pandas Flashcards
(10 cards)
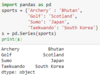
Given the following dictionary, figure out the following?
sports = { ‘Archery’ : ‘Bhutan’,
‘Golf’ : ‘Scotland’,
‘Sumo’ ; ‘Japan’,
‘Taekwondo’ : ‘South Korea’ }
- How do you get the Series?
- How do you get the 4th value?
- How do you get the value of ‘Golf’?
import pandas as pd
s = pd.Series(sports)
print(s)
- Output attached
- s.iloc[3] or s[3]
- s.loc[‘Golf’] or s[‘Golf’]
- The following purchases took place:
- Purchase 1: Chris purchased dog food for 22.50
- Purchase 2: Kevyn purchased kittly litter for 2.50
- Purchase 3: Vinod purchased bird seed for 5.00
- Place these purchases in a Series.
- Place these Series within a DataFrame with indexes
- Give Purchase 1 and 2 to Index “Store 1”
- Give Purchase 3 to Index “Store 2”
- See attached

Given the dataframe ‘df’ composed of three purchases, how would you:
- Get the values stored within the index ‘Store 2’?
- Get the list of all items that have been purchased, regardless of where they were purchased?
- Get the COST of items purchased at ‘Store 1’?
- Return the NAME and COST for all items from all stores?
- Show the dataframe without the ‘Store 1’ indexed data?
- Delete the ‘Name’ values from the dataframe?
- Insert a new column into the dataframe named ‘Location’?
- Update the dataframe by applying a discount of 20% across all values in the ‘Cost’ column?
- df.loc[‘Store 2’]
- df[‘Item Purchased’]
- df.loc[‘Store 2’, ‘Cost’]
- df.loc[: , [‘Name’, ‘Cost’] ]
- df.drop(‘Store 1’)
- NOTE: This creates a copy with the Store 1 index removed, and does not actually remove Store 1 index values from the original dataframe
- del df[‘Name’]
- NOTE: This permanently deletes this data from the dataframe
- df[‘Location’] = None
- df[‘Cost’] *= .80; print(df)
What practice is the following an example of?
df.loc[‘Store’][‘Cost’]
- Why should you not do it?
- What would be a different way to do this?
- This is referred to as chaining
- this should not be done because it creates a copy of the dataframe instead of a view and can cause unpredicable results
- df.loc[‘Store’, ‘Cost’]
How do you create a new series named ‘costs’ that is based on the original series ‘Cost’ data?
- Using broadcasting, how do you increase the cost of each item by 2?
- What will happen to the ‘Cost’ values in the original dataframe?
- What should you do if this is not your intention?
- costs = df[‘Cost’]
- costs += 2
- The costs in the original dataframe will also increase by 2
- If this is not the desired outcome (e.g. if you do not want to change the original dataframe values) then use the copy method
Given a csv file named ‘olympics.csv’, how would you:
- Read the file into Pandas
- Make the first column the index column
- Skp the first row
- Print the first 5 rows
- Rename the column headers as follows:
- If the column is named ‘01’, rename to ‘Gold’
- If the column is named ‘02’, rename to ‘Silver’
- If the column is named ‘03’, rename to ‘Bronze’
- df = pd.read_csv(‘olympics.csv’, index_col=0, skiprows=1)
- df.head()
- for col in df.columns:
if col[:2] == ‘01’:
df.rename(columns={col:’Gold’]}, inplace = True)
if col[:2] == ‘02’:
df.rename(columns={col:’Silver’]}, inplace = True)
if col[:2] == ‘03’:
df.rename(columns={col:’Bronze’]}, inplace = True)
- Using boolean masking, how would you return values from a dataframe where values in the ‘Gold’ column are greater than 0?
- Using boolean masking, create a new series composed of data from the original dataframe where the values in the ‘Gold’ column are greater than 0?
- Return how many records are in this new dataframe?
- df[‘Gold’] > 0
- only_gold = df.where(df[‘Gold’] > 0)
- df[‘Gold’].count()
Given the dataframe of purchases, return the NAMES of customers whose purchases COST more than $3.00
- df[‘Name’][df[‘Cost’]>3]
What Pandas function takes a lsit of columns and promotes those columns to an index?
- When this function is used, what happens to the original index (by default)?
- Example from olympic.csv data:
- Create a new index of ‘Gold’
- Make sure to preserve the original index ‘Country’
- Reset the index to remove the unnecessary header
- set_index
- This is a destructive process, meaning it does not keep the original index
- Example:
- df[‘country’] = df.index
- df = df.set_index(‘Gold’)
- df = df.reset_index()
Given the following DataFrame, carry out the following tasks:
- df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=[‘Store 1’, ‘Store 1’, ‘Store 2’]
- Reindex the purchase records DataFrame to be indexed hierarchically, first by store, then by person.
- Name these indexes ‘Location’ and ‘Name’.
- Then add a new entry to it with the value of:
- Name: ‘Kevyn’
- Item Purchased: ‘Kitty Food’
- Cost: 3.00
- Location: ‘Store 2’
- Set the new index of ‘Name’ (the store index already exists)
- df = df.set_index([df.index, ‘Name’])
- Name the indexes
- df.index.names = [‘Location’, ‘Name’]
- df = df.append(pd.Series(data={‘Cost’: 3.00, ‘Item Purchased’: ‘Kitty Food’}, name=(‘Store 2’, ‘Kevyn’)))
