XML Concepts Flashcards
(46 cards)
What does XML stand for?
XML stands for Extensible Markup Language.
XML is known as self-describing data because you get the data plus metadata.
XML capabilities allow it to serve much like a self-describing relational database stored as a file. All data-aware applications can interact with XML.
What are the two components of XML?
XML is comprised of two components.
- Data
- Metadata - The description of the data, including relationships and properties of the data.
What are XML tags?
XML utilizes tags < > to create the data ‘outline’. The tags can also be nested.
The tag has two sections.
- Beginning tags
The example of Beginning tag would be , It sits between brackets and contains no slash.
Beginning tag would be < Name >
- Ending tags
The example of ending tag would be . It appears identical to beginning tag, except it contains a forward slash. Ending tags must follow the same sequence as the beginning tags.
Ending tag would be < / Name >
Please note: If a tag contains no element data, or element children, then the beginning and ending tag may be combined into one tag. for example < Name / >
is all that is required if there is no element in the Name tag.
What are XML elements?
Elements are actually the tags themselves. Element data is the data which sits between tags. For example, Seahawks is element data. It is data belonging to the element , Team.
< Team > Seahawks < / Team >
What are Root Elements and Top Level Elements in XML?
The top Tag in the XML is the Root Element or the Root Node. All data in the XML appears beneath the Root Element.
The elements falling just under the Root Element are the Top Level Element.

What are XML Attibutes?
XML element tags may contain information within the tags providing descriptive information about the element or its properties. These are known as Attributes.
Attribute data appears with the opening tag name and is enclosed in quotation marks.
For example
< Team Name=”Seahawks” >< / Team >

What is XML?
- Metadata is data about your data. Metadata is information which helps to describe the properties and relationships of data.
- XML is self-describing data, as it contains both data and metadata.
- XML holds its data adn metadata in a hierarchical set of tags.
- A beginning and ending tag always have the same name. You can tell them apart because the ending tag starts with a forward slash / .
- The ending tag for < Jerrin > would be < / Jerrin >
- The data in XML can be in the form of attributes or elements.
- Element data is stored between the beginning and ending element tag.
- Attribute data is stored inside of the beginning tag.
- XML is case sensitive.
- XML tag names cannot have spaces between them.
- Each element or attribute has exactly one parent (Except for the root element).
- Any node which is two or more levels above is called as Ancestor.
- Any node that is two or more levels below is called Descendant.
- An attribute is data that is inside an element.
What are streams and what are the different ways you can stream XML data from SQL Server?
In SQL Server terms , a Stream resembles a table. The grid like presentation of rows and columns that you get when you run a query. This is because SQL Server prefers to present data in a grid shape. However, XML does not set things up in rows and columns.
XML Streams
XML actually has many modes of streaming output. you can instruct SQL Server to stream your XML result in the mode you prefer.
Following are the various modes of streaming output in XML
- XML Raw Mode
- Output with ROOT Element option
- output with Elements option.
- XSINIL
What is XML Raw Mode?
To our base query, we need to add the keywords “FOR XML” in order for our results to apprear as XML. We also need to specify the mode, which in this case is RAW
The example query would be
SELECT LocationID, City
FROM Location
FOR XML RAW
Raw is the easiest type of XML to run. The output in the screenshot attached is the result in XML raw dataformat. Notice the result is a hyperlink, which you click to view your results. The second screenshot shows the XML after clicking the hyperlink.
Notice that the default tag label is “row” for each row of our result set. The data appear as attributes.
XML will allow you to override the default name < row > and set it to something mode descriptive.
Raw is the simplest mode where all data is considered to be at the same level with no nesting. The XML RAW command by default does not create a root.

How do you give a descriptive custom tag for the output in XML RAW mode?
XML will allow you to override the default name < row > and set it to soemthing more descriptive. The syntax shown here will change the name for each attribute tag to “RowLocation”
SELECT LocationID, City
From Location
FOR XML RAW(“rowLocation”)
You can see the output in the screenshot attached. Observ the red Intellisense underline and mouseover tag appearing in the result. XML document cannot contain multiple root level elements. Also notice we have four top-level nodes and no root node. SQL Server would prefer that we have a root element appreaing in our data.

How do you generate XML output with the Root Element Option?
XML is considered complete(known as well-formed XML) only if it has a root tag which emcompasses all other tags. Adding the keywork ROOT to our code specifies the ROOT element option.
Adding the ROOT command to our code will add root tag in our XML data.
Select LocationID, City
From Location
FOR XML RAW(‘Location’), ROOT
in the screenshot you can see that instead of just XML fragment, our code produces an entire XML stream. This output is a well-formed XML document.
By default the ROOT command would add a root element with the tag “root”. If you want to add a custom name for the Root element then you can do the following.
Select LocationID, City
From Location
FOR XML RAW(‘Location’), ROOT(‘Jerrin’)
In the output you can see that the Root element is now named “Jerrin”. Notice that the data appears as attributes inside the tag.
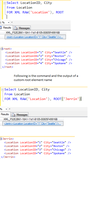
How do you generate an XML output with a custom name for the Root element?
By default the ROOT command would add a root element with the tag “root”. If you want to add a custom name for the Root element then you can do the following.
Select LocationID, City
From Location
FOR XML RAW(‘Location’), ROOT(‘Jerrin’)
In the output you can see that the Root element is now named “Jerrin”. Notice that the data appears as attributes inside the tag.
How do you generate XML output using the ELEMENTS option?
The raw mode likes to store all data as attributes. You can choose whether data appears as attributes or as elements. If you prefer elements, then you can append the ELEMENTS option to the XML RAW mode.
Select LocationID, City
From Location
FOR XML RAW(‘Location’), ROOT(‘Jerrin’),ELEMENTS
Looking closely at the XML output in the screenshot you’ll recognize the values for records 1,2,3 and 4 from the location table.
PLEASE NOTE: With the ELEMENTS option if the row has any NULL value then it is not shown as an Element in the XML output. This is a default behaviour. To include the NULL values in the XML output for the elements we would have to use the XSINIL option.

What is the XSINIL option?
The XSINIL option allows you to force a tag(s) to be present, even if the underlying data is null.
For fields in SQL Server which include a null value for some records but are populated with regular values in the other records, you will seem to have missing tags for the NULL record. Often this is alright, as missing tags are presumed to be null. However, if you require all tags to be present(even if they have no data), then you can specify the XSINIL option for your XML stream.
The output of the following query is shown in the screenshot.
select FirstName,LastName,LocationID
FROM Employee
FOR XML RAW(‘Employee’),ROOT(‘Emp’),ELEMENTS XSINIL
In the output we see that the third sub-element for John Marshbank. The location tag is no longer missing. It is present and show the value of xsi:nil=”true” in place of a LocationID

Your Root tag is named < ThisIsATag > in your well formed XML. How should the ending root tag be named?
< / ThisIsATag >
What do you call data inside of a tag like the example seen below?
< Team Name=’Empyreans” >
Attribute
Raw is the only XML Mode?
True or False
False
Raw automatically adds the root element tag in SQL Server.
True or False
False
If you dont specify any option, then XML RAW will have your data streamed in as:
- Element Text OR
- Attributes
Attributes
Without XSINIL, what happens to null values from your result set?
No tags are present for null values.
XML is case sensitive?
Yes Or NO
Yes
What are the various modes for creating XML streams?
XML Stream modes
- XML RAW
- XML AUTO
- XML PATH
Give some details about XML AUTO mode?
When selecting from a single table, the Auto Mode resembles the Raw mode with one exception. Whereas the Raw mode defaults each tag to < row >, the Auto Mode names each tag to the table name (or table alias) listed in the FROM clause of the query.
The code for Auto Mode is similar to the code for RAW.
Select *
FROM Location
FOR XML AUTO
The resulting XML is also quite similar to RAW mode. The data appear as attributes, and by default there is no root element. However, note that the Auto Mode has defaulted the row tags to the table name as it appears in the FROM clause. The tag < Location > is named for the Location table.
If we specify “Location” in our XML Raw mode, then the stream resulting from our Raw query would be identical to our Auto query.

How does XML AUTO mode works with multiple table queries?
Also
If AUTO mode were to be used and it names the tag after the table what do queries with 2 table (or more) names get?
Also
What is the difference between the XML RAW and XML AUTO modes?
We will look at the following query for this example.
SELECT City,FirstNAme,LastName
FROM Location inner join Employee
on Location.LocationID=Employee.LocationID
FOR XML AUTO
The answer is both table names would be there in the XML output. The Auto mode generates a tag for each table: the Location data attributes (City) is contained in the < Location > tag, and the Employee data attributes (FirstName, LastName) are contained in the < Employee > tag.
So this demonstrates a difference between the Auto mode and the Raw mode. The Auto mode will nest the results, but the RAW mode will not.
Look back to the query and note that the Auto Mode placed tags in the order in which the tables appreared in our query. In this example, the Location table becomes the top-level element tag because the first field in the SELECT list is City whcih is from the Location Table. The second (nested ) table is Employee which appreas beneath as a child element.
If you were to list any field from the Employee table first, rather than a field from the Location table, then the < Employee > element would have the < Location > element nested inside of it.
For example if you write the following query you would get the result as shown in the screenshot for query 2 output.
SELECT FirstName, City, LastName
FROM Location INNER JOIN Employee
on Location.LocationID=Employee.LocationID
FOR XML AUTO