Python Code Knowledge Flashcards
(147 cards)
What is getopt?
What is it’s syntax?
Is a “command line option parser”.
It parses an argument sequence such as sys.argv and returns a sequence of (option, argument) pairs and a sequence of non-options arguments.
Syntax: (option, argument) = getopt.getopt([‘-a’, ‘-bval’, ‘-c’, ‘val’], ‘ab:c’)
As you see that it outputs a pair, this is why you need to equate to a pair.
What is numpy?
Numpy is the core library for scientific computing.
Numpy provides a high-performance multidimensional array object. Alongside this, it gives tools to work with these arrays.
It allows you to get the same sort of functionality as Matlab.
What is pip?
It is the preferred used installer program for modules in python.
Since python 3.4 pip has been included by default with python.
Almost all packages that you hear of will be available with pip install
“PIP is a package manager for Python packages, or modules if you like.”
“A package contains all the files you need for a module.”
“Modules are Python code libraries you can include in your project.”
How do you create your own modules in python?
Modules are simply python scripts that are imported into another script.
First, write up your function and save it.
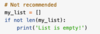
How do you write to a file?
First of all you need to have ‘w’ in your file open line.
Then use .write() to add you text. *Note writing to a file clears the file of anything beforehand, to add to a file you need to use append i.e. ‘a’ in the open line*
Within the brackets of .write() you want to write the text.
What does CSV stand for?
Comma separated variables
The delimiter determines what separated the variables. It doesn’t have to be commas, it can pretty much be anything.
What is pandas?
“Pandas is a python software library for data manipulation and analysis. “
“Pandas is a python package providing fast, flexible, and expressive data structures designed to make working with ‘relational’ and ‘labeled’ data both easy and intuitive.
What is matplotlib?
Is plotting library/package.
What is beautfiulsoup?
Is a python library for pulling data out of HTML and XML files.
How do you permanently set the index for a data frame?
To set the index you use .set_index(“Desired Index”)
To make it permanent you need to add another parameter in the brackets, inplace, and it needs to be set to True.
How would you access a single column from a dataframe?
In the same way you would get the values in a dictionary.
dataframe_name[‘Desired_Column_Name’]
Or
dataframe_name.Desired_Column_Name()
How do you convert a dataframe column into a list?
What do you need to remember?
dataframe_name.column_name.tolist()
Only works on one column at a time.
If you want to print to columns of a dataframe what should you do ?
You can extract the columns by referencing both columns with respect to the dataframe, within double square brackets.
Alternatively, you could convert the dataframe into an array using np.array(dataframe[[‘Column1’, ‘Column2’]]).
When reading in a csv file through .read_csv() how can we define the index column?
within the brackets you place index_col and equate it to 0 (or whatever index you want)
What does .to_csv() do ?
It converts a dataframe in python to a csv file.
Before the full stop you place the dataframe you can to convert into a dataframe.
dataframe_name.to_csv()
How do you block comment in mac ?
cmd + 1
cmd +4 comments the block but also puts two lines of hyphens above and below the block.
How do you get data from Quandl?
using quandl.get()
within .get() you place the ‘TickerID’, authtoken i.e API and optionally a start_date and/or end_date.
What does pandas_datareader do ?
Up to date remote data access for pandas, works for multiple versions of pandas.
How do you read a CSV file and convert it to a dataframe?
What do you need to add to convert a date column to the index?
pd.read_csv(“file_name.csv”)
Plug in the parameters (parse_dates = True, index_col = 0) into the brackets.
If you make any changes to the iphyton console in preferences what else do you need to remember to do?
Reset ipython console kernel.
(Small cog wheel in the top right)
If the index isn’t sorted in the right direction how can you sort it correctly?
.sort_index(axis = 0, inplace=True, ascending = True)
When parsing out paragraphs from a webpage using BeautifulSoup, what do you need to remove the tags so that you’re only left with strings?
What is the most simple way to extract the strings?
You can use .string or .text. The difference between the two is that .string won’t show any string with ‘child’ tags.
In most case you probably want .text
That being said, the most simple way is to take your BeautifulSoup object say soup and apply the module .get_text(), i.e. soup.get_text(). Note that the two forms are not exactly the same.
What is pickling?
Why would you use it?
How would you use it?
Pickling is the serializing and de-serializing of python objects to a byte stream. Unpicking is the opposite.
Pickling is used to store python objects. This means things like lists, dictionaries, class objects, and more.
Pickling will be most useful for data analysis, when you are performing routine tasks on data, such as pre-processing. Also used when working with python specific data types, such as dictionaries.
If you have a large dataset and you’re loading a massive dataset into memory every time you run the program, it makes sense to just pickle the data and load that. It may be 50-100x faster.
How to pickle?
After having imported the pickle you need to open the file that is pickled.
pickle_in = open(“dict_pickle”, ‘rb’) # rb stands for read byte
example_dict = pickle.load(pickle_in)
What module is building block for scraping web pages with BeauftifulSoup?
After obtaining the desired content by applying .find() on soup(webpage contained by bs4), it is still covered and surrounded by HTML code. To remove it you need to use .find_all(), within the brackets you need to state what tag you want to remove.