Basics Of Optimization Flashcards
(47 cards)
Loss function (Objective function)
An optimization problem has an objective function that is defined in terms of a set of variables, referred to as optimization variables. The goal of the optimization problem is to compute the values of the variables at which the objective function is either maximized or minimized.
Optimality Conditions in Unconstrained Optimization
A univariate function f(x) is a minimum value at x = x0 with respect to its immediate locality if it
satisfies both f
(x0)=0 and f(x0) > 0.
Taylor expansion for evaluating minima

Jacobian
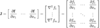
Hessian matrix

Multivariate Taylor expansion for evaluating minima

Second-order optimality conditions

Convex set
A set S is convex, if for every pair of points w1, w2 ∈ S, the point λw1 + [1 − λ]w2 must also be in S for all λ ∈ (0, 1)
Convex set - Visual representation

Convex function

Linear functions and convexity
A linear function of the vector w is always convex
Second-Derivative Characterization of Convexity
The twice differentiable function F(w) is convex, if and only if it has a positive semidefinite Hessian at every value of the parameter w in the domain of F(·)
The following convexity definitions are equivalent for twice differentiable functions defined over Rd

The sum of a convex function and a strictly convex function
Is strictly convex
Finite-difference approximation
Is used to verify that the gradient is calculated appropriately

Decaying learning rate

The gradient at the optimal point of a line search
Is always orthogonal to the current search direction
Second-order multivariate Taylor expansion of J(w) in the immediate locality of w0 along the direction v and small radius ε > 0

Mini-batch stochastic gradient descent
Min-max normalization
Min-max normalization is useful when the data needs to be scaled in the range (0, 1)

Feature normalization
A common type of normalization is to divide each feature value by its standard deviation. When this type of feature scaling is combined with mean-centering, the data is said to have been standardized. The basic idea is that each feature is presumed to have been drawn from a standard normal distribution with zero mean and unit variance
Mean-centering
In many models, it can be useful to mean-center the data in order to remove certain types of bias effects. Many algorithms in traditional machine learning (such as principal component analysis) also work with the assumption of mean-centered data. In such cases, a vector of column-wise means is subtracted from each data point
Common quadratic loss function and its gradient

Common linear loss function and its gradient






















