Python - Pandas Library Flashcards
Syntax
Creating DataFrames
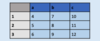
Create a DataFrame using dict format, specifying values for columns
df = pd.DataFrame( { “a” : [4 ,5, 6],
“b” : [7, 8, 9],
“c” : [10, 11, 12] },
index = [1, 2, 3] )
Syntax
Creating DataFrames
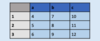
Create a DataFrame using list format, specifying values for each row
df = pd.DataFrame( [[4, 7, 10], [5, 8, 11], [6, 9, 12] ],
index=[1, 2, 3],
columns=[‘a’, ‘b’, ‘c’] )
Method Chaining
Most Pandas methods returns a DF so another method can be applied to the result.
Melt a DF, rename the columns, and then query it.
df = ( pd.melt(df)
.rename( columns={ ‘variable’ : ‘var’, ‘value’ : ‘val’} )
.query(‘val >= 200’)
)
Reshaping Data
Gather the columns into rows
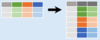
pd.melt (df)
Reshaping Data
Spread rows into columns

df.pivot ( columns=’var’,
values=’val’
)
Reshaping Data
Append rows of df2 to df1

pd.concat ( [df1, df2] )
Reshaping Data
Append columns of df2 to df1

pd.concat ( [df1, df2],
axis=1
)
Data Structures
What’s a Series and how do you define it?

A Series is basically an indexed list.
s = pd.Series ( [3, -5, 7, 4],
index=[‘a’, ‘b’, ‘c’, ‘d’]
)
Data Structures
What’s a DataFrame and how do you define it?

A DataFrame is basically a bunch of Series (or columns) that are concatenated together and indexed.
data = { ‘Country’: [‘Belgium’, ‘India’, ‘Brazil’],
‘Capital’: [‘Brussels’, ‘New Delhi’, ‘Brasília’],
‘Population’: [11190846, 1303171035, 207847528]
}
df = pd.DataFrame ( data,
columns=[‘Country’, ‘Capital’, ‘Population’]
)
Selection
How do you get one column of values?
You access it like a dictionary (by referencing the key or in this case the column name)
col_of_values = df [‘col_name’]
Selection
How do you get a subset of the DataFrame, or get multiple columns?
Access it just like list indexing / slicing.
df [start_col# : stop_col#]
Selecting
Select value(s) in a row with a named index.
df.loc [name_of index or row]
Selecting
Select value(s) in a row with a named index with a certain condition, and only those specific columns.
df.loc [df [ ‘a’] > 10,
[‘a’, ‘c’] ]
Selecting
Select value(s) in a column with a numbered / default index.
df.iloc [num_of_indexed_row]
Subset Observations / Rows
Extract rows that meet a logical condition
df [df.Length > 7]
Subset Observations / Rows
Remove duplicate rows
df.drop_duplicates()
Subset Observation / Rows
Select first n rows
df.head(n)
Subset Observation / Rows
Select last n rows
df.tail(n)
Subset Observation / Rows
Select rows by default indexed position
df.iloc [10:20]
Subset Variables / Columns
Select multiple columns with specific names.
df [[ ‘width’, ‘length’, ‘species’] ]
*notice you have to input a list into the dataframe’s reference
Subset Variables / Columns
Select single column with specific name.
df [‘width’]
or
df.width
Parameter that can be inserted in most DataFrame methods to modify the original DataFrame in place.
inplace = ‘True’
Sort
Order the rows by values of a column (low to high)
df.sort_values ( ‘mpg’ )
Sort
Order rows by values of a column (from high to low)
df.sort_values ( ‘mpg’, ascending=False )
Rename
Rename the columns of a DataFrame
df.rename( columns = { ‘y’:’year’ } )
Drop
Drop certain columns from a DataFrame
df.drop ( columns=[‘Length’, ‘Height’] )
Handling Missing Data
Drop rows with any column having NA/null data
df.dropna()
Handling Missing Data
Replace all NA/null data with a value.
df.fillna( value )
Handling Missing Data
Replace values with others
df.replace ( ‘a’, ‘f’ )
Duplicate Data
Return unique values
df.unique()
Duplicate Data
Drop duplicates
df.dropt_duplicates()
Summarize Data
Count the number of rows with non-null values of each object
df [‘w’] .counts()
…or if you want to get rid of duplicates too…
df [‘w’] .value_counts()
Summarize Data
Give # rows in a DataFrame
len(DF)
Summarize Data
Give the # of rows and columns of a DataFrame
df.shape()
Summarize Data
Describe the DataFrame columns
df.columns()
Summarize Data
Describe the basic DataFrame information
df.info()
Summarize Data
Describe the basic descriptive statistics for each column (or GroupBy)
df.describe()
Summarize Data
Sum the values of a column
df.sum()
Summarize Data
Give the median and mean of a column.
df. median()
df. mean()
Summarize Data
Give the min, max, var, std of a column(s).
df. min()
df. max()
df. var()
df. std()
Apply Function
Apply a function to each value (all rows) of a column
*Note this is vectorizes, so it’s efficient + fast
function = lambda x: x*2
df.apply( function )
