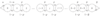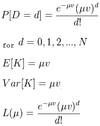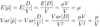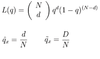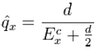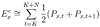CT4 - Models & Mortality Flashcards
(86 cards)
What is a G Test?
G-tests are likelihood-ratio or maximum likelihood statistical significance tests that are increasingly being used in situations where chi-squared tests were previously recommended.
The G test is undertaken in the same way as a chi-squared test, with the same degrees of freedom.
If Oi is the observed frequency in a cell, E is the expected frequency on the null hypothesis, and the sum is taken over all non-empty cells, G is calculated as:

How is a Pearson Residual Calculated?
For the Binomial mortality model (and thus approximately for the Poisson model), the Pearson residual is given by:

What are the GLM Link Functions for the following DBNs?
- normal
- exponential
- poisson
- binomial

Forward Selection Procedure for Levels of Nested Generalised Linear Models (GLMs)
Let Di be the deviance of the ith level model, where D0 is the deviance of the null model (G score, chi-squared or other with approx chi-squared dbn).
In turn test (Di - Di+1) against required significance level (normally 5%) in a chi-squared test with d.f. = 1.
If change in deviance is significant (i.e. p-value < 0.05), then this supports moving to the next level of model.
Define a Symmetric Simple Random Walk
(Used to model processes, such as the movement of stock market share prices)

A simple random walk operates on discrete time and has a discrete state space (i.e. set of all integers)
Define a Compound Poisson Process
A compound Poisson process is a continuous-time (random) stochastic process with jumps.
A compound Poisson proces operates on continous time. It has a discrete or continous state space depending on whether Yj are continuous or discrete.
Examples:
- Aggregate claims for an insurance portfolio (number of claims, each of potentially differing size)
- Total rainfall (number of drops, each of differing size)
- Total biomass (number of patches of organism, each patch of differing size)

What are the 12 Key Steps of Modelling
1. Objectives: Develop a clear set of objectives to model the relevant system or process, define its scope. This includes reviewing regulatory guidance.
- Plan and validate: Plan the model around the chosen objectives, ensuring that the model’s output can be validated i.e. checked to ensure it accurately reflects the anticipated output from the relevant system or process.
- Data: Collect and analyse the necessary data for the model. This will include assigning appropriate values to the input parameters and justifying any assumptions made as part of the modelling process.
- Capture the real world system: The initial model should be described so as to capture the main features of the real world system. The level of detail in the model can always be reduced at a later stage. Choose parameters
- Expertise: Involve the experts on the relevant system or process. They will be able to feedbacks on the validity of the model before it is developed further. Discuss worst cases and probabilities.
- Choose a computer program: Decide on whether the model should be built using a simulation package or a general purpose language.
- Write the model: Write the computer program for the model.
- De-bug the program. (e.g. test against particular scenarios)
- Test the model output: Test the reasonableness of the output from the model. The experts on the relevant system or process should be involved at this stage.
-
Review and amend: Review and carefully consider the appropriateness of the model in light of making small changes to the input parameters.
- e.g. test median outcomes against business plans
- e.g. check probabilities assigned to worst case scenarios
- Analyse output: Analyse the output from the model. Test sensitivity to small changes.
- Document and communicate: Communicate and document the results and the model.
What are the Benefits of Modelling?
-
Compressed timeframe
(e. g. for financial planning, real world figures unfold over a lifetime, need to test over a shorter period) -
Ability to incorporate randomness
(in stochastic models) - **Scenario testing **
(Can combine parameters in realistic scenarios - e.g. relating to interest rate rises) - Greater control over experimental conditions
-
Cost control
(upstream testing cheaper than assessment after implementation)
What are the Limitations of Modelling?
-
Time and cost
complex models are expensive to create -
Multiple runs required
for stochastic models, gives an indication of the dbn of outputs, but shows the impact of changes to inputs, rather than optimising outputs -
Validation and verification
Complex models are hard to relate back to the real world in sanity checking -
Reliance on data input
rubbish in, rubbish out -
Inappropriate use
Scope and purpose of model must be understood by client to avoid misuse -
Limited scope
models can’t cover all future eventualities, such as changes in legislation -
Difficulty intepreting outputs
results usually useful only relative to other results, not in absolute real-world terms
Continuous, Discrete and Mixed Type Processes
In a stochastic (random) process, a family of random variables Xt : t ∈ τ is disclosed over time, t
In a discrete process, τ = {0, 1, 2, … }
= Z (natural, or counting numbers)
e.g. number of claims made
In a continuous process, T = R (real numbers), or [0,∞]
e.g. stock price fluctuations
A counting process Nt, is the number of events by time period t, where Nt is a non-decreasing integer and N0 = 0
An example of a mixed type process, including both continuous and discrete elements, is the market price of coupon-paying bonds - the bonds change price at specific times in response to coupons being paid, but also change continually due to market.
What is the Markov Property?
A process with the Markov property will be one in which the future development of the process may be predicted on the basis of the current state of the system alone, without reference to it past history.
If a stochastic process Xt is defined on a state space S and time set t ≥ 0, the Markov property is expressed mathematically as:
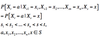
Prove the Chapman-Kolmogorov Equations for n-step transitions
The Chapman-Kolmogorov Equations provide a way of calculating n-step transition probabilities through matrix multiplication of single-step transitions. The proof is as follows:
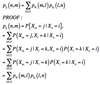
How do you Calculate the
n-Step probability using the Chapman Kolmogorov equations?
If αj0 is the initial probability distribution,

Conditions for a Stationary Distribution in a Markov Chain
In a Markov chain, the distribution of Xn may converge to a limit π, such that
P(Xn= j | X0= i) → πj
Regardless of the starting point - this is known as a stationary distribution
- πj = Σπipij *for all i ∈ S
- A Markov chain with a finite state space has at least one stationary probability distribution}
- An irreducible Markov chain with a finite state space has a unique stationary probability distribution
Time Inhomogeneous / Homogeneous Markov Chains
A Markov chain is called time-homogeneous if transition probabilities do not depend on time.
Where they do depend on time (e.g. risk for drivers at a particular age, or at a particular length of time after qualifying), a Markov Chain is called time-inhomogeneous.
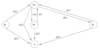
Simple No Claims Discount (NCD) Model
No Claims Discount (NCD)
Policy holders start at 0% level
No claim in year moves up one level (or stays at top)
Claim in year moves down one level (or stays at bottom)
e.g:
Consider a no claims discount (NCD) model for car-insurance premiums. The insurance
company offers discounts of 0%, 30% and 60% of the full premium, determined by the following rules:
- All new policyholders start at the 0% level.
- If no claim is made during the current year the policyholder moves up one discount level, or remains at the 60% level.
- If one or more claims are made the policyholder moves down one level, or remains at the 0% level.
Transition graph shown below:

# Define Transition Intensities *q<sub>ii</sub>(t), q<sub>ij</sub>(t)* for Markov Jump Processes

Define Kolmogorov’s Forwards Equation for Markov Jump Processes

Define Kolmogorovs Backwards Equation for Markov Jump Processes

Distribution of Holding Times (Markov Jump Process)
Poisson process characterised by unit upward jumps - hence path fully characterised by times between jumps.
Distribution of Holding Times is Exponential with Parameter λ, in case of Poisson, and μ, in case of non-Poisson Markov Process.

Define Residual and Current Holding Times for Markov Jump Processes

What is the Survival Model?
The survival model is a two state Markov chain, with a state space of S = { A, D } (alive / dead). There is single transition rate μ(t) - identified with the force of mortality at age t

What is the Sickness-Death Model?
An extension of the survival model, with three states - healthy (H), sick (S) or dead (D). S = { H, S, D }

What is the Long Term Sickness Model?
The so-called long term care model is a time-inhomogeneous model where the rate of transition out of state S (sickness) will depend on the current holding time in state S.