1
Q
machine learning
A
- finding patterns from data using algorithms
- exploiting them to carry out some task
2
Q
uses of machine learning
A
- detect or learn structures and relationships in data
- label or assign observations to different classes
- make predictions based on previously obtained knowledge
3
Q
Bayesian framework
A
- bayes theorem
- updates the probability of a hypothesis as more information becomes available
4
Q
inputs vs outputs
A
- inputs:
- discrete
- continuous
- scalar or vector-valued
- outputs:
- determined by the task to be performed
5
Q
machine learning tasks
A
- classification
- output composed of discrete labels (classes)
- identify class memberships of different inputs
- regression
- where outputs are continuous random variables or ordered discrete variables
- predict or estimate a response to a given input
6
Q
supervised vs unsupervised learning
A
- supervised:
- data used to train an algorithm to predict the response of a new input
- labelled data
- unsupervised:
- looks for structure in the outputs (or inputs) without reference to inputs (or outputs)
- discovers new knowledge
- unlabelled data
7
Q
supervised learning
A
- relationship known between inputs and outputs:
- y = f(x) + ε
- ε = some error function
- generally ignored in classification (=0)
- allows you to determine optimal function for further predictions about new data
8
Q
unsupervised learning
A
- finding new knowledge from data without training an algorithm using known input-output pairs
- similar inputs and outputs grouped to find a relationship
- density estimation problem
- useful when training data is rare and expensive (often)
9
Q
clustering
A
- example of unsupervised learning
- group together outputs into clusters
- define number of clusters C ad hoc or with related model
- estimate which cluster each data point belogns to
- assign attributes to points in a cluster e.g. ‘normal’ height
- cluster label given by z
- hidden variable = inferred, not directly observed
- similarity of points defined by distance
10
Q
distance function
A
- d(x,y)
- must fulfil:
- d(x,y) ≥ 0
- d(x,y) = 0 iff x = y
- d(x,y) = d(y,x) (symmetry)
- d(x,y) ≤ d(x,z) + d(z,y) (triangular inequality)
- any point in between increases distance
11
Q
distance
A
- different types
- different properties and convenience levels
- generally euclidean distance
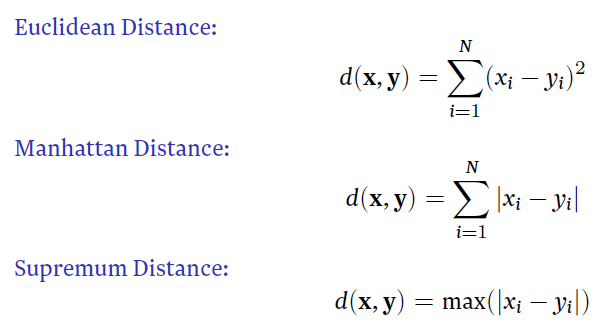
12
Q
types of clustering
A
- similarity-based
- N points
- input = N x N matrix of pairwise distances
- relative distance between all pairs of points
- gene expression, DNA sequences
- feature-based
- each of N objects has M different features
- input = N x M matrix
- patient/control samples
13
Q
k-nearest-neighbour clustering
A
- non-parametric classification
- K = number of neighbours taken into consideration
- look for K nearest neighbours of input x to decide its state
- if all neighbours same cluster designate to that cluster
- if K > 1 and neighbour sin different clusters
- assign probabilities and assign to highest
- assign all points and paint
- can also use K = 1
14
Q
hierarchical clustering
A
- allows clusters to be nested inside one another
- main method
- use clustering diagrams to create gene expression profiles
- produces binary trees/dendrograms
15
Q
agglomerative clustering
A
- type of hierarchical clustering
- N observations assigned to their own cluster C
- merge 2 most similar clusters
- minimum distance
- create new cluster Ck until only 1 cluster remains
- cluster distance can be determined with:
- average position of points in each cluster
- position of closest point in each cluster
16
Q
divisive clustering
A
- another method of hierarchical clustering
- faster than agglomerative
- assing all objects to one cluster and split
- use dissimilarity instead pf similarity to split
- harder to program
- but looks at all data from the beginning
- agglomerative doesn’t - can mislead early on
17
Q
regression
A
- supervised learning
- use a model to describe continuous response
- see how well data fits model
- need the right model
- e.g. linear/non-linear
- may look different to what it actually is so be wary
18
Q
process of regression
A
- model building
- variable selection
- relation of response to covariates
- data fitting
- effect of each independent variable
- confidence in the model’s description
- statistical significance
- model checking
- do assumptions hold
- model validation
- does it work on new data
19
Q
statistical models
A
- components:
- initial observed relationship between X and Y
- before assumptions have been made about response distribution
- error
- random variable
- independent
- normally distributed
- initial observed relationship between X and Y
20
Q
multiple testing problem
A
- need to adjust significance/p value when testing many hypotheses
- more tests means higher number of apparently signficant results that are due to chance
- bonferroni correction
- individual hypotheses tested with p = α/m
- α = overall desired p value
- m = number of hypotheses
- individual hypotheses tested with p = α/m
21
Q
problems in statistical learning theory
A
- multiple testing
- curse of dimensionality
- inference more difficult as dimension increases
- number of independent variables
- inference more difficult as dimension increases
- model selection
- e.g. K in K-nearest
- also overfitting
- no free lunch theorem
- no universally best model
- algorithms behave differently depending on context
bioinformatics
flashcards
Decks in class (20)
# Cards
-
sequencing & assembly17
-
sequence assembly19
-
genome annotation10
-
ab initio gene prediction7
-
analysis of gene expression17
-
analysis of gene expression 212
-
sequence alignment17
-
database searching18
-
protein feature analysis10
-
protein structure prediction23
-
ab initio structure prediction11
-
drug design17
-
computer-aided drug design23
-
machine learning21
-
genome variation25
-
single cell transcriptomics25
-
phylogenetics10
-
prediction of protein function13
-
evolution of protein function14
-
eukaryotic gene prediction14
