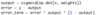Neural Networks Flashcards
(132 cards)
How to separate Test, Train and Validation Data
Separate base data set into 6 components
- Train Features
- Train Targets
- Validation Features
- Validation Targets
- Test Features
- Test Targets
Pic just shows training and test

What is logistic regression?
Outputs a probability that a given input belongs to a certain class
Explain the softmax function, why use e?
Turns scores(integers which reflect output of neural net) into probabilities
e turns negatives into positives

Explain why sigmoids are no longer used as an activation function
- Derivatives of sigmoid max out a .25, thus, during backprop, errors going back into the network will be shrunk by 75% -100% at every layer
- For models with many layers, as you get closer to layers near input, weight updates will be tiny and take a long time to train
- Not zero centered(More inconvenience) - feeds only positive value to next layer, in turn, gradient of weights of this input value X will be always positive or always negative, depending on the gradient of the whole expression f. This leads to undesirable zig-zagging of gradient updates for the weights

Explain why Relu is used as an activation function
- If max is positive, then derivative is 1, o there isn’t the vanishing effect you see on backpropagated errors from sigmoids.
- Leads to faster training
Drawbacks of Relu
- Large learning rate, coupled with a large gradient, may lead to respectively large negative adjustment of weights and biases(our step down)
- Adjustment may lead to a negative input into the Relu caculation. Negative = 0 for Relu. During backprop, the derivative of zero is zero, so chain rule leads to a zero update. This leads to a “dead” neuron which may waste computation and reduce learning
- Its very hard if not impossible to input a large positive adjustment(to counter the earlier), since we are moving down to a local minimum. Not sure if this would even matter mathimatically, but may help if taken in a batch view
Training Loss
Average cross-entropy loss
S = Softmax, D = Cross-Entropy, L = Loss

When performing numerical optimization, what are good things to do with variables
- Mean of zero
- Equal Variance
This minimizes search performed by optimizer

For images, how to you prepare your data for optimization
take each channel, subtract 128 and divide by 128. Doesn’t change the data, just makes it easer for numerical optimization

discuss gaussian distribution and sigma
- mean zero and standard deviation sigma.
- sigma determines order of magnitude for outputs at inital point of optimization
- Beaucse softmax sits ontop of sigma, the order of magnitude also determiness peakiness of inital probability distribution
- Large sigma = uncertain, large peaks
- Small sigma - Opinionated, small peaks -
For optimization, what are basic ideas on how to initialize weights and biases
start from gaussian distribution with small sigma. Small sigma means more certain.
What are the 3 sets of data used to measure performance and how are they used
- training - optimize loss
- validation - measure performance of training
- test - never use until final measurments
Explain Stochastic Gradient Descent
- Average loss for very small random fraction of training data
- This average loss is typically a bad estimate at first and may actually increase error
- Thus, you do it many times, taking small steps each time
Explain Momentum
Use running average of gradients as directio to take, instead of gradient in current batch
Explain learning rate decay
decreasing the learning rate over time during the training process(every time it reaches a plateau, exponential decay
What is ADAGRAD
- modification of SGD which implicity does momentum and learning rate decay by default
- Makes learning less sensitive to hyperparameters
Whats a scalar
single value that represents a zero dimension shape(1, 2,4, -0.3)
Whats a vector
a single dimesion shape with a certain length

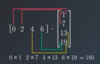
What is a matrix and how do you describe it?
2 dimensional grid of values. If had 2 rows and 3 columns, its a 2x3 matrix

describe a vector as a matrix
1x len matrix.
describe indices of a matrix
row then column index

How to reshape vectors from horizontal to vertical
Less common way

More common way of reshaping data

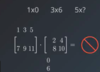
Describe element-wise operations within Matrix