Spark Architecture Flashcards
(22 cards)
Cluster Definition & Components (5)
Group of computers used to process big data. Multiple spark applications can be running on a cluster at the same time.
- Driver
- Worker
- Executor
- Task
- Core

Driver
(definition & 3 responsibilities)
(relationship to cluster)
Machine in which application runs. It sits on a node within a cluster.
(1) Maintains information about application
(2) responds to users programs
(3) analyzes, distributes, and schedules work across executors.
In single cluster, there will be only one driver.
Executor
(definition & 2 responsibilities)
Holds a partition of data, a collection of rows sitting on a single physical machine.
Responsible for carrying work assigned by driver:
(1) executing code assigned by driver
(2) reports status of a computation back to the driver.
First level of parallelization.
Task
(def. & what creates a task)
(where is it assigned)
Created by drivers to process a partition of data. Task are assigned to a slot/core.
Lazy Evaluation
(definition & optimization)
Task is not executed immediately, executed once an action is called. Allows for optimization of pipelines, executing multiple computations a once.
Narrow Transformations
(def & 3 examples)
One input partition contributes to one output partition.
examples:
.select()
.cast()
.union()
Wide Transformations
(def & 3 ex.)
One input parition contributes to multiple output partitions. Wide transformation triggers a shuffle.
examples:
.distinct()
.groupBy()
.join()
Shuffle
Data distributed over multiple executors.
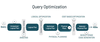
Catalyst Optimizer / Query Optimization
(what is does & 7 components)
the core for sparks power and speed, automatically finds the most efficient plan for applying transformation and actions
- user input: query, dataframe
- unresolved logical plan: plan for transformation waiting to be validated against the catalog
- analysis: column names validated against catalog (table metadata), unresolved plan becomes the logical plan
- logical optimization: first stage of optimization, determining the most efficient sequence of commands
- physical plan: each represents the query engines actions after all optimizations have been applied
- cost model: each physical plan is evaluated according to its cost model, the model with the best performance is selected to create the selected physical plan
- code generation: selected physical plan in complied to Java bytecode and executed.
Caching
Place DataFrame into temporary storage across executors in your cluster to make subsequent reads faster
Spark API
(4 Components)
- Spark SQL + DataFrames: structured data processing
- Streaming: streaming data
- MLib: scalable machine learning library
- Core API: execution engine, all other functionality built on. Supports, Java, Scala, Python, R, SQL.
Worker
(Definition)
Host the executor process. Has a fixed number of executors allocated at any point in time.
Core/Slot
Splits the work within an executor, a task is assigned to it. Second level of parallelization.
Transformations
(definition & examples)
(what are the two types of transformations?)
How Spark expresses business logic. Instructions for modifying a DataFrame.
Transformation Examples:
.select()
.distinct()
.groupBy()
.sum()
.filter()
.limit()
Two types: Narrow and Wide
Actions
(definition & 3 types of actions and examples)
Statements computed and executed when encountered in the developer’s code. Methods that trigger computation.
Action Types:
- view data in console - .show(), .count()
- write to output data sources - saveAsTextFile()
- collect data to native objects - .collect()
UnsafeRow (definition)
Tungsten Binary Format, in-memory storage format for Spark SQL and DataFrames. The format of shuffled data.
Adaptice Query Execution (AQE)
(definition and 3 dynamic features)
re-optimizes and adjust query plans based on runtime stats.
- dynamically coalescing shuffle partitions
- dynamically switching join strategies
- dynamically optimizing skew joins
Partition Guidelines (3)
(best practices for when & how to use)
- err on the side of too many small partitions rather than large partitions
- don’t allow partition size to increase to > 200 MB per 8GB of core total memory
- calculate shuffle partition size by dividing largest shuffle stage input by the target partition size
4TB total data / 200 MB = 20K shuffle partition count
Streaming Use Cases (6)
- notifications
- real-time reporting
- incremental ETL
- update servers in real time
- real-time decision making
- online ML
advantages of stream processing (2)
- lower latency: lag time in response
- more efficient updating
micro batch processing
continuous processing
(definition and how it works)
micro batch processing: waits to accumulate smallbatches of input data, then process each batch in parallel. Higher throughput, but higher latency.
continuous streaming: each node continually listens to messages from other nodes and outputs new updates to child nodes. Provides lowest possible latency, but lower maximum throughput.
Generally streaming applications that are large scaled tend to prioritize throughput, so traditionally Spark focused on micor-batch processing. However, Structured Streaming supports bth.
Predicate Pushdown
(component of query optimization)
Filter statements are known as predicates. A query performance can be imrpoved by reducing the amount of data using a filter.
If you “push down” parts of the query to were the data is stored, greatly reduce network traffic (cost implications in cloud) and increase data reading reading speed.
