Quant Flashcards
Calculate and interpret a sample covariance and a sample correlation coefficient (r).
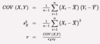
Identify the two sources of uncertainty when the regression model is used to make a prediction regarding the value of the dependent variable.
The uncertainty inherent in the error term, ε.
The uncertainty in the estimated parameters, b0 and b1.
Calculate and interpret a confidence interval for the predicted value of the dependent variable.

Explain the analysis of variance (ANOVA).
ANOVA describes the usefulness of the independent variables in capturing variation in the dependent variable.
RSS + SSE = Total variation. (Note that SSE is different from SEE.)
Formulate a null and alternative hypothesis about a population value of a regression coefficient and determine the appropriate test statistic and whether to reject the null hypothesis.

Calculate and interpret the F-stat.

Give the formula used to determine the linear regression model between the dependent and independent variables.

Calculate and interpret the standard error of the estimate (SEE).
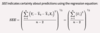
Calculate and interpret the coefficient of determination (R2).

List the five assumptions of the linear regression model.
Linearity within the parameters, b1 and b0.
The independent variable, X, is not random.
E(ε) = 0.
The variance of the error term is constant for all observations (i.e., homoskedasticity).
Uncorrelated, normally distributed errors.
Explain how time-series variables should be analyzed for nonstationarity and/or cointegration before use in a linear regression.
If the dependent variable or any independent variable has a unit root and at least one time series does not, multiple linear regression cannot be used due to nonstationarity.
If all of them have unit roots, the time series must be tested for cointegration as outlined previously.
Distinguish between unconditional and conditional heteroskedasticity.
Heteroskedasticity describes an inconsistent error term across observations.
Unconditional – Not related to independent variables in the regression; does not create major problems for statistical inference.
Conditional – Correlated with the independent variables in the regression; does create problems but can be identified and corrected.
Identify the two ways to correct for conditional heteroskedasticity in linear regression models.
Robust standard errors – Corrects standard errors for the conditional heteroskedasticity.
Generalized least squares – Modifies the regression equation for conditional heteroskedasticity. This requires econometrics expertise.
What are the two approaches to check for seasonality?
Graph the data and check for regular seasonal patterns.
Examine the data to see whether the seasonal autocorrelations of the residuals from an AR model are significant and whether other autocorrelations are significant.
Explain the two options when making an initial choice of model.
A regression model that predicts the future behavior of a variable based on hypothesized causal relationships with other variables.
A time-series model that attempts to predict the future behavior of a variable based on the past behavior of the same variable.
Describe the autoregressive moving-average (ARMA) models.
An ARMA (p,q) model combines autoregressive lags of the dependent variable (p) and moving-average errors (q) in order to provide better forecasts than simple AR models.
Why are moving averages generally calculated?
To focus on the underlying trend by eliminating “noise” from a time series.
Identify the two situations that must be met for an AR model to be estimated using ordinary least squares.
Calculate the predicted trend for a linear time series given the coefficients.
Describe factors that determine whether a linear or a log-linear trend should be used.

Explain mean reversion and calculate a mean-reverting level.

How is the Durbin-Watson (DW) test approximated?
Describe how model misspecification affects regression results.
Failing to transform variables can lead to increasing error terms that violate regression assumptions of homoskedasticity.
Omitting important variables can lead to biased and inconsistent estimations for the regression coefficients.
Explain how autocorrelation of residuals can be used to test whether a model fits the time series.
First, assume that the expected value for the error term in a time series model is 0. Perform a hypothesis test; if the absolute value of t-calc is higher than t-critical, accept the null hypothesis that the autocorrelation is not significantly different from 0.







