Neural Networks Flashcards
(133 cards)
sigmoid
What does the activation function look like?
What’s the equation?
Output from 0-1

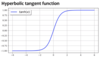
hyperbolic tangent
What does the activation function look like?
What’s the equation?
Output from 0-1
What’s the logistic function?
Same as sigmoid
What are some characteristics of tanh?
- Helps to avoid vanishing gradients problem
Comparse sigmoid and tanh
Tanh converges faster
What’s a problem with ReLU? How is it addressed?
Derivative at x<0 is 0
One solution: Instead use an ELU (exponential linear unit)
Describe Relu (2) and ELU (2)
In general, ELU outperforms ReLU?

What’s one thing you could do to convert a NN classifier to a regressor?
“chop off” sigmoid activation function and juset keep output linear layer which ranges from -infinity to +infinity
What’s an objective function you could use for regression?
Quadratic Loss:
the same objective as Linear Regression –
i.e. mean squared erroradd an additional “softmax” layer at the end of our network
What an objective function you could use for classification?
Cross-Entropy:
- -the same objective as Logistic Regression
- – i.e. negative log likelihood
- – This requires probabilities, so we add an additional “softmax” layer at the end of our network
- “any time you’re using classification, this is a good choice” - Matt
What does a softmax do? (1)
Takes scores and transforms them into a probability distribution
For which functions does there exist a one-hidden layer neural network that achieves zero error?
Any function
What is the Universal Approximation Theorem? (2)
- a neural network with 1 hidden layer can approximate any continuous function for inputs within a specific range. (might require a ridiculous amount of hidden units, though)
- If the function jumps around or has large gaps, we won’t be able to approximate it.
What do we know about the objective function for a NN? (1)
It’s nonconvex, so you might end up converging on a local min/max
Which way are you stepping in SGD?
Opposite the gradient (verify this)
What’s the relationship between Backpropagation and reverse mode automatic differentiation?
Backpropagation is a special case of a more
general algorithm called reverse mode automatic differentiation
What’s a benefit of reverse mode automatic differentiation?
Can compute the gradient of any differentiable function efficiently
- When can we compute the gradients for an arbitrary neural network?
(question from lecture)
When can we make the gradient computation for an arbitrary NN efficient?
(lecture question)
What are the ways of computing gradients? (4)
- Finite Difference Method
- Symbolic Differentiation
- Automatic Differentiation - Reverse Mode
- Automatic Differentiation - Forward Mode
Describe automatic differentiation - reverse mode (a pro, con, and requirement)
- Note: Called Backpropagation when applied to Neural Nets –
- Pro: Computes partial derivatives of one output f(x)iwith respect to all inputs xj in time proportional to computation of f(x) –
- Con: Slow for high dimensional outputs (e.g. vector-valued functions) –
- Required: Algorithm for computing f(x)
Describe automatic differentiation - forward mode (a pro, con, and requirement)
- Note: Easy to implement. Uses dual numbers.
- Pro: Computes partial derivatives of all outputs f(x)i with respect to one input xj in time proportional to computation of f(x) –
- Con: Slow for high dimensional inputs (e.g. vector-valued x)
- Required: Algorithm for computing f(x)
Describe the finite difference method (a pro, con, and requirement)
When is it appropriate to use?
- Pro: Great for testing implementations of backpropagation –
- Con: Slow for high dimensional inputs / outputs
- Con: In practice, suffers from issues of floating point precision
- Required: Ability to call the function f(x) on any input x
- only appropriate to use on small examples with an appropriately chosen epsilon
Describe symbolic differentiation (2 notes, a pro, con, and requirement)
- Note: The method you learned in high-school –
- Note: Used by Mathematica / Wolfram Alpha / Maple –
- Pro: Yields easily interpretable derivatives –
- Con: Leads to exponential computation time if not carefully implemented –
- Required: Mathematical expression that defines f(x)