Deep Learning, xgb, BERT Flashcards
(122 cards)
Intuitively, why should a NN/MLP with a bunch of successive layers of processing be good at finding patterns, like identifying images of digits?
The intuitive idea is that each subsequent layer is being trained to recognize higher-level patterns. So maybe layer 1 is edge detection, layer 2 is finding a shape like a circle, and layer 3 can identify full digits.
In a more complex image, maybe layer 1 is lines, layer 3 is texture, etc.
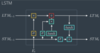
In a “vanilla NN”, or MLP, how does a given layer of processing work? How do we go from layer i of size N to layer i+1 of size M?
Each of the M neurons in the output layer is computed by taking a weighted sum of all the values of the input layer (plus a bias), then passing it through an activation function. Typically the weights are learned but the activation is not, it’s something like relu or sigmoid.
So in order to get one of the output neurons, you take the N inputs, plus an input of 1 that’ll be multiplied by the bias, as a column vector and multiply them by a length N+1 row vector of weights; then you take the that output and pass it through the activation.
So if you want a length M output, you need M row vectors, and thus you’re multiplying the length-N+1 input by an MxN+1 matrix to get the length M output (which goes through the activation).
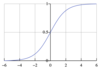
What is the sigmoid activation? What is its formula, and what does the graph look like? What does it functionally “do”?
It squishes all the real numbers between 0 and 1, like in logistic regression.

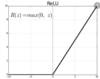
What does the relu activation function look like?
What is the softmax function? How is it computed, and what is it used for?
The softmax is the go-to output layer if you’re predicting a categorical variable with more than 2 categories. All the layer outputs are between 0 and 1, and they sum to 1 – so they’re basically probabilities (they aren’t exactly but can often kinda be interpreted that way), and whichever outcome class is being predicted as having highest probability is chosen.
The formula is shown below, where there are K values you’re trying to predict, each has a corresponding value z that needs to be passed through the softmax.
It’s similar to sigmoid

When learning an NN, what gradient are you calculating during optimization, and why? How does gradient descent work?
In order to optimize a neural network, you need to find the derivative of the loss function with respect to each of the weights in the network (maybe thousands or millions), and then you update the weights by taking a small step in that direction (I think technically the opposite direction but whatever).
If you want the partial derivative of a function with respect to each input variable, that’s the gradient: the gradient of the loss function is the vector of the function’s partial derivatives with respect to each parameter. So that’s what we calculate and optimize based on.
Conceptually, how does backpropogation work?
Basically you use the chain rule to efficiently get the partial derivatives one layer at a time.
You start by setting up the formulas to get the partial derivatives of the loss function with respect to the weights in the last layer. **These formulas will depend on the activation of the previous layer**, but you just hold that value constant while simply calculating the partial derivatives of this layer.
Then, basically using the chain rule, you substitute in the formula for the activation from the previous layer, and now holding constant the stuff from the subsequent layer, you simply calculate your next round of partial derivatives.
Then repeat, because the now the formula is dependent on the activation of the previous layer, which you can again substitute in, etc! I’m not gonna get totally into the weeds memorizing the exact math.
New simple and valuable thing to remember: The chain rule is just dy/dx = dy/du*du/dx, so it makes sense that dLoss/dSecondLayer = dLoss/dFirstLayer * dFirstLayer/dSecondLayer. And that shows clearly how gradients are based on past ones, and are eventually long chains of multiplied gradients (which could lead to vanishing gradients)
What is one-hot encoding? Why is it needed for neural networks?
Basically if you have a categorical variable with N>2 outputs, you’ll represent each row’s value of that variable wth N columns, each pertaining to one of the N categories. There’ll be a 1 for the category in that row, and 0s otherwise.
You need to one-hot encode because NNs need numerical inputs, so they can do computations by multiplying input vectors by weight matrices, and use derivatives of numerical formulas to optimize.
Why is the activation function important?
Without a nonlinear activation, you would just be learning a bunch of complex weighted sums of the inputs; it would be all linear. Nonlinear activations let you learn nonlinear relationships, which is where the magic happens.
How are log loss and cross entropy loss related? How do they work?
New:
Remember the specifics here: it’s the sum of the negatives of isCorrect*log(predictedProb) for each class.
So a term only has weight if it’s the prob for the correct label (I had misremembered it as all the other ones have weight, not that one.)
And log(1)=0, log(decimal) = big negative number. So if you predict low for the truth, you get a big negative log value, then take its negative to get a big positive loss, as desired.
I’m confident this is the case.
Original:
Log loss (also called binary cross entropy) is for a binary categorical and cross entropy is 3+ outcomes, but they’re basically the same thing; it’s like sigmoid vs softmax.
These loss functions are just using negative log likelihood. So we are trying to find the maximum likelihood estimation of the best parameters: we try to find the parameters such that “the likelihood that those parameters, and the associated probabilties they yield, would have resulted in this dataset” is maximized.
So like, when we’re predicting a categorical variable, our model’s output is a bunch of probabilities. We want to get those probabilties close to being 1 for the correct answer and 0 for everything else, because that is the maximum likelihood solution: those are the probabilties that are most likely to have yielded this label, and thus the parameters associated with that probability are most likely to yield that label.
What’s the formula for log likelihood, aka binary cross entropy?
Hopefully this isn’t that important to memorize if you’ve got the concept

What final activation is typically used, and what loss function is typically used, for predicting a binary categorical variable?
What about a categorical with 3+ options?
Activation is sigmoid, loss is BCE.
For 3+, activation is softmax, loss is cross entropy.
Why is it important to normalize all of your input columns?
So all of the input columns have the same scale, making it easier to learn at approximately the same rate (and using the same learning rate parameter) for each input.
If one col had a really big scale and another had a really small scale, then a step that’s as large as the learning rate will be hard to get right for both columns: you might have a too-big step for the small-scale one, and vice versa.
What is the learning rate?
When would you decrease the learning rate? When would you increase it?
The learning rate is a positive scalar that determines how large of a step you take in the opposite direction of the gradient each time you take a step.
You would increase it if you’re learning too slowly, and decrease it if you’re underfitting or if your learning is jagged.
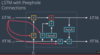
What is dropout regularization? Why does it work as a regularization tactic?
Dropout regularization is when we give nodes in the network a probability that they will be turned off on a training pass. So each time the model is run during training, we look at each node that might turn off, and if we pull the appropriate random number, set it to zero for this training run.
So for every training evaluation, we’re using a random subset of the nodes; the other nodes, and by extension their incoming and outgoing connections, are removed. (We don’t do dropout during validation or testing.)
My intuitive understanding of why it works for overfitting: first of all, it on average decreases the size of the model during training, and smaller/less complex models overfit less.
Also, because the model cannot consistently rely on having a specific node on a given run, it’s harder to, say, encode in one specific training point’s outcome variable in one specific node. Like if for example the model were trying to encode each training point’s individual outcome variable using one node each, that wouldn’t work super well with high dropout.
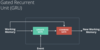
What causes vanishing gradients in neural networks, especially deep neural networks?
Certain activation functions have areas where their derivatives are very near zero: for example, the extreme values of sigmoid. So if all or most of the neurons get to the extreme values of sigmoid, the gradients will have a lot of very-near-zero values, which causes very slow training.
This is exacerbated by the fact that derivatives in NNs are often basically the the product of several of these individual derivatives, chained together by the chain rule. So you’ve got a bunch of near-zero values multiplied together.
Intuitively, why does using the relu activation function combat vanishing gradients, and exploding gradients?
A derivative in an NN is usually a bunch of individual derivatives of the activation function multiplied together, because of the use of the chain rule in backpropogation.
If the activation derivative tends to often be less than 1 (as with the extremes of sigmoid), these derivatives will tend to zero, and vanish. If they often to be greater than 1, they will tend to infinity and explode.
But the derivative of relu is always either zero or 1. So the product of a bunch of the derivatives will be either zero and 1, but some of them will typically be 1, because the network will need some info flowing through for each point. So there are usually always some gradients that aren’t vanishing and aren’t exploding
How do you get the best of both worlds of normal gradient descent and stochastic gradient descent
Stochastic batch gradient descent: take a step every batch of k datapoints, rather than every 1, or just every epoch. Super common
Why is learning rate decay useful?
Usually we want to take large steps at the beginning and slow steps at the end: at the end we’re near a local minimum and just want to slightly refine, where as at the beginning we probably have quite a ways to go.
How does momentum work, and what purpose does it attempt to solve?
In momentum, rather than taking a step in the direction of the current gradient, you take a step in the direction of an exponentially decaying weighted sum of all past gradients.
The hope is that it helps you “power through” local minima to reach global minima. So for example, if you got to the bottom of this local minimum, the current gradient would be zero, but the previous ones are still pointing right and would carry you through.
Another benefit is that momentum helps decrease jagged training. If the objective function is pointing in a consistent direction in one dimension (long side of ovals below), but prone to jumping around on another one (short side of ovals below), momentum smoothes this out.

What little optimization can often be made to the pairing of softmax output and cross entropy loss?
Rather than having softmax output probabilities, have it output the logs of the probabilties, and alter cross entropy to recieve them. As we know, optimizing based on the logs achieves the same optimization, and is often more computationally effective.
What is a good default approach to randomly initializing the weights and baises of an NN?
Init biases to zero; this is just super common.
Weights: when choosing outgoing weights from a layer with n nodes, we sample weights from a normal distribution with mean zero and stddev 1/sqrt(n)
The general idea is to have the weights inversely proportional to the # of nodes in the previous layer, and thus inversely proportional to the number of weights.
Intuitively, we can say that by doing it proportionally to the number of nodes that are feeding into the next layer, the inputs to the next layer aren’t too big or small, and they aren’t really dependant on the # of weights. But this is super hand-wavey, so I feel fine basically just saying “experimentally, this works really well.”
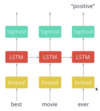
What are word embeddings?
A set of word embeddings is a mapping from each word in your vocabulary to a vector of a fixed length, say 768 (much shorter than your vocab size), where each word’s embedding contains meaningful information about the word’s meaning, its grammatical function, its relationship to other words, etc.
What is one potential danger of word embeddings?
Retaining the biases of the training data. For example, the embedding for “homemaker” might be closer to “woman” than “man”. Debiasing strategies become important for this reason.