Replication Flashcards
What are the three main Leader based approaches for replicating changes between nodes?
Single-Leader, Multi-Leader, and Leaderless replication.
What is a reason to replicate data?
To keep data geographically close to your users.
What is a reason to replicate data?
To allow the system to continue working even if some of its parts have failed.
What is a reason to replicate data?
To scale out the number of machines that can serve read queries (and thus increase read throughput).
What are other terms for leader-based replication?
Active-Passive or Master-Slave replication
How is the data exchanged from the user in leader-based replication?
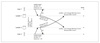
One replica is designated the leader. Clients must send all write requests to the leader. The leader write that data to its local storage and then sends the data change to all of its followers as part of a replication log. Each follower takes the log from the leader and updates its local copy of the databse accordinly by applying all writes in the same order as the leader.

What is the advantage of synchronous replication?
All followers are guaranteed to have and up-to-date copy of the data that is consistent with teh leader. If the leader suddenly fails we can be sure the data is still available to the on the follower.
What is the disadvantage of synchronous replication?
If any synchronous follower doesn’t respond for any reason, the write cannot be processed and hte leader must block all writes and wait until the synchronous replica is available again.
Is leader-based replication usually configured to be synchronous or asynchronous?
Asynchronous
Why aren’t writes durable in asynchronous replication?
If the leader fails and is not recoverable, any writes that have not yet been replicated to followers are lost. This means that a write is not guaranteed to be durable to a client even after it has been confirmed. (However a fully asynchronous configuration can allow for the leader to continue processing writes even if all of its followers have fallen behind.
How to set up new followers?
- Take a snapshot of leasder’s database at some pont in time (without taking a lock on entire DB if possible).
- Copy teh snapshot to the new follower node.
- The follower connects to the leader and requests all data changes that have occurred since snapshot was taken.
- When the follower has processed the backlog of data changes it can then continue to process changes from the leader as they happen.
Follower Failure: Catch-up Recovery
Each follower keeps a log of data change it has received from the leader. If network is interrupted or a follower crashes it can request all data changes since the last transaction before it disconnected and it can get caught up. Once caught up it can continue receiving a stream of data changes as before.
What is Failover?
The process that occurs confugring (sending all write requests and having other followers start consuming changes from new leader) a new leader to when the current leader fails.
What are the three steps that occur during the Automatic Failover process?
- Determining that the leader has failed.
- Choosing a new leader.
- Reconfiguring the system to use the new leader.
How to determine when a leader has failed? (Failover Step 1)
There is no foolproof way of detecting what has gone wrong so most systems use a timeout. Nodes frequently send messages between one another and if a node doesn’t respond for a period of time it is assumed to be dead. (Gossip Protocol)
How to choose a new leader? (Failover step 2)
This could be done through an election process (Consensus) or a new leader can be appointed by a previously elected controller node. The best candidate for leadership is usually the replica with the most up-to-date changes from the old leader.
What needs to happen to reconfigure a system to use a new leader? (Failover step 3)
Clients need to send all write requests to the new leader (Request Routing), have all followers now follow the new leader, and take precautions if the old leader comes back and still thinks it is the current leader.
What are some issues that an occur in failover?
- new leader may have not received all the writes form old leader before it failed (only in asynchronous replication).
- Two nodes both believe they are the same leader (Split Brain).
- Having a timeout that is too short (unnecessary failovers) or too long (longer time to recovery).
What are the four implementations of Replication Logs?
- Statement-based replication
- Write-ahead log (WAL) shipping
- Logical (row-based) log replication
- Trigger-based replication
How does statement-based replication work?
The leader logs every write request that it executes and sends it to its followers. Ex: For a relation database every INSERT, UPDATE, or DELETE statement gets sent.
Issues with statment based replication
- Any statement that calls nondeterministic funtion such as NOW() or RAND() could generate a different value.
- If statments use autoincrementing columns or depend on existing data in the DB they must be executed conurrently which could be hard with multiple concurrently executing transactions.
- Since there are so many edge cases other repliation methods are generally preferred
How does Write-ahead log shipping work?
The log is an append-only sequence of bytes containing all writes to the DB. We can use the exact same log to build a replica on another node. When follower processes this log it build a copy of the exact same data strucutre as found on the leader (B-Tree, SSTables and LSM-Trees).
How does Logical (row-based) log replication work?
A sequence of records describing writes to database tables at the granularity of a row (which allows the log to be decoupled from the storage engine internals). A transaction that modified several rows generates several such log records followed by a record indicating the transaction was committed. This process allows for different versions or entire storage engines and is easier for backward compatibility.
How doe Trigger-based replication work?
Occurs in the appication layer instead of being implemented by the DB system. A trigger lets you register custom application code that is automatically executed when a data change occurs in a DB system. A change is logged in a separate table that an external process can read and apply any necessary changes to another system.