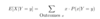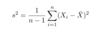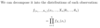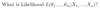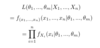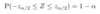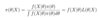Probability and Statistics Basics Flashcards
(72 cards)
Prob: What are the two equivalent definitions of events A and B being independent?
P(A,B) = P(A)P(B)
OR
P(A) = P(A | B=b) for all values of b
(Pretty darn sure second is correct)
Prob: What are the two equivalent definitions of random variables Y1 and Y2 independent?
F(y1,y2) = F1(y1)F2(y2) (The joint dist factors to the marginal dists)
OR
F1(y1) = F(y1 | Y2 = y2) for all values of y2 (The marginal distribution for either variable is the same as the conditional distribution given any value of the other variable)
(Pretty darn sure second is correct)
Prob: Conceptually, what does it mean for A and B to be independent, either as variables or as events?
A and B are independent variables if the value of one variable gives you no information about the value of the other.
A and B are independent events if knowing whether one event happened or not gives you no information on whether the other happened.
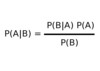
Prob: What is Bayes’ Theorem?
Prob: What is a formula for P(A union B)?
P(A) + P(B) - P(A and B)
Prob: What is linearity of expectation?
E[cX + kY] = cE[X] + kE[Y], even if X and Y are dependent
Prob: What is one potentially convenient way to find P(A and B) when A and B are dependant?
P(A)*P(B|A), or P(B)*P(A|B)
Stat: What proportion of points drawn from a normal distribution will fall within 1 standard deviation? 2? 3?
68% within 1, 95% within 2, 99.7% within 3
Prob: What is the law of total probability?
If you can decompose the sample space S into n parts B1,…,Bn, then
P(A) = P(A|B1)P(B1) + … + P(A|Bn)P(Bn)
A common form is
P(A) = P(A|B)P(B) + P(A|Bc)P(Bc)
Prob: What trick is often used in the denominator of a Bayes’ Rule problem?
Law of total probability
Prob: What is a probability density function, or pdf f(), typically used for?
For a given probability distribution, you can integrate f() over an interval (or area, or n-d area) to find the probability that an experiment will fall in that interval/area.
Prob: what is a cumulative density function F(), or cdf, typically used for? How is it related to the pdf f()?
For a given probability distribution of RV X, F(x) = P(X <= x)
If you integrate f() from -inf to a, you get F(a)
Prob: What is the formula for the expected value of discrete RV X?

Prob: What is the formula for E[g(X)], or the expected value of a function g of continuous RV X, with pdf f()?
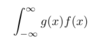
Prob: V[aX+b]?
a2V[X]
Prob: Conceptually, what does it mean for a probability distribution Y to be memoryless?
For an experiment, past behavior has no bearing on future behavior. For example, if you’re waiting for a bus to come and it follows a memoryless distribution (such as an exponential one), if you wait 5 minutes and there’s still no bus, the probability distribution of when it will arrive starting now, after 5 minutes is the same as it was when the experiment began.
Prob: what is the expected value of a geometric random variable (i.e. flip coin until a success) with probability p of success?
1/p
Prob: If our binonial distribution (flip n times, see how many are succcesses) has events with probability p of success, and we conduct n events, what is the probability that y will be successes (assuming 0 <= y <= n)? And what is the intuition behind this result?
py(1-p)n-y is the odds of a specific result with y successes (so y specific positions being successes, and the other n-y being failures). But we need the probability of any; these occurrences are disjoint, so we sum their probabilities by multiplying by the number of such potential outcomes, which is n choose y.
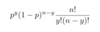
Prob: In words, what is the law of large numbers?
When sampling from a distribution, as the number of samples grows, the sampling mean will tend towards the expected value of the distribution.
Normal: If Y follows N(µ,ð2), what is the formula for the z-score Z of Y=y?
Z = (y - µ)/ð
Normal: If Y follows N(µ,ð2), what (in words) is the z-score of Y=y?
The number of standard deviations ð that y is above or below the mean µ.
Stat: What does the standard normal distribution Z follow?
Z follows N(0,1)
Prob: What is the law of total expectation?
We can find E[X] by taking the weighted sum of the conditional expectations of X given all values of a variable Y.
For example, if Y = Y1 or Y2, then
E[X] = E[X|Y1]P(Y1) + E[X|Y2]P(Y2)
Prob: What is the formula for the conditional expectation of X given that Y=y?