Behavioral Science Flashcards
(64 cards)
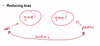
Look at the operator curve.

Curve A
This is b/c the sensitivity of the curve rises quickly when the specificity is close to 1. Specificity close/equal to 1 means it is a specific test. So, 1-specificity = 1-1 =0, so you want a high sensitivity close to the origin of the chart.
This means that the curve A test can predict well between disease and non-disease states.
Note: curve C has no predictive value

What diagnotic tools vary with prevelance of the disease? Which do not?
PPV & NPV vary depending on the prevalence of the disease.
Specificity and Sensitivity do NOT vary with the prevalence of the disease.
How do PPV and NPV vary with the prevalence of the disease?
PPV is directly proportional to the prevalence of disease (ie when prevelance is high, the positive predictive value is high as well)
NPV is indirectly proportional to the prevalence of the disease (ie when prevalence is high, the negative predictive value is low)
“NPV is Not Proportional to preValence”

Specificity = TN/(TN+FP) = 108/120 = 0.9
NOTE: Easy to visualize if you draw a 2x2 square

Answer: 41%
How’d we get there?
There is a 0.9 chance of a test being true negative, and 0.1 chance of the test being a false positive. Each test is an independent event –>
probability of all 5 tests being negative = 0.9^5 = ~0.59
Now, we’re looking for the probability that one of the tests will not be positive or in other words not all the tests are negative –>
probability of not all 5 tests are neg = 1 - (0.9^5) = ~0.41
This means there is a 41% chance of having a positive test even if the patient does NOT have prostate cancer.


Sensitivity and specificity will be the same in either country b/c they are inherent to the test and are not effected by prevalence of disease.
PPV will be higher in China than US b/c higher prevalence in China
NPV will be lower in China than US b/c higher prevalence in China
WHat is the equation to determine incidence?
Incidence = # of new cases/ total population at risk of becoming a new case during a specific time frame
Note: Those at risk would NOT include those who already have the disease or those who have had the disease and can not catch it again (ie chickenpox)
Incidence x disease duration = ?
Prevalence ~= incidence x disease duration
So:
- *In chronic diseases the prevalence > incidence** (b/c there are a lot of previously aquired cases that incidence doesn’t acount for)
- *In acute (short-lived) diseases the prevalence ≈ incidence** (b/c most cases are new cases)
Odds ratio = ?
Odds ratio = odds of exposure with disease/odds of exposure without disease = (a/c)/(b/d) = (ad)/(bc)
odds of exposure w/ disease = a/c
odds of exposure w/o disease = b/d
Note: Odds ratio approximates relative risk when the prevalence is low.
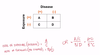
What observational study uses odds ratio as a measure?
Case-control study
What observational study uses relative risk as a measure?
Cohort study
What does odds ratio asks?
What is the likelihood that a person w/ a disease had a certian exposure?
If the exposure is a potent cause of a disease the odds ratio will be much higher than 1.
What does relative risk ask?
What is the probablity of getting a disease in the exposed group when compared to those in the unexposed group?
relative risk =?
relative risk = fraction of those with disease who were exposed to the risk factor/fraction of those with disease who were NOT exposed to the risk factor
= [a/(a+b)]/[c/(c+d)]

relative risk reduction measures what?
Relative risk reduction measures the proporiton of risk reduction attributable to the intervention as compared to the control.
Relative risk reduction =?
RRR = 1 - relative risk
Remember, RR = [a/(a+b)]/[c/(c+d)]
What’s the difference between Absolute Risk Reduction and Relative Risk Reduction?
Relative Risk Reduction is a proportion (RRR = 1 - RR)
Absolute Risk Reduction is a difference (ARR = Attributable Risk of the control – Attributable Risk of the intervention = (c/[c+d]) – (a/[a+b])
**Remember: **
Attributable Risk = Incidence in exposed group (%) – Incidence in unexposed group (%) = (a/[a+b]) – (c/[c+d])
Precision =?
Precision is the The consistency and reproducibility of a test (sometimes referred to as the reliability).

With precision there is the absence of random variation in a test –> Random error/variation decreases the precision of a test
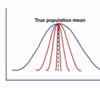
Accuracy =?
Accuracy is measures how close test measurements are to the true values (sometimes referred to as validity)
With accuracy is the absence of systematic error or bias in a test –> systemic error decreases accuracy of a test

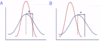
Systematic error does what?
Systematic error reduces accuracy of a test by consistently skewing the results in a particular direction decreasing the validity


Answer is D - it has low accuracy and high precision due to systematic error.
You know it is low accuracy b/c the values are more than 30% above the gold standard value. They are precise b/c the values are clustered closely together.
What is bias?
Bias is when an outcome is systematically favored over another –> causes systematic error (which reduces the accuracy of a study)
Name 3 types of selection bias? At what phase in the study does selection bias occur?
- Berkson bias—study population selected from hospital is less healthy than general population
- Healthy worker effect—study population is healthier than the general population (ie ACL tears in competitive athletes)
- Non-response bias— participating subjects differ from nonrespondents in meaningful ways
**Selection bias occurs during the recruitment phase. **
What is a crossover study and why is it useful?
A cross over study is a study where the subjects act as their own controls. This is done by having 1 group as the control and the other as the exposed/experimental and then at some point in the study switching the two groups. So when comparing a patient rather than comparing them to a non-matched random person in the control group, you compare them to themselves when they were being treated as a control (ie w/ placebo, etc.)
This is particularly useful when trying to decrease the likelihood of a confounding bias.