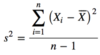Reading 11 - Sampling and Estimation Flashcards
(113 cards)
Sampling
In a simple random sample, each member of the population has the same probability or likelihood of being included in the sample. For example, assume that our population consists of 10 balls labeled with numbers 1 to 10. Drawing a random sample of 3 balls from this population of 10 balls would require that each ball has an equal chance of being chosen in the sample, and each combination of balls has an identical chance of being the chosen sample as any other combination.
Systematic sampling
In practice, random samples are generated using random number tables or computer random‐number generators. Systematic sampling is often used to generate approximately random samples. In systematic sampling, every kth member in the population list is selected until the desired sample size is reached.
Systematic sampling
In practice, random samples are generated using random number tables or computer random‐number generators. Systematic sampling is often used to generate approximately random samples. In systematic sampling, every kth member in the population list is selected until the desired sample size is reached.
Sampling error
Sampling error is the error caused by observing a sample instead of the entire population to draw conclusions relating to population parameters. It equals the difference between a sample statistic and the corresponding population parameter.
Sampling error of the mean
Sampling error of the mean = Sample mean − Population mean = x − μ
Sampling distribution & sampling distribution of the mean
A sampling distribution is the probability distribution of a given sample statistic under repeated sampling of the population. Suppose that a random sample of 50 stocks is selected from a population of 10,000 stocks, and the average return on the 50‐stock sample is calculated. If this process were repeated several times with samples of the same size (50), the sample mean (estimate of the population mean) calculated will be different each time due to the different individual stocks making up each sample. The distribution of these sample means is called the sampling distribution of the mean.
Remember that all the samples drawn from the population must be random, and of the same size. Also note that the sampling distribution is different from the distribution of returns of each of the components of the population (each of the 10,000 stocks) and has different parameters.
Stratification
Stratification is the process of grouping members of the population into relatively homogeneous subgroups, or strata, before drawing samples. The strata should be mutually exclusive i.e., each member of the population must be assigned to only one stratum. The strata should also be collectively exhaustive i.e., no population element should be excluded from the sampling process. Once this is accomplished, random sampling is applied within each stratum and the number of observations drawn from each stratum is based on the size of the stratum relative to the population. This often improves the representativeness of the sample by reducing sampling error.
Time-series data
- ‐series data consists of observations measured over a period of time, spaced at uniform intervals. The monthly returns on a particular stock over the last 5 years are an example of time‐series data.
Cross-sectional data
Cross‐sectional data refers to data collected by observing many subjects (such as individuals, firms, or countries/regions) at the same point in time. Analysis of cross‐sectional data usually consists of comparing the differences among the subjects. The returns of individual stocks over the last year are an example of cross‐sectional data.
Data sets can have both time‐series and cross‐sectional data in them. Examples of such data sets are:
Longitudinal data, which is data collected over time about multiple characteristics of the same observational unit. The various economic indicators—unemployment levels, inflation, GDP growth rates (multiple characteristics) of a particular country (observational unit) over a decade (period of time) are examples of longitudinal data.
Panel data, which refers to data collected over time about a single characteristic of multiple observational units. The unemployment rate (single characteristic) of a number of countries (multiple observational units) over time are examples of panel data.
Central limit theorem
The central limit theorem allows us to make accurate statements about the population mean and variance using the sample mean and variance regardless of the distribution of the population, as long as the sample size is adequate. An adequate sample size is defined as one that has more than 30 observations (n ≥ 30).
The important properties of the central limit theorem are:
1) Given a population with any probability distribution, with mean, μ, and variance, σ2, the sampling distribution of the sample mean x-bar, computed from sample size, n, will approximately be normal with mean, μ (the population mean), and variance, σ2/ n (population variance divided by sample size), when the sample size is greater than or equal to 30.
2) No matter what the distribution of the population, for a sample whose size is greater than or equal to 30, the sample mean will be normally distributed.
x̅ ~ N(μ,( σ2/n))
3) The mean of the population (μ) and the mean of the distribution of sample means x are equal.
4) The variance of the distribution of sample means equals σ2/n, or population variance divided by sample size.
Standard error
The standard deviation of the distribution of sample means is known as the standard error of the statistic.
When the population variance, σ 2, is known, the standard error of sample mean is calculated as:

Practically speaking, population variances are almost never known, so we estimate the standard error of the sample mean using the sample’s standard deviation:

Point estimate
A point estimate involves the use of sample data to calculate a single value (a statistic) that serves as an approximation for an unknown population parameter. For example, the sample mean, x, is a point estimate of the population mean, μ. The formula used to calculate a point estimate is known as an estimator.
The estimator for the sample mean is given as:
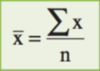
Confidence interval
A confidence interval uses sample data to calculate a range of possible (or probable) values that an unknown population parameter can take, with a given of probability of (1 – α). α is called the level of significance, and (1 – α) refers to the degree of confidence that the relevant parameter will lie in the computed interval. For example, a calculated interval between 100 and 150 at the 5% significance level implies that we can be 95% confident that the population parameter will lie between 100 and 150.
A (1 – α)% confidence interval has the following structure:
Point estimate ± (reliability factor * standard error)
where:
Point estimate = value of the sample statistic that is used to estimate the population parameter.
Reliability factor = a number based on the assumed distribution of the point estimate and the level of confidence for the interval (1 – α).
Standard error = the standard error of the sample statistic (point estimate).
When choosing between a number of possible estimators for a particular population parameter, we make use of the desirable statistical properties of an estimator to make the best possible selection. The desirable properties of an estimator are:
Unbiasedness
Efficiency
Consistency
Statistical property: Unbiasedness
Unbiasedness: An unbiased estimator is one whose expected value is equal to the parameter being estimated. The expected value of the sample mean equals the population mean [E(x) = μ]. Therefore, the sample mean, x, is an unbiased estimator of the population mean, μ .
Statistical property: Efficiency
Efficiency: An efficient unbiased estimator is the one that has the lowest variance among all unbiased estimators of the same parameter.
Statistical property: Consistency
Consistency: A consistent estimator is one for which the probability of estimates close to the value of the population parameter increases as sample size increases. We have already seen that the standard error of the sampling distribution falls as sample size increases, which implies a higher probability of estimates close to the population mean.
Student’s t‐distribution is a bell‐shaped probability distribution that has the following properties:
- It is symmetrical.
- It is defined by a single parameter, the degrees of freedom (df), where degrees of freedom equal sample size minus one (n‐1).
- It has a lower peak than the normal curve, but fatter tails.
- As the degrees of freedom increase, the shape of the t‐distribution approaches the shape of the standard normal curve.