Ch 7-8 Carbs and Nucleotides Flashcards
carbohydrates: basic formula, functions, produced from?
any organic molecule that has the basic formula: Cn(H2O)n
produced from CO2 and H2O via photosynthesis in plants
isn’t just sugar; can be glyceraldehyde, pyruvate, amylopectin
functions include: energy source and energy storage; structural component of cell walls and exoskeletons, and informational molecules in cell-cell signaling (ABO blood types)
can be covalently linked with proteins to form glycoproteins and proteoglycans
aldoses vs ketoses
aldose: contains and aldehyde functional group (glucose, galactose, ribose)
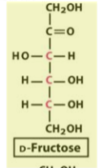
ketose: contains a ketone functional group (fructose)

epimers
2 sugars that differ only in the configuration around one carbon atom
memorize glucose and galactose structures!

fructose structure
a simple change in structure (from glucose) results in a huge difference in taste (sweeter)
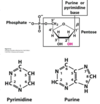
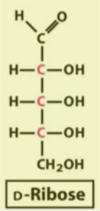
ribose/deoxyribose structure
deoxyribose does not have an –OH at C?
hemiacetals and hemiketals
aldehyde and ketone carbons are electrophilic
the alcohol oxygen atom is nucleophilic
hemiacetals: when aldehydes are attacked by alcohols
hemiketals: when ketones are attacked by alcohols
If the –OH and carbonyl groups re on the same molecules, a five- or six-membered ring results. The addition of the second molecule of alcohol produces the full acetal

cyclization of monosaccharides
in aqueous solution, all monosaccharides with 5+ carbon atoms in the backbone occur predominantly as cyclic structures; cyclic sugars are opening and closing constantly (the ring form exits in equilibrium with the open-chain forms)
- pyranoses: six-membered oxygen-containing rings (glucose and galactose)
- furanoses: five-membered oxygen-containing rings (fructose)
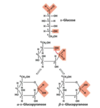
the former carbonyl carbon becomes a new chiral center, called the anomeric carbon
The former carbonyl oxygen becomes a hydroxyl group; the position of this group determines if the anomer is α or β
- more β-glucopyranose than α-glucopyranose (85:15 ratio)
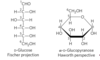
Fisher/Hanworth projections of glucose
to convert the Fischer projection formula to a Hanworth perspective formula
1) draw the six-membered ring (5 carbons, and 1 oxygen at the upper right)
2) number the carbons in a clockwise direction, beginning with the anomeric carbon
3) if a hydroxyl group is to the right in the Fischer projection, it is placed pointing down in the Hanworth perspective; if left, placed pointing up
4) the terminal –CH2OH group projects upward for the D-enantiomer, downward for the Lenantiomer
Draw the Haworth perspective formula for D-galactose
a) six-membered (oxygen atom at the top right)
b) number the carbon atoms clockwise
c) place the hydroxyls below, above, and above the ring for C-2, C-3, and C-4, respectively
d) the hydroxyl at C-1 can point either up or down
Draw the Haworth perspective formulas for ß-L-galactose
a) use the Fischer representation of D-galactose to draw the L-galactose (mirror image)
b) draw the Haworth perspective: –OH groups on C-2, C-3, and C-4 are oriented up, down, and down, respectively
c) the –OH on the anomeric carbon points down
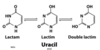
Reducing Sugars and 3 tests
the aldehyde can reduce Cu2+ to Cu+ (Fehling’s test)
the aldehyde can reduce Ag+ to Ag0 (Tollens’ test)
colorimetric glucose analysis: glucose oxidase catalyzes the conversion of glucose; hydrogen peroxide oxidizes organic molecules into highly colored compounds; concentrations of such compounds is measured colorimetrically; 1 for 1, measure how much glucose is present by the intensity of the orange color
allows the detection of reducing sugars, such as glucose
the oxidation of sugar by the cupric ion occurs only with the linear form, which exists in equilibrium with the cyclic form
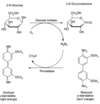
disaccharide formation
Two monosaccharides join between an anomeric carbon and a hydroxyl carbon, the acetal or ketal formed is a disaccharide. The bond formed is a glycosidic linkage, which is less reactive than the hemiacetal at the second monomer (reducing)
maltose: disaccharide formed upon condensation of two glucose molecules via 1 → 4 bond

nonreducing disaccharides
when the anomeric carbons are involved in a glycosidic bond, the interconversion of linear and cyclic forms is prevented, rendering the sugar nonreducing.
sucrose: glucose and fructose (two acetal groups and no hemiacetals)
- formed by plants but not by animals
- its stability (no reducing ends = resistance to oxidation) makes it suitable for the storage and transport of energy in plants (from leaves to other parts of the plant body)

lactose
reducing disaccharide
Gal (B1 →4)Glc
disaccharides are not absorbed from the small intestine; without lactase, the undigested lactose passes into the large intestine
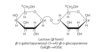
Polysaccharides
homopolysaccharides vs heteropolysaccharides
linear vs branched
do not have a defined molecular weight; unlike proteins, no template is used to make polysaccharides
size-exclusion columns are built out of a sugar polymer called Sephadex; sugar casted in a form of a bead

glycogen
main storage homopolysaccharide in animals (muscle and liver)
glucose monomers form (α1 →4) linked chains and (α1 →6))-linked branches every 8-12 residues (more branched and compact than starch)
molecular weight reaches several million
starch
main storage homopolysaccharide in plants
contains two types of glucose polymer:
- amylose: long, unbranched chains of glucose connected by (α1 →4) linkages
- amylopectin: highly branched (α1 →6; every 24-30 residues) and has a high molecular weight (up to 200 million)
strands of amylopectin form double-helical structures with each other or with amylose strands
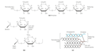
metabolism of glycogen and starch
glycogen and starch often form granules in cells that contain enzymes that synthesize and degrade these polymers
glycogen molecule with n branches has n + 1 nonreducing ends, but only one reducing end
glucose residues at the nonreducing ends of the outer branches are removed enzymatically for energy production; many degradative enzymes can work simultaneously on many branches
cellulose
a tough, fibrous, water-insoluble substance found in cell walls of plants; most abundant polysaccharide in nature; cotton is nearly pure fibrous cellulose
linear, unbranched homopolysaccharide
glucose residues are linked by (β1 →4) glycosidic bonds in contrast to the (α1 →4) bonds of amylose (gives them a different structure and physical properties)
humans cannot use cellulose as a fuel source because we lack an enzyme to hydrolyze the (β1 →4) linkages
hydrogen bonds between adjacent monomers and lots between chains
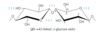
chitin
linear homopolysaccharide composed of N-acetylglucosamine residues in (β1 →4) linkage
forms extended fibers similar to cellulose; the only difference is the replacement of the hydroxyl group at C-2 with an acetylated amino group, which allows for more H-bonding and a stronger structure
tough, flexible, water-insoluble, cannot be digested by vertebrates
found in cell walls in mushrooms and in exoskeletons of arthropods; second-most abundant polysaccharide, next to cellulose
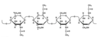
agar and agarose
agar: a complex mixture of heteropolysaccharides containing modified galactose units (sulfated)
- serves as a component of the cell wall in some seaweeds
- agar solutions are used to form a surface for the growth of bacterial colonies; bacteria cannot dissolve the (β1 →4) linkages in agar
agarose: one component of agar (highly purified)
- agarose solutions (heated and cooled), form gels that are commonly used in the lab for separation of DNA by electrophoresis
- galactose sugar with ether bridge and addition of sulfur group
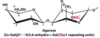
What are the 3 classes of glycoconjugates?
glycoconjugates are proteins or lipids with sugar molecules attached to them
glycoproteins
proteoglycans
mucins
glycoproteins
mostly protein by mass
modified after protein synthesis
often found on secreted proteins and on cell surface proteins, in the ECM, and in the blood; forming highly specific sites for recognition (blood groups proteins, HIV virus coat, erythropoietin)
erythropoietin (EPO): hormone involved to signal for more RBC production; Ser and Asn involved in linking protein and sugar

proteoglycans
macromolecules of the cell surface or ECM in which one or more sulfated glycosaminoglycan chains (long unbranched polysaccharide chains of repeating disaccharide) are joined covalently to a membrane protein or a secreted protein
mostly carbohydrate by mass
a major component of cartilage and tendons, the adhesion of cells to the ECM, lubricants in synovial fluid of joints, and horny structures formed from dead cells in horn, hair, and hoofs (keratan sulfates)