7_BigQuery Flashcards
(30 cards)
BigQuery Basics
- Peta-byte scale, serverless, highly-scalable cloud entreprise data warehouse.
- In-memory BI Engine (BigQuery BI Engine).
- Accepts batch and streaming loads.
- Machine learning capabilities (BigQuery ML).
- Support for geospatial data storage and processing.
BigQuery Key Features
- High Availability: Automatic data replication to multiple locations with availability.
- Supports Standard SQL: BigQuery supports a standard SQL dialect which is ANSI:2011 compliant.
- Federated Data: BigQuery able to connect to, and process, data stored outside of BigQuery (external sources).
- Automatic Backups: BigQuery automatically replicates data and keeps a seven-day history of changes.
- Governance and Security: Fine-grained identity and access management. Data encrypted at rest and in transit.
- Separation of Storage and Compute: Leads to a number of benefits including ACID-compliant storage operations, cost-effective scalable storage and stateless resilient compute.
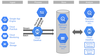
BigQuery Structure
-
Project: contains users and datasets.
- Use a project to:
- Limit access to datasets and jobs
- Manage billing
- Use a project to:
-
Dataset: contains tables/views
- Access Control Lists for Reader/Writer/Owner
- Applied to all tables/views in dataset
-
Table: collection of columns
- Columnar storage
- Views are virtual tables defined by SQL query
- Tables can be external (e.g. on Cloud Storage)
-
Job: long running action/query that is run in BigQuery on your behalf (asynchronously)
- Can be cancelled

BigQuery Jobs
- Jobs (queries) can scale up to thousands of CPU’s across many nodes, but the process is completely invisible to the end user.
- Storage and compute are separated, connected by petabyte network.
-
4 types of jobs:
- Load
- Export
- Query
- Copy
-
Query job priority:
- Interactive: Default. Queries are executes asap. Results always saved to either Temporary or Permanent table.
- Batch: Queries are executed when there are idle resources. If not executed within 24 hours, then it becomes interactive.

Table Storage
-
Capacitor columnar data format
- Each column in a separate, compressed, encrypted file that is replicated 3+ times
- No indexes, keys or partitions required
- For immutable, massive datasets
- Separates records into column values, stores each value on different storage volume.
- Traditional RDBMS stores whole record on one volume.
- Extremely fast read performance, poor write (update) performance - BigQuery does not update existing records.
- Not transactional.
- Table schemas specified at creation of table or at data load.

BigQuery Capacitor
Capacitor storage system
- Proprietary columnar data storage that supports semi-structured data (nested and repeated fields).
- Each value stored together with a repetition level and a definition level.
- Repetition level: the level of the nesting in the field path at which the repetition is happening.
- Definition level: how many optional/repeated fields in the field path have been defined.

IAM
- Control by project, dataset, table/view (table level since June 2020)
- Roles:
-
Basic: grant access at Project level
- Owner, Editor, Viewer
-
Predefined:
- Admin, User: Project level
- Data Owner, Data Editor, Data Viewer: Table/View level
- Custom: user managed
-
Basic: grant access at Project level
https://cloud.google.com/bigquery/docs/access-control
https://cloud.google.com/bigquery/docs/share-access-views

Denormalisation
- BigQuery performance optimised when data is denormalised appropriately
- Nested and repeated columns
- Maintain data relationships in an efficient manner
- RECORD (STRUCT) data type

Data Ingest Solutions: CLI, web UI, or API
Load and Read Data
Load:
- CSV
- JSON (Newline delimited)
- Avro - best for compressed files
- Parquet
- ORC
- Datastore backups/exports
Read:
- From external source:
- Cloud Storage
- Cloud Bigtable
- Google Drive
- Data format:
- CSV
- JSON (Newline delimited)
- Avro
- Parquet

Three ways of loading data into BigQuery

External Sources
Use cases:
- Load and clean data in one pass from external, then write to BigQuery
- Small amount of frequently changing data to join to other tables
Limitations
- No guarantee of consistency
- Lower query performance
- Cannot use TableDataList API method
- Cannot run export jobs on external data
- Cannot reference in wildcard table query
- Cannot query Parquet or ORC formats
- Query results not cached
- Limited to 4 concurrent queries
- Cannot import directly from Cloud SQL, need to build a pipeline for that
https://cloud.google.com/bigquery/external-data-sources
https://cloud.google.com/bigquery/docs/cloud-sql-federated-queries
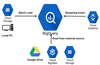
Data Transfer Service
- Import data to BigQuery from other Google advertising SaaS applications.
- Google AdWords
- DoubleClick
- YouTube reports
https://cloud.google.com/bigquery-transfer/docs/introduction
Exporting Tables
- Can only export to Cloud Storage
- Can copy table to another BigQuery dataset
- Export formats: CSV, JSON, Avro
- Can export multiple tables with command line
- Can only export up to 1Gb per file, but can split into multiple files with wildcards
- Use Dataflow to read data from BigQuery instead of manually exporting it if you need scheduled exports.
Schema Modification
BigQuery natively supports the following schema modifications:
- Adding columns to a schema definition
- Relaxing a column’s mode from REQUIRED to NULLABLE
It is valid to create a table without defining an initial schema and to add a schema definition to the table at a later time.
All other schema modifications are unsupported and require manual workarounds, including:
- Changing a column’s name
- Changing a column’s data type
- Changing a column’s mode (aside from relaxing REQUIRED columns to NULLABLE)
- Deleting a column
Streaming data into BigQuery
Instead of using a job to load data into BigQuery, you can choose to stream your data into BigQuery one record at a time. This approach enables querying data without the delay of running a load job. But enabling streaming on BigQuery is not free.
If you have an app that collects a large amount of data in real-time, streaming inserts can be a good choice. Generally, these types of apps have the following criteria:
- Not transactional. High volume, continuously appended rows. The app can tolerate a rare possibility that duplication might occur or that data might be temporarily unavailable.
- Aggregate analysis. Queries generally are performed for trend analysis, as opposed to single or narrow record selection.
Views
- Virtual table defined by a query
- Contains data only from query that contains view
- Control access to data
- Giving a view access to a dataset is also known as creating an authorized view in BigQuery. An authorized view allows you to share query results with particular users and groups without giving them access to the underlying source data
- When making an authorized view in another dataset, both the source data dataset and authorized view dataset must be in the same regional location.
- You can also control access to tables and views with access control set at the table level, within the same dataset.
- Reduce query complexity
- Constructing logical tables
- Ability to create authorized views
Views limitations:
- Cannot export data from a view
- Cannot use JSON API to retrieve data from a view
- Cannot combine standard and legacy SQL
- No user defined functions
- No wildcard table references

Cached Queries
BigQuery writes all query results to a table. The table is either explicitly identified by the user (a destination table), or it is a temporary, cached results table. Temporary, cached results tables are maintained per-user, per-project. There are no storage costs for temporary tables, but if you write query results to a permanent table, you are charged for storing the data.
Query results are not cached:
- When a destination table is specified
- If any of the referenced tables or logical views have changed since the results were previously cached
- When any of the tables referenced by the query have recently received streaming inserts (a streaming buffer is attached to the table) even if no new rows have arrived
- If the query uses non-deterministic functions; for example, date and time functions such as CURRENT_TIMESTAMP() and NOW(), and other functions such as CURRENT_USER() return different values depending on when a query is executed
- If you are querying multiple tables using a wildcard
- If the cached results have expired; typical cache lifetime is 24 hours, but the cached results are best-effort and may be invalidated sooner
- If the query runs against an external data source
Wildcards
- Use backticks ` , not single quote ‘
- Query across multiple, similarly named tables
- FROM
project.dataset.table_prefix*
- FROM
- Filter using _TABLE_SUFFIX in WHERE clause:
- FROM
project.dataset.table_prefix*WHERE _TABLE_SUFFIX BETWEEN ‘29’ and ‘35’
- FROM
- Filter using TABLE_DATE_RANGE:
- FROM (TABLE_DATE_RANGE([mydata.], TIMESTAMP(‘2014-03-19’), TIMESTAMP(‘2015-03-21’)))
- The legacy SQL TABLE_DATE_RANGE() functions work on tables that conform to a specific naming scheme: YYYYMMDD, where the represents the first part of a table name and YYYYMMDD represents the date associated with that table’s data.
- In standard SQL, an equivalent query uses a table wildcard and the BETWEEN clause.
- Filter using TABLE_QUERY.
- The legacy SQL TABLE_QUERY() function enables you to find table names based on patterns. When migrating a TABLE_QUERY() function to standard SQL, which does not support the TABLE_QUERY() function, you can instead filter using the _TABLE_SUFFIX pseudo column.
-
Limitations:
- The wildcard table functionality does not support views.
- Currently, cached results are not supported for queries against multiple tables using a wildcard even if the Use Cached Results option is checked. If you run the same wildcard query multiple times, you are billed for each query.
- Wildcard tables support native BigQuery storage only. You cannot use wildcards when querying an external table or a view.
https://cloud.google.com/bigquery/docs/querying-wildcard-tables
Partitioned & Sharded Tables
- Table divided into segments known as “partitions”
- Query only certain rows (partitions) instead of entire table
- Limits amount of read data
- Improves performance
- Reduces costs
- You can partition BigQuery tables by:
- Ingestion time: Tables are partitioned based on the data’s ingestion (load) time or arrival time.
- Date/timestamp/datetime: Tables are partitioned based on a TIMESTAMP, DATE, or DATETIME column.
- Integer range: Tables are partitioned based on an integer column.
- Why not use multiple tables plus wildcards instead?
- Limited to 1000 tables per dataset
- Bring tables number below 1000 to query all of them at once.
- Merge tables, then use table partitioning to divide single tables into segments (called partitions)
- Substantial performance drop vs. a single table
- Limited to 1000 tables per dataset
- As an alternative to date/timestamp/datetime partitioned tables, you can shard tables using a time-based naming approach such as [PREFIX]_YYYYMMDD. This is referred to as creating date-sharded tables.
Partition Types
-
Ingestion Time partitioned tables
- Partitioned by load or arrival date
- Data automatically loaded into date-based partitions (daily)
- Tables include the pseudo-column _PARTITIONTIME
- Use _PARTITIONTIME in queries to limit partitions scanned
-
Partitioning based on specific TIMESTAMP or DATE column
- Data partitioned based on value supplied in partitioning column
- 2 additional partitions:
- __Null__
- __UNPARTITIONED__
- Use partitioning column in queries
Clustered Tables
- Taking partitioned tables “to the next level”
- Similar to partitioning, divides table reads by a specified column field
- Instead of dividing dy date/time, divides by field
Limitations:
- Only (currently) available for partitioned tables
- Standard SQL only for querying clustered tables
- Standard SQL only for writing query results to clustered tables
- Specify clustering columns only when table is created
- Clustering columns cannot be modified after table creation
- Clustering columns must be top-level, non-repeated columns
- You can specify 1 to 4 clustering columns
Querying Clustered Tables:
- Filter clustered columns in the order they were specified
- Avoid using clustered columns in complex filter expressions
- Avoid comparing clustered columns to other columns

Slots
- Computational capacity required to run a SQL query
- Play a role in pricing and resource allocation.
- Choice of using an on-demand pricing model or a flat-rate pricing model
- The flat-rate model gives you explicit control over slots and analytics capacity, whereas the on-demand model does not.
- Number of slots per query depends on its complexity:
- Query size = amount of data processed by the query.
- Query complexity = amount of data that is shuffled during steps of query.
- BigQuery automatically manages slots quota.
- View slots usage using Stackdriver monitoring.
- Default, on-demand pricing allocates 2000 slots
- Only an issue for extremely complex queries, or a high number of simaltaneous users.
- If more than 2000 slots required, switch to flat-rate pricing - purchase fixed number of slots.
Logging and Monitoring
Stackdriver Monitoring and Logging differences
- Monitoring = performance/resources
- Logging = history of actions (who is doing what)
Monitoring BigQuery Performance/Resources
- Monitoring = metrics, performance, resource capacity/usage (slots)
- Query count, query times, slot utilization
- Number of tables, stored and uploaded bytes over time
- Alerts on metrics e.g. long query times
- No data on who is doing what, or query details
Stackdriver Logging
- Record of jobs and queries associated with accounts