard normal distribution function.
- cumulative is an argument that specifies the type of probability we wish to calculate. We will insert “TRUE”.
How to find the z- value in Excel
=STANDARDIZE(x, mean, standard_dev)
- x is the value to be standardized.
- mean is the mean of the distribution.
- standard_dev is the standard deviation of the distribution.
- After standardizing, we can insert the resulting z-value into the NORM.S.DIST function to find the cumulative probability of that z-value.

58%
- Since 42% of women are shorter than 63 inches, the percentage of women that have heights greater than or equal to 63 inches is 1–0.42 =0.58, or 58%. We could also calculate this directly using the Excel function 1–NORM.DIST(63,63.5,2.5,TRUE)=0.58, or 58%.


Suppose we want to find the value associated with the cumulative probability 99% for the distribution of women’s heights. In other words we might want to know the 99th percentile of women’s heights.
=NORM.INV(probability, mean, standard_dev)
- probability is the cumulative probability for which we want to know the corresponding x-value on a normal distribution.
- mean is the mean of the distribution.
- standard_dev is the standard deviation of the distribution.
Alternatively, we could use the Excel function NORM.S.INV. The “S” in this function indicates that it applies to a standard normal curve. Since we are working with the standard normal curve, we can interpret the resulting value as a z-value.
=NORM.S.INV(probability)
- probability is the cumulative probability for which we want to know the corresponding x-value on a standard normal distribution.
For example, if we wanted to know the z-value for the 95th percentile on a standard normal curve, we would enter =NORM.S.INV(0.95)=1.645. Equivalently, we could enter =NORM.INV(0.95,0,1)=1.645.
Suppose we want to calculate the value associated with the upper tail of a distribution, that is, the probability of an outcome greater than a specified value. We first need to calculate the value associated with the corresponding cumulative probability, which is one minus the probability of the upper tail. For example, the height that 1% of women are taller than is the same as the height that 99% of women are shorter than.
Thus we calculate the value associated with the top 1% by entering the function =NORM.INV(0.99,63.5,2.5)≈69.
Suppose we want to calculate the value associated with the upper tail of a distribution, that is, the probability of an outcome greater than a specified value. How is this done?
We first need to calculate the value associated with the corresponding cumulative probability, which is:
1 - minus the probability of the upper tail
For example, the height that 1% of women are taller than is the same as the height that 99% of women are shorter than. Thus we calculate the value associated with the top 1% by entering the function =NORM.INV(0.99,63.5,2.5)≈69.







































