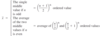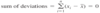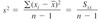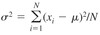Chapter 1 Flashcards
Population
The entire collection of individuals or objects about which information is desired
Census
When all of the desired information is avaiable for all objects or individuals in the population
Sample
A subset of the population because of limited time, resources, money, etc.
Types of Variables
1) Categorical 2) Quantitative or Numerical
Categorical Variable
A categorical variable places an individual or object into one of several groups or categories Ex) Gender, race, type-of-job, hair color
Quantitative or Numerical Variable
A Quantitative or Numerical Variable takes numerical values for which arithmetic operations such as adding and calculating an average value makes sense Ex) Age, salary
Discrete numerical data
Numerical data is discrete if it’s set of possible values are finite Ex) Your year in college (1, 2, 3 or 4)
Continous numerical data
Numerical data is continuous if it’s set of possible values form an entire interval on the number line Ex) Weight/height of an individual
Univariate Data
Observations made on a single variable for each object in the dataset Ex) The unemployment rate of each state (state = object and unemployment rate = single variable)
Multivariate Data
Observations made on multiple variables for each object in the dataset Ex) Each person -> age, gender, race, salary, job-type
Bivariate Data
Bivariate data is a special case of multivariate data, where observations are made on two variables for each object in the dataset
Branches of Statistics
Descriptive Statistics; Inferential Statistics; Probability
Descriptive Statistics
- Objective is to merely summarize and describe important features of the data that is collected - Graphical approach: stem-and-leaf plots, histograms, box-plots, pie-charts, scatter-plots etc. - Numerical approach: calculation of numerical summary measures such as arithmetic mean, median, mode, standard deviation, correlation coefficient etc.
Inferential Statistics
- Objective is to use information in the sample to make some sort of a conclusion (or inference) about the population from which the sample was selected - Includes Point-estimation, Hypothesis Testing, Confidence Interval Estimation, ANOVA, Linear Regression, etc.
Probability
- Forms a bridge between descriptive and inferential statistics - Probability makes assumptions about the structure of the population, and then asks questions about what might result from selecting a sample from the population (deductive reasoning)
Stem-Leaf Plot Construction
Separate each observation into a ‘stem” consisting of all but the final (rightmost) digit and a “leaf,” the final digit
Stem-Leaf Plot: Pros and Cons
Pros: - a quick way of describing and ordering data - generally easy to construct - displays the actual data values - easy way to obtain a general idea of the distribution of the data (e.g. symmetric, skewed, bimodal) - to be able to describe the data from a stem-and-leaf plot, look for: a typical or a representative value (e.g. median); extent of spread about the typical value; presence of any gaps in the data; number and location of peaks; outliers Cons: - not always easy to construct an appropriate stem
Relative Frequency
The proportion of times the value occurs in the sample For continuous data -> we have to create class-intervals and find the relative frequency for each class-interval
Construction of Histograms for Discrete Data
Area of each rectangle is proportional to the relative frequency of the value
Positive Skew of Histogram
A unimodal histogram with the right or upper tail stretched out more compared to the left or lower tail
Symmetric Histogram
Left half of the histogram is mirror image of right half
Unimodal Histogram
Histogram rises to a single peak and then declines
Bimodal Histogram
Histogram has two different peaks
Multimodal Histogram
A histogram with more than two peaks