Epi - Comp Exam Flashcards
(196 cards)
What is Descriptive Epidemiology?
Distribution of Disease
Who/When/Where
- Frequencies of disease occurrences.
- Counts and their relation to size of population.
- Patterns of disease occurances:
- Encompasses person place and time.
What is Analytic Epidemiology?
Determinants of Disease
Associations vs. Causes (Causation)
Why/How
- Factors of susceptibility/exposure/risk
- Etiology/causes of disease
- Mode(s) of transmission
- Social/environmental/biologic elements that determine the ocurrence/presence of disease.
What are the 6 core functions of epidemiology?
- Public health surveillance
- Field investigation
- Analytic studies
- Evaluation
- Linkages
- Policy development
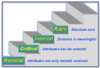
What is an epidemic?
Occurance of disease clearly in excess of normal expectancy with community/period clearly defined.
What is an outbreak?
An epidemic limited to a localized increase in the occurance of disease. Sometimes interchanged with ‘cluster.’
What is an endemic?
The constant presence of a disease within a given area or population in excess of normal levels in other areas.
What is an emergency of international concern?
An epidemic that alerts the world to the need for high vigilance (pre-pandemic labeling).
What is a pandemic?
An epidemic spread world-wide (global health impact), could be multi-national or multi-continent.
What is Incidence Density?
Incidence Rate when summed over multiple time periods.
What is Point Prevalence?
Prevalence at a given point in time.
What is Period Prevalence?
Prevalence over a given period of time.
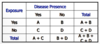
What is a Crude Morbidity Rate?
of Persons with Disease / # of Persons in Population
What is a Crude Mortality Rate?
of Deaths (all causes) / # of Persons in Population
What is a Cause-Specific Morbidity Rate?
of Persons with cause-specific disease / # of Persons in Population
What is a Cause-Specific Mortality Rate?
of Cause-Specific Deaths / # of Persons in Population
What is a Case-Fatality Rate?
of Cause-Specific Deaths / # of Cases of Disease
What is a Cause-Specific Survival Rate?
of Cause-Specific Cases Alive / # of Cases of Disease
What is a Proportional Mortality Rate (PMR)?
of Cause-Specific Deaths / total # of Deaths in Population
What is a Live Birth-Rate?
of Live Births / 1000 Population
What is a Fertility Rate
of Live Births / 1000 women of childbearing age (15-44)
What is a Neonatal Mortality Rate?
of deaths in those <28 days of age / 1000 live births
What is a Postnatal Mortality Rate?
of deaths in those between 28 days and 1 year of age / 1000 live births
What is an Infant Mortality Rate?
of deaths in those < 1 year of age / 1000 live births
What is a Maternal Mortality Ratio?
of female deaths related to pregnancy / 100,000 live births