Pattern recognition in FFFNs Flashcards
Understand hierarchical processing in feed forward neural networks.
When is a network “feed forward”?
When neurons are connected only to downstream neighbors. For example, a “chain of neurons” 1>2>3 is feed forward.
What is a perceptron and what does this network architecture look like?
The perceptron is an algorithm for supervised learning of binary classifiers in a feed-forward neural network. The perceptron is a linear classifier, it can decide whether an input vector belongs to a specific class by being trained.

What is the perceptron XOR problem?
The fact that a one-layer perceptron cannot learn an “exclusive or” (XOR) logical function.
A one layer-perceptron can only produce linear separation boundaries.
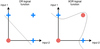
What is the role of convolutional layers?
Convolutional layers regularly extract features across an entire input.
These features can be used in hierarchies to recognize patterns.

The convolution is performed on the input data with the use of a filter or kernel (these terms are used interchangeably) to then produce a feature map. We execute a convolution by sliding the filter over the input. At every location, matrix multiplication is performed that sums the result onto the feature map.
This is a convolution operation. You can see the filter (the pink square) is sliding over our input (the blue square) and the sum of the convolution goes into the feature map (the red square). The area of the filter is also called the receptive field. The size of this filter is 3x3. The fact that one filter is used for the entire image makes convolutional neural networks very location-invariant and prevents them from overfitting. This means they are able to recognize features independent of their location in the input image.
Numerous convolutions are performed on our input, where each operation uses a different filter. This results in different feature maps. In the end, we take all of these feature maps and put them together as the final output of the convolution layer.
What is the role of Regularization?
Regularization is a loss term that keeps network structure simple connections.
The loss is calculated by adding the regularization term to the error. By doing this, regularization discourages the complexity of the model. Reducing weights to a value close to zero will decrease the loss and simplify the model. This helps to prevent overfitting.
What is the difference between regression and classification?
Classification: is about predicting a label (discrete class/category)
Regression: predicting a quantity (numerical value) given inputs.
What is overfitting?
Overfitting is a phenomenon that occurs when a machine learning or statistics model is tailored to a particular training dataset and is unable to generalize to unseen data.
How does the perceptron algorithm work?
(1) Initialize the w, b parameters at 0
(2) Keep cycling through the training data (x, y)
(3) If y(w*x+b)<=0 (a point is misclassified):
I. increase the value of w by y*x
w = w + y*x
II. increase the value of b by y
b = b+y
Describe the behavior and significance of the rectified linear unit (ReLU) function.
ReLU is a nonlinear activation function.
It returns an output of zero for negative input and returns as output the value x for any positive input x (see the figure).
Therefore, it allows for nonlinearity.
Any relationship or function can be roughly estimated by aggregating many ReLU functions together.

Why do deep networks need non-linear units?
Without the non-linearity a deep feedforward network can be reduced to a single layer.
How are convolutional neural networks shift-invariant?
Shifts in the input layer leave the output relatively unaffected.
What does it mean that images are discrete (digital)?
They are not continuous, they have pixels.
In the context of image processing, what is filtering?
Forming a new image whose pixels are some function of the original pixel values.
When can we say that a convolutional filter is a linear system?
When summing two pictures and applying the filter leads to the same result as applying the filter to both pictures individually and summing the filtered pictures together.
F(Image1+Image2) = F(Image1)+F(Image2)
(the superposition principle)

Is a threshold-based image segmentation filter linear?

NO

Threshold is not a linear transformation, as it ‘loses’ information.
Let’s test it: is the result of applying a threshold to the sum of two images equal to applying a threshold to each image sepparately and summing?
F(Image1+Image2) =? F(Image1) + Image(2)
Answer: in general, No.
In other words, the superposition principle does not hold with threshold-based filters.
What is an invariance?
Give 2 examples.
Some “essence” of “something” - some property of something that stays the same after a transformation.
For example:
- Time invariance in word recognition: shows time invariance - we can recognize words irrespective of the time we hear them.
- Luminance invariance in shape recognition: we can recognize shapes despite variances in luminance.
- Space invariance in odor recognition: we can recognize odors irrespectively of where we smeel them,
Can single neurons invariantly represent higher-level concepts?
YES (with caveats)
Some researchers have encountered single neurons that respond invariantly to higher-level concepts (such as the Jennifer Aniston neuron), and not to anything else.
Modern research shows that this is better described by a multidimensional feature space.
Describe a Machine Learning (ML) problem?
An ML problem is a set of choices:
(1) a dataset - what goes in?
(2) a model - what does the job?
(3) a cost function - how incorrect is the model?
(4) an optimization procedure - how to improve?
How is the visual system organized?
Hiearchically*
From low level simple features to high level complex features.
The visual system, as well as convolutional neural networks, break the problem of object recognition in the problem of feature decomposition, with the lower levels having simpler features and higher levels combining more complex features.
Recurrent connections do exist in the visual system.
How are convolutional networks like networks in the visual system?
The visual system, as well as convolutional neural networks, break the problem of object recognition in the problem of feature decomposition, with the lower levels having simpler features and higher levels combining more complex features.
