Module 8a - Apache Spark Flashcards
<p>What is Apache Spark?</p>
<p>Apache Spark is an open-source framework/tool used for large-scale data processing.</p>
<p>Where is Spark data stored?
| <br></br>What language is it written in?</p>
- Spark data is stored in-memory
- Written in Scala, runs on JVM
What is a benefit of Spark being run on JVM?
- All the Java methods can be invoked and used natively
- All other benefits from using a VM to run a program (safety, isolation, replicability, etc)
What is a Resilient Distributed Data set (RDD)? What does it represent? Is it mutable?
RDD is the basic abstraction in Spark. It represents an immutable, partitioned collection of elements that can be operated on in parallel
<p>RDDs (Resilient Distributed Dataset) are data structures. what are their key characteristics?</p>
- Fault tolerant
- Immutable
- Is Partitioned (is a list of items)
- Optimized to be operated on in parallel
- Lets users explicitly persist intermediate results in memory
<p>What was the problem with Hadoop MapReduce that lead to the development of Spark?</p>
<p>Hadoop MR lacked abstractions for leveraging distributed memory.
<br></br>This made it inefficient for applications that reuse intermediate results across multiple computations.</p>
What is lineage with respect to RDD?
How an RDD was derived from other RDDs. It is used to rebuild an RDD in the event of a failure
(direct definition)
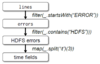
<p>What are Transformations in Apache Spark?</p>
<p>Data operations that convert one RDD or a pair of RDDs into another RDD</p>
<p>What are "Actions" in Spark?</p>
<p>Data operations that convert an RDD into an output. Ex: number or a sequence of value</p>
<p>What happens with the Spark scheduler when an action is invoked on an RDD?</p>
<p>The Spark Scheduler examines the lineage graph of the RDD and builds a directed acyclic graph (DAG) of transformations</p>
<p>After the Spark Scheduler builds a DAGof transformations, they are further grouped into "stages". What is a "stage"?</p>
<p>A Stage is a collection of transformations with <strong>narrow dependencies</strong>, meaning that one partition of the output depends only on one partition of each input. Ex: filtering</p>
In Apache Spark what are characteristics ofnarrow dependencies?
What are characteristics of of wide dependencies?
Narrow Dependencies:
- One partition of the output depends on only one partition of each input (eg: map)
- Transformations with narrow dependencies can be pipelined together effectively
Wide Dependencies:
- One partition of the output depends on multiple partitions of some input (eg: groupByKey)
- Transformations with wide dependencies require a shuffle
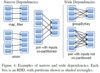
Describe how Spark typicallyexecutesof a job in stages while leveraging pipelining. How does the program go from initial RDDs, to intermediate RDDs, to a final RDD?
What is the benefit of executing jobs in stages on throughput?
We can define initial RDDs, intermediate RDDs (which lead towards to final) and a final RDD. Narrow and Wide dependency transformations must be applied to the initial RDDs to bring them towards the intermediate RDDs and then eventually towards the final RDDs.
These transformations are broken down into stages, which are pipelined (run in parallel) - significantly improving throughput
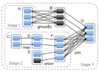
Describehow the word count problem (get the frequency of every word in a file) can be done in Scala
How the code look like?
- Build an RDD using data in HDFS
- Transform textFile to counts by applying a sequence of the following operators:
- toeknize each line of input
-map each word to the tuple (word, 1)
- reduce the word counts - Dump the output back to HDFS

<p>Classify the following transformations as narrow or wide dependency:</p>
<p>- FlatMap</p>
<p>- Map</p>
<p>- ReduceByKey</p>
<p>Note that a narrow dependency is a transformationin which there is a 1 to 1 mapping between keys and values, whereas wide depenency is a transformationin which there is a many to 1 mapping</p>
FlatMap - Narrow Dependency
Map - Narrow Dependency
ReduceByKey - Wide Dependency
<p>What does a FlatMap transformationdo?</p>
Returns a new array formed by applying a given callback function to each element of the array, and then flattening the result by one level.
Equivalent to calling map() then calling flat().
flat() takes everything in subarrays and moves them up alevel (into the parent array)
<p>What is the Scala placeholder Syntax?</p>
Transformations are often specified using anonymous functions, which use Scala’s convenient placeholder syntax (“_” notation)
For example, “_ + 1” turns into “x => x+1”
In Scala what can thedata type ofan element of an RDD be?
An element of an RDD can be a single item, an array of items, or a tuple (can be any user-defined class)
<p>Can you run Spark without Scala?</p>
<p>No. You need Scala. Spark is an API for Scala</p>
<p>In Scala, how can the underscore token be used with a tuple?</p>
The underscore is used to select different elements of a tuple:
var t = (4,3,2) var sum = t._1 + t._2 + t._3
<p>In scala what are round brackets used for in the conext of arrays? How do you remove the first `n` elements of an array.list in scala?</p>
Round brackets are used to select different elements of an array
<p> val myarr = Array(4,3,2)
</p><p> if (myarr(0) < myarr(1)) {...}
Use drop(n) to remove the first `n` elements of an array/list</p>
What is the Purpose of PageRank?
How does it work on a high level?
What is the idea behind it?
What is the amount of iterations in PageRank?
PageRank is used to rank websites/nodes/documents to a number which measures the importance of it. It works iteratively, with an arbitrary number of iterations
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites/documents/nodes.
<p>What is the purpose of the damping factor "d" in Scala PageRank?</p>
The probability at any step that the agent which is traversing the graph of connected documents will continue is the damping factor “d”, typically = 0.85.
This is in order to guarantee convergence. The number of iterations can go onto infinity since rankings can always be updated.Damping stabilizes the system ensures that the algorithm will eventually converge.
<p>In PageRank, when the algorithm begins, what are the rankings typically initialized to?</p>
<p>All rankings in the collection of nodes/documents are initialized to 1/N, where N is the number of nodes/documents. If X is a node in the collection of documents, the PR(X) = 1/N for all X</p>
<p>Suppose we're dealing with PageRank, andall the documents have been initialized. In each iteration, each ranking of each node is updated.What is the formula that(PR[X])updated against?</p>
<p>Assume that the neighbors/connections of X are known</p>
<p>PR(X) = (1-d)/N + d*(SUM r/n FOR EACH NEIGHBOR)</p>
<p>d = damping factor, typically 0.85</p>
<p>N = number of nodes in the network</p>
<p>r = the ranking of thatneighbor (this depends on the neighbor)</p>
<p>n = the number of neighbors that this neighbor has (this depends on the neighbour)</p>

<p>How is the PageRank implemented in Scala?</p>
<p>- The nodes are loaded from the file system using HDFS</p>
<p>- The ranks are loaded into an RDD data structure</p>
<p>- A loop is run topopulate the RDD data structure with the default ranks</p>
<p>- In the loop, each node in the RDD data structure is updated iteratively one by one with the contributions of each neighboring page</p>
<p>- Also in the loop, the damping constant (1-d)/N is added to each value in the RDD data structure</p>
<p>Describe the Lineage graph for PageRank implemented in Spark. Remeber that a lineage graph is a DAG showing how RDDs are inherited from other RDDs thorugh transformations</p>

<p>PageRank can be implemented using Hadoop as well as Spark. It is typically done in Spark though. What are 2weaknesses of using Hadoop for PageRank? Why is Spark better?</p>
<p>Hadoop weaknesses:</p>
<p>- The intermediate output is dumped to HDFS after each iteration, because each iteration requires a seperate MapReduce process. This is very I/O intensive and inefficient</p>
<p>- If a convergence test is used to terminate the iterative loop instead of computing for a fixed number of iterations, then an additional MapReduce program is required in each iteration to evaluate the convergence condition.</p>
<p>Why Spark is better:</p>
<p>Spark is able to cache intermediate data (nodes/documents & ranks) in main memory provided that it has sufficient resources</p>
<p>What does the ".persist()" flag added to the end of an RDDvariablesignify in Scala?</p>
<p>It requests that Spark holds data (for PageRank, this would be the links/documents) in main memory, in RDD.</p>
<p>As such, when ".persist()" is added, the outputs of transformations are cached automatically (subject to resource limits) in main memory</p>
