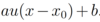Quiz 2: Lectures 6 to 9 Flashcards
What is the problem with least squares?
It assumes that the noise distribution is the same for all the points but it is often more complicated since we have inliers and outliers.
Notice:
If we are penalising all point by their squared distance from the line then the outliers will have a huge penality. We sometimes call this huge penality loss which can drive the estimated solution away from the correct solution.
Inliers
Points that follow the model
Outliers
Points that do not follow the model
Hough Transform
1. Define a matrix H that counts the number of votes for a line defined by (r, teta) and initialise H to 0
- For each (x_i, y_i){
- For each teta { //choose sampling of tetas
- r:= round(x_i cos(teta) + y_i sin(teta))
- H(r, teta) ++;}}
- For each teta { //choose sampling of tetas
- return (r , teta) with most votes
In words, what does the Hough Transform do?
The Hough Transforms referst to the transformation from set of points (x_i, y_i) to histogram of votes in the model parameter space (in this case (r, teta))
Name the advantages of Hough Transform
- Outliers have little effect on the estimate
- The votes of the outliers will be spread over the (r, teta) space
Is it possible to get more than one line with Hough Transform? If yes, how do you pick the correct one?
It might be possible that you get two lines from the Hough Transform. You have to either choose one or accept thare are two correct models.
(See lecture 6 and Matlab for more)
RANSAC
Random Sample Consensus
This is often used when there are lots of outliers. It is also often used when the number of parameters of the model is more than 2.
It is capable of fitting a model by suing a minimal number of points. In the case of a line it needs 2.
RANSAC algorithm (roughly explained)
Sample a large number of points pairs. For each pair of points find the unique line that passes through both points. Then compare all the remaining points to the lines and qualify the points whose distance is less than a threshold tau to be “near” the line. The set of “near” points is called consensus set for that line model.
Repeat this for a certain number of times. Then choose the model that has the largest consensus set. Finally, use least squares on the consensus set and terminate.
RANSAC Algorithm
- Repeat many times{
- Randomly select 2 points and fit a line
- Examine the remaining points (N-2) and count how many (C) are within tau distance from the line
- If C = new max then refit the model useing least squares and save new line model
- }
See notes p.3 for a more general description.
RANSAC Parameters
We have to decide a number of parameters:
- When do we consider an edge on point as part of the consensus?
- When do we stop looking for a better model?
Notice:
The two parameters above are related. If the first one is looser, we might terminate earlier.
RANSAC Probability
- Let w be the probability that a randomly sample point is an inliner.
- Suppose we need n points to fit a model
- The probability of all n points being inliers is w^n
- The probability that we fail to find all the inliers is 1 - w^n
- If we run k trials, the probability that we fail to find all inliers in k trials is (1 - w^n)^k
- So if you have some idea of what w is and you have a desired probability z of getting at least one good model then you can estimate the number of trials k by solving z = 1 - (1 - w^n)^k for k
Name a limitation to edges
One limitation with edges is that we cannot use them to reliably identify single (isolated) points. This is since edges have well defined intensitygrdient direction and so the intensity is by definition contstant along the edge.
For example, if you compare two different points on a edge, they are difficult to distinguish.
Corners
Corners are points that are locally distinctive. They are also called interest points and keypoints. There are not necessarly corners. The word corner just suggests that there are two edges comming together at a sharp angle.
To find the “corners”, we can look at the intensities in a small neighborhood around a point (x_0, y_0). If the intensities in this neighborhood are different from those in a same size neighborhood around (x_0 + delta x, y_0+delta y), then it is a locally distinctive point.
How do we find locally distinctive points?
By definition, the intensities at point (x_0, y_0) are locally distinctive if any local shift in the image patch gives you a different patten of image intensities.
To find a corner, we look at the sum of squared differences of intensities of the patch and the shifted patch where the shift of the patch is.
To avoid to restricti ourselves to integer values of delta x and delta y, we approximate I(x+delta x, y+delta y) with Taylor series (first order).
We can then rearrange the equation and compress all that into a single matrix M called second moment matrix.
To give more weight to the center of the matrix, we commonly use a function W(*,*) (typically a Gaussian) such that we end up with a weighted version of the second moment matrix.
Second Moment Matrix

Structure Tensor

Weighted Second Moment Matrix
- Provides information about the geometry of the gradient field in the local neighborhood of (x_0, y_0)
- M is also:
- symmetric
- positive definite
- no negative eigenvalues
- can be written as M = VAV
- columns v1, v2 of V are the eigenvectors of M and are othonormal
- A is a diagonal matrix with elements a1, a2

Inner Scale
Small standard deviation used when we smooth the imge before taking the gradient.
Outer Scale
Big standard deviation coming from the Gaussian weighing M.
What is the qualitative relationship between the image intensity pattern in the neighborhood and the eigenvalues and eigenvectors?
- It was found that if the eigenvalues a1,a2 can be ordered a1 >= a2 > 0, then
- if the image intensity is near constant in the neighborhood, then gradients are small and a1 ~ a2~ 0
- If step edge in intensity in neighborhoods then all gradients are parallel and a1 > 0 but a2~0
- If gradient pointing to different directions and a1 != 0 and a2 != 0, then found a corner.
Name a reason why we would use Harris Corners’ procedure
Notice that in the normal procedure we would solve a quadratic for each pixel to find the eigen values.
Harris Corners
Trick:
Det of matrix with eigen values = a1a2
trace = a1 + a2

Describe the operator by Brown, Szeliski and Winder
where e is a small positive number that avoids division by 0.