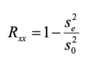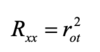The reliability coefficient varies between
0 and 1
Reliability refers to
the consistency of a measuring tool
Is reliability all-or-nothing or on a continuum?
Continuum. That is, a measuring tool or test will be more or less reliable
Two components that CTT assumes are present in an observed score
true score + measurement error
True score
the actual amount of the psychological characteristic being measured by a test that a respondent possesses.
Measurement error
the component of the observed score that does not have to do with the psychological characteristic being measured
According to CTT, reliability is the extent to which differences in respondents’ ______ scores are attributable to differences in their_________ scores, as opposed to __________ ___________
observed, true, measurement error
3 sources of measurement error
- Test construction 2. Test administration 3. Test scoring and interpretation
Examples of sources of measurement error in Test construction
• item sampling (variation among items in a test) • content sampling (variation among items between tests)
Example of sources of measurement error in test administration
• test environment (temperature, lighting, noise) • events of the day (positive vs. negative events) • test-taker variables (physical discomfort, lack of sleep) • examiner-related variables (physical appearance & demeanour)
Example of sources of measurement error in Test scoring and interpretation
• subjectivity in scoring (grey area responses) • recording errors (technical glitches)
Reliability depends on two things:
- The extent to which differences in test scores can be attributed to real individual differences 2. The extent to which differences in test scores are due to error expressed as: Xo = Xt + Xe
2 key assumptions of CTT
- Observed scores on a psychological measure are determined by a respondent’s true scores plus measurement error 2. Measurement error is random—it is just as likely to inflate a score as to deflate it -error tends to cancel itself out across respondents -error scores are uncorrelated with true scores
A reliability coefficient acceptable for research purposes
.7 or .8
A reliability coefficient needed for applied purposes
.9
Tau Equivalence
participants true scores for one test must be exactly equal to their true scores on the other test
Parallel tests must satisfy the assumptions of CTT as well as further assumptions which are
- participants true scores for one test must be exactly equal to their true scores on the other test—known as “tau equivalence” 2. the tests must have the same level of error variance
standard deviation of error scores tell us in “test score units” the…
the average size of error scores we can expect to find when a test is administered to a group of people
The standard deviation of error is also known as
the standard error of measurement
the correlation between parallel test scores is equal to
the reliability
Thus, parallel forms of a test exist when, for each form, the observed scored means and variances are
the same
Different content problem
Two forms of a test may meet the requirements of CTT, but not measure the same psychological attribute because they posses different content
carryover effects examples
For example, a respondent’s memory for test content, attitudes, or mood state might similarly affect performance on both forms of a test
According to CTT error scores on one form of a test should be ______________ with error scores on a second form of a test
uncorrelated