What is Cloud Dataproc?
- On-demand, managed cluster service for Hadoop and Apache Spark
- Managed but not NoOps
- Must configure cluster, not auto-scaling
- Greatly recudes administrative overhead
- Integrates with other Google Cloud services:
- Separate data from the cluster - save costs
- Familiar Hadoop/Spark ecosystem environment
- Easy to move existing projects -> Lift and shift to GCP
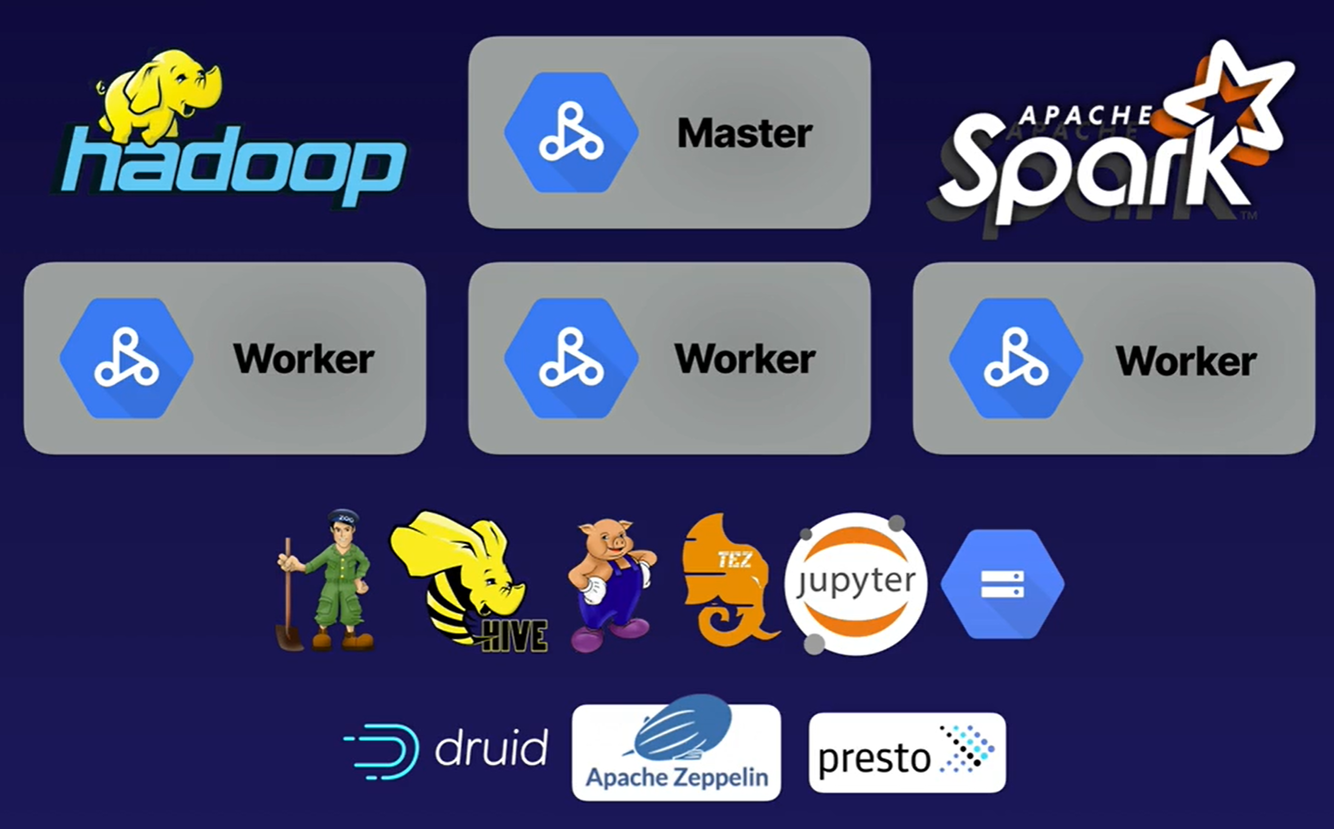
- Base on Apache Bigtop distribution:
- Hadoop, Spark, Hive, Pig
- HDFS available (but maybe not optimal)
- Other ecosystem tools can be installed as well via initialization actions
Lift and Shift is simply migrating existing processes or infrastructure to the cloud without redesigning anything. Some companies might take this approach because they don’t want to spend time and money modifying their current infrastructure but still want to use the benefits of the cloud.
Lift & Shift vs. Lift & Leverage
Lift and Shift is simply migrating existing processes or infrastructure to the cloud without redesigning anything. Some companies might take this approach because they don’t want to spend time and money modifying their current infrastructure but still want to use the benefits of the cloud. For example, hosting a MySQL database on compute engines rather than migrating all the data to Cloud SQL.
Lift and Leverage means to move your existing processes over to the cloud and make them better using some of the services the cloud has to offer. For example, you can use Dataproc to run your Hadoop and Spark workloads but store the data in Cloud Storage as opposed to storing it in HDFS. This is more cost-efficient since you only pay for the time the job is running and then you can shut down the cluster when you aren’t using it without losing all its data since it is now stored in Cloud Storage.
Using Dataproc
- Submit Hadoop/Spark Jobs
- Dataproc is interoperable and compatible with these open source tools
- Enable Autoscaling
- If necessary to cope with the load of the job
- Output to GCP services
- E.g. Google Cloud Storage, BigQuery and Bigtable
- Monitor with Stackdriver
Cluster Types
- Single Node Cluster
- Master, Worker, HDFS on same node
- Standard Cluster
- 1 Master Nodes, several worker nodes
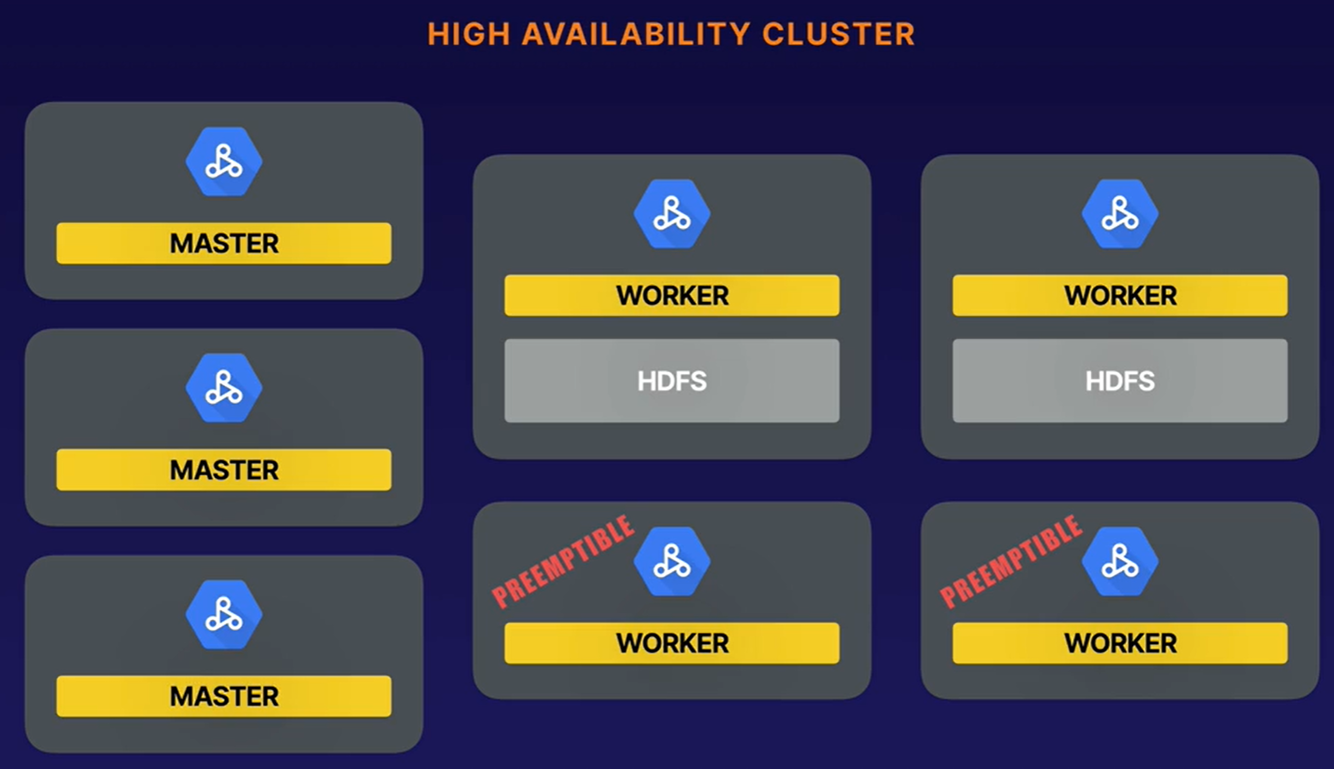
- High Availability Cluster
- Several Master Nodes
Preemptible VM
- Excellent low-cost worker nodes
- Can be reclaimed and removed from the cluster if they are required by Google Cloud for other tasks.
- Dataproc manages the entire leave/join process:
- No need to configure startup/shutdown scripts
- Just add PVMs and thats it
- No assigned disks for HDFS (only disk for caching)
- Ideally you want a mix of standard + PVM worker nodes
- Number of preemptible workers in your cluster should be less than 50% of the total number of all workers
Submitting Jobs
- gcloud Command line
- GCP Console
- Dataproc API
- SSH to Master Node
IAM
- Project level only (primitive and predefined roles)
- Cloud Dataproc Admin, Editor, Viewer, Worker
- Admin:
- Editor: Full access to create/delete/edit clusters/jobs/workflow
- Viewer: View access only
- Worker: Assigned to service accounts only:
- Read/write GCS, write to Cloud logging
https://cloud.google.com/dataproc/docs/concepts/iam/iam#roles
Updating Clusters
- Can only change # workers/preemptibles VMs/labels/toggle graceful decomission
- Automatically reshards data for you
- gcloud dataproc clusters update [cluster_name] –num-workers [#] –num-preemptible-workers [#]
Custom Clusters
- Dataproc clusters can be provisioned with a custom image that includes a user’s pre-installed packages.
- You can also customise your cluster that is using the default image using
- Custom Cluster properties: allow you to modify properties in common configuration files like core-site.xml. Remove the need to manually change property files by hand or initialization action.
- Initialization actions: optional executable scripts that will run during your cluster setup. Allow you to install additional components, stage files, or change the node
- Custom Java/Scala dependencies (typically for Spark jobs)
Autoscaling
Do not use autoscaling with:
- High Availability Clusters
- HDFS
- Spark Structured Streaming
- Idle Clusters
Cloud Storage Connector
- Use GCS instead of HDFS
- Cheaper than persistent disk
- High availability and durability
- Decouple storage from cluster lifecycle
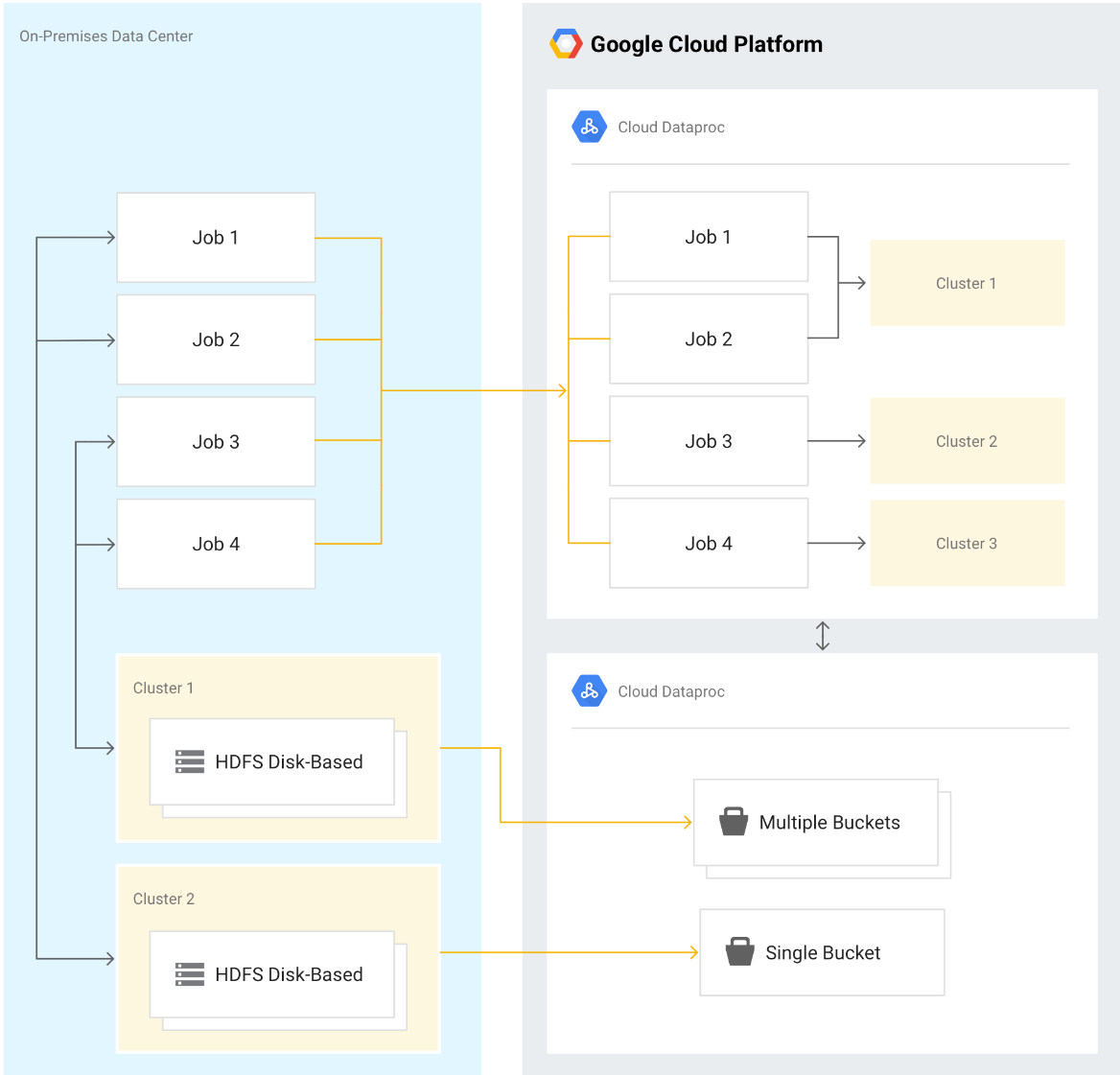
Migrating and Optimizing for Google Cloud
What are we moving/optimizing?
- Data (from HDFS)
- Jobs (pointing to Google Cloud locations)
- Treating clusters as ephemeral (temporary) rather than permanent entities
Migration best practices:
- Move data first, generally to Cloud Storage buckets
- Possible exception:
- Apache HBase data to Bigtable
- Apache Impala to BigQuery
- Can still choose to move to GCS if Bigtable/BigQuery features not needed
- Possible exception:
- Small-scale experimentation (proof of concept)
- Use a subset of data to test
- Think of it in terms of ephemeral clusters
- Separate storage and compute
- Optimize for the Cloud: Lift and Leverage
Lift and Leverage means to move your existing processes over to the cloud and make them better using some of the services the cloud has to offer. For example, you can use Dataproc to run your Hadoop and Spark workloads but store the data in Cloud Storage as opposed to storing it in HDFS. This is more cost-efficient since you only pay for the time the job is running and then you can shut down the cluster when you aren’t using it without losing all its data since it is now stored in Cloud Storage.
Performance Optimization
- Keep data close to your cluster
- Place Dataproc cluster in the same region as storage bucket
- Larget persistent disk = better performance
- Consider SSD over HDD - slightly higher cost
- Move/keep data on HDFS if workloads involve heavy I/O
- Allocate more VMs
- Use preemptible VMs to save on costs
- More VMs will come at a higher cost than larger disks if more disk throughput is needed
-
0_GCP Fundamentals15
-
1_Data Processing fundamentals6
-
2_Storage and Databases17
-
3_Pub/Sub11
-
4_Dataflow20
-
5_Dataproc13
-
6_Bigtable17
-
7_BigQuery30
-
8_Cloud Datalab3
-
9_Cloud Datastudio4
-
10_Cloud Composer4
-
11_Machine Learning19
-
12_Vertex AI16
-
13_Pretrained ML API's3
-
14_Operationalizing Machine Learning4
-
15_Dataprep3
