HBX- BA - 3 Flashcards
Null Hypothesis
A null hypothesis is a statement about a topic of interest, typically based on historical information or conventional wisdom. We start a hypothesis test by assuming that the null hypothesis is true and then test to see if we can nullify it, which is why it’s called the “null” hypothesis. The null hypothesis is the opposite of the hypothesis we are trying to substantiate (the alternative hypothesis).

Alternative Hypothesis
The alternative hypothesis (the opposite of the null hypothesis) is the theory or claim we are trying to substantiate. If our data allow us to nullify the null hypothesis, we substantiate the alternative hypothesis.

How Null/Alternate Hypothesis system works….
It’s similar to a jury trial *It’s guilty or not guilty (They can’t declare them innocent!!! Only not guilty! Same with these tests)
We either REJECT the Null Hypothesis or FAIL TO Reject the Null Hypothesis


Reject the null hypothesis
The null hypothesis is that the average satisfaction rating has not changed, that is, that the population mean μμ is still equal to 6.7. Drawing a sample with an average satisfaction rating of 9.9 from a population that has an average rating of 6.7 is extremely unlikely, so we would almost certainly reject the null hypothesis and conclude that the average satisfaction rating is no longer 6.7.
At what point do we reject the null hypothesis?
- We first have to define what do we mean by likely? (Normally 95%)
-
Construct a range of likely sample means
- We should use the HISTORICAL Mean to center our range (We do this because we always assume that the null hypothesis is true)
- Since the central limit theorem tells us that the distribution of sample means follows a normal distribution, we can use the familiar properties of the familiar curve to construct this range.
For example, recall that 95% of a normal distribution falls within 2 standard deviations of the mean. This means that the z value associated with this about 2 (1.96). We can find this 2 ways
- The Null hypothesis is true if it fits within this range!
- If we take a sample and the mean of that sample does not fall between the range- we REJECT the null hypothesis. (If it is, it’s very unlikely to choose a sample that falls out of that range 5%)
The reach outside the 95% range is called the rejection region


6.7
We always start a hypothesis test by assuming that the null hypothesis is true. Thus, the center of the range of likely sample means is the historical average—the average specified by the null hypothesis, in this case is 6.7. Remember, the null hypothesis is that showing old classics has not changed the average satisfaction rating.
Suppose we wanted to calculate a 90% range of likely sample means for the movie theater example (historical mean 6.7, standard dev 2.8, sample size 196). Select the function that would correctly calculate this range.
6.7±CONFIDENCE.NORM(0.10,2.8,196)
The range of likely sample means is centered at the historical population mean, in this case 6.7. Since this is a 90% range of likely sample means, alpha equals 0.10.
Suppose we wanted to calculate a 90% range of likely sample means for the movie theater example but our sample size had been only 15. (same historical mean 6.7, same standard dev 2.8) Select the function that would correctly calculate this range.
6.7±CONFIDENCE.T(0.10,2.8,15)
The range of likely sample means is centered at the historical population mean, in this case 6.7. We must use CONFIDENCE.T since the sample size is less than 30.
Significance Level
The threshold for deciding whether to reject the null hypothesis. The most commonly used significance level is .05 (corresponding to a confidence level of 95%), which means we would reject the null hypothesis when the p-value < .05. The significance level is represented by the Greek letter α (alpha) and is equal to 1-confidence level.
Significance Level = 1 – Confidence Level
- The significance level defines the rejection region by specifying the threshold for deciding whether or not to reject null hypothesis. When the p-value of a sample mean is less than the significance level, we reject the null hypothesis.
- The significance level is the area of the rejection region, meaning the area under the distribution of sample means over the rejection region.
- The significance level is the probability of rejecting the null hypothesis when the null hypothesis is actually true.
- The significance level also defines the confidence level. ((The confidence level tells us how confident we can be that the range of likely sample means contains the true population mean. We should always specify the significance level (and thus the confidence level) before performing a hypothesis test.))
If we use the most commonly used significance level of 0.05, we draw our conclusions on whether the sample’s p-value is less than or greater than 0.05. If the p-value is less than 0.05, we reject the null hypothesis. If the p-value is greater than or equal to 0.05, we fail to reject the null hypothesis. It is always important to use your managerial judgment when making decisions, especially when the p-value is very close to the significance level.
If we specify a 75% confidence level, what percentage of sample means do we expect to fall in the rejection region?
25%
The significance level equals the area of the rejection region. The significance level equals 1–confidence level. In this case, 1–0.75=0.25, that is, 25%.
If the significance level of a hypothesis test is 10%, for which of the following p-values would you reject the null hypothesis? Select all that apply.
- 0.08
- 0.89
- 0.05
- 0.11
- 0.08
- 0.05
We reject the null hypothesis if the mean of our sample falls within the rejection region. The area of the rejection region is equal to the significance level, so we reject the null hypothesis when the p-value is less than the significance level. Since 0.08 & .05 are less than 0.10, we would reject the null hypothesis. Remember: the lower the p-value, the stronger the evidence is against the null hypothesis. Note that another option is also correct.
Define P-Value and state How to Calculate in Excel.
If we have sufficient evidence to reject a null hypothesis. We may wish to know how strong our evidence is.
A p-value can be interpreted as the probability, assuming the null hypothesis is true, of obtaining an outcome that is equal to or more extreme than the result obtained from a data sample. The lower the p-value, the greater the strength of statistical evidence against the null hypothesis.
When we take a sample, we reject a hypothesis if a samples p value is less than 5%
Although there are multiple ways to calculate a p-value in Excel, we will use a t-test, the most common method used for hypothesis tests. The t-test uses a t-distribution, which provides a more conservative estimate of the p-value when the sample size is small. Recall that as the sample size increases, the t-distribution converges to a normal distribution, so a t-distribution can be used for large samples as well. Companies tend to use the t-distribution rather than the normal distribution because it is safe for both small and large samples.
=T.TEST(array1, array2, tails, type)
- array1 is a set of numerical values or cell references. We will place our sample data in this range.
-
array2 is a set of numerical values or cell references.
We have only one set of data, so we will use the historical mean. (To do this, we will need to create a new row just filled with the historical mean) -
tails is the number of tails for the distribution. It can be either 1 or 2.
- 1 is for a one-sided test - this is only used if this information is ABSOLUTELY KNOWN
- 2 is for a 2 sided test
-
type can be 1, 2, or 3.
- Type 1 is a paired test and is used when the same group from a single population is tested twice to provide paired “before and after” data for each member of the group.
- Type 2 is an unpaired test in which the samples are assumed to have equal variances.
- Type 3 is an unpaired test in which the samples are assumed to have unequal variances. The variances of the two columns are clearly different in our case, so we use type 3. There are ways to test whether variances are equal, but when in doubt, use type 3.
Another way to calculate the p-value for a 2 sided test is to calculate the p-value with 2 tails and then divide the answer by 2!
Calculate the p-value for the movie theater ratings from the 196 people that were sampled. Remember that the sample mean is 7.3 and the sample standard deviation is 2.8. Before we begin, we must create a second column of data.
- Have Sample information in Excel in column 1 (This is normally given in this course)
- Create a column for the Historical Mean
- Enter the function =T.TEST(array1, array2, tails, type)
Since the p-value, 0.0026, is less than the 0.05 significance level, we reject the null hypothesis and conclude that the customer satisfaction rating has changed.


If the null hypothesis is true, the likelihood of obtaining a sample with a mean at least as extreme as 7.3 is 0.26%
The p-value of 0.0026 indicates that if the population mean were actually still 6.7, there would be a very small possibility, just 0.26%, of obtaining a sample with a mean at least as extreme as 7.3. Equivalently, since 7.3–6.7=0.6, this p-value tells us that if the null hypothesis is true, the probability of obtaining a sample with a mean less than 6.7–0.6=6.1 or greater than 6.7+0.6=7.3 is 0.26%.
What are Type I and Type II errors that can happen?
- A type I error is often called a false positive (we incorrectly reject the null hypothesis when it is actually true).
- A type II error is often called a false negative (we incorrectly fail to reject the null hypothesis when it is actually not true). Note that since we have no information on the probabilities of different sample means if the null hypothesis is false, we cannot calculate the likelihood of a type II error.

If you are performing a hypothesis test based on a 0.10 significance level (10%), what are your chances of making a type I error?
10%
- The probability of a type I error is equal to the significance level (which is 1–confidence level). A 10% significance level indicates that there is a 10% chance of making a type I error.
A car manufacturing executive introduces a new method to install a car’s brakes that is much faster than the previous method. He needs to test whether the brakes installed with the new method are as safe and effective as those installed with the previous method. His null hypothesis is that the brakes installed using the new method are as safe as those installed using the old method. In this situation, would it be worse to make a type I error or a type II error?
Type II
A type II error, or false negative, would be that the brakes are actually not safe but the manufacturer deems them safe and proceeds with the new installation method. This would be worse than returning to the slower method, because the unsafe cars could cause injuries or fatal accidents.
One-sided hypothesis test & How to enter in Excel (with the example below)
A movie theater manager has reason to believe that showing old classics has increased the customer satisfaction rating. ((The historical average satisfaction rating was 6.7 and that the random sample of 196 moviegoers has an average satisfaction rating of 7.3 and a standard deviation of 2.8.)) Calculate the upper bound of the 95% range of likely sample means for this one-sided hypothesis test
A hypothesis test that tests for a difference in a parameter in only one direction (e.g., if the mean of one group is greater than the mean of another group). This test should be used only if the researcher has strong convictions about the direction of the change, for example, that the mean of Group A cannot be less than the mean of Group B. In such a case, the null hypothesis might be that the mean of Group A is less than or equal to the mean of Group B, and the alternative hypothesis is that the mean of Group A is greater than the mean of Group B. The rejection region for a one-sided hypothesis test appears in only one tail of the distribution.
EXCEL
Use the CONFIDENCE.NORM function.
-
We must first determine what two-sided test would have a 5% rejection region on the right side. Since the distribution of sample means is symmetric, a two-sided test with a 10% significance level would have a 5% rejection region on the left side of the normal distribution and a 5% rejection region on the right side.
Thus, the upper bound for a two-sided test with alpha=0.1 will be the same as the upper bound on a one-sided test with alpha=0.05. - The margin of error is CONFIDENCE.NORM(0.1,Standard Dev,Sample Size)
The upper bound of the 95% range of likely sample means for this one-sided hypothesis test is the population mean plus the margin of error.
For the example mentioned…. CONFIDENCE.NORM(0.1,2.8,196)=0.33. The upper bound of the 95% range of likely sample means for this one-sided hypothesis test is the population mean plus the margin of error, which is approximately 6.7+0.33=7.03.

Two- Sided Hypothesis Test
two-sided hypothesis test
A hypothesis test that tests for any difference in a parameter (e.g., if the mean of one group is different – either greater than or less than – the mean of another group). In a two-sided test, the null hypothesis is that the parameter is the same (e.g., that the means of two groups are the same), whereas the alternative hypothesis is that the parameter is different (e.g., the means of two groups are different). The rejection region for a two-sided hypothesis test is divided into two parts in the tails of the distribution.
The manager now has reason to believe that showing old classics has increased the customer satisfaction rating. (Historical Mean 6.7) For this one-sided hypothesis test, what alternative hypothesis should he use? what should he use as the null hypothesis?
μ > 6.7
The manager has reason to believe that the new artistic approach has increased the average customer satisfaction, so for a one-sided test he should use the alternative hypothesis
Ha : μ > 6.7
This is the claim he wishes to substantiate
μ ≤ 6.7
If our alternative hypothesis is that the average satisfaction rating has increased, then the null hypothesis is that the rating is the same or lower. Thus, if our alternative hypothesis is that μ>6.7, our null hypothesis is that μ≤6.7.
We have found that for the movie theater example, the p-value for the one-sided hypothesis test is 0.0013. Assuming a 0.05 significance level, what would you conclude?
Reject the null hypothesis and conclude that the average satisfaction rating has increased
Because the p-value is less than the specified significance level of 0.05, we reject the null hypothesis. Our alternative hypothesis, the claim we wish to substantiate, is μ > 6.7, so by rejecting the null hypothesis we are able to conclude that the average satisfaction rating has increased.
Suppose again that the movie theater manager had gathered a sample that had an average customer satisfaction rating of 7.05 but in this case had firm convictions that if the average rating had changed, it had increased. Given what you know about the relationship between the p-values of one-sided and two-sided tests, would you reject or fail to reject the null hypothesis, H0 : μ ≤ 6.7, at a 5% significance level? As noted above, for a two-sided test with H0 : μ = 6.7 and Ha : μ ≠ 6.7 , the p-value of 7.05 is approximately 0.07.
Reject the null hypothesis
The p-value for a one-sided hypothesis test is half the p-value of a two-sided test for the same value. The p-value for 7.05 for the two-sided hypothesis test was 0.07, so the p-value for 7.05 for the one-sided test is 0.035. Because 0.035 is less than the significance level, 0.05, we reject the null hypothesis and conclude that the average customer satisfaction rating has increased. Note that the outcomes of one-sided and two-sided tests can be different. Just because we did not reject the null hypothesis for the two-sided test does not mean that we will have the same result for the one-sided test.
Single Population vs. Two-population Hypothesis test
And how to perform a 2- Population Hypothesis Test in Excel.
Single-population hypothesis test
A test in which a single population is sampled to test whether a parameter’s value is different from a specific value (often a historical average).
Two-population hypothesis test
A test in which samples from two different populations are compared to see if the parameter of interest is different between the two populations.
To perform a two-sample test in Excel- we use the same T.TEST function we used earlier. The only difference is that we use the actual data from the second sample for our second column of data.
=T.TEST(array1, array2, tails, type)
- array1 is a set of numerical values or cell references. This will be one sample.
- array2 is a set of numerical values or cell references. This will be the other sample.
- tails is the number of tails for the distribution.
- It should be set to 1 to perform a one-sided test;
- to 2 to perform a two-sided test.
- type can be 1, 2, or 3.
- Type 1 is a paired test and is used when the same group is tested twice to provide paired “before and after” data for each member of the group.
- Type 2 is an unpaired test in which the samples are assumed to have equal variances.
- Type 3 is an unpaired test in which the samples are assumed to have unequal variances. Since we have no reason to believe that the variances of our two samples are the same, we use type 3. There are ways to test whether variances are equal, but when in doubt, use type 3.
Suppose we want to know whether students who attend a top business school have higher earnings than those who attend lower-ranked business schools. To find out, we collect the average starting salaries of recent graduates from the top 100 business schools in the U.S. We then compare the salaries of those who attended the schools ranked in the top 50 to the salaries of those who did not. Should we perform a one-sided hypothesis test or a two-sided test?
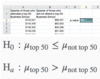
Suppose we want to know whether students who attend a top business school have higher earnings. What is the null hypothesis?
Suppose we want to know whether students who attend a top business school have higher earnings. What is the alternative hypothesis?
One-sided
Since we are interested only in whether the average salaries of people who attended the top 50 business schools are higher than the salaries of those who did not, we should perform a one-sided test. If we were interested in learning whether the salaries of the people who went to the top 50 business schools were different (either higher or lower) than those from the other schools, we would conduct a two-sided test.
μ top 50 ≤ μ not top 50
The null hypothesis is the claim we assume to be true. It is the opposite of the alternative hypothesis—the claim we wish to substantiate. In this case, our alternative hypothesis is that people who attended a school ranked in the top 50 earn more than those who did not. The opposite of this is that people who attended a school ranked in the top 50 earn less than or equal to those who did not.
μ top 50 > μ not top 50
The alternative hypothesis is the claim we wish to substantiate. In this case, we want to establish that people who attended a school ranked in the top 50 earn more than those who did not, so μ top 50 > μ not top 50
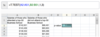
Below are the average starting salaries of recent graduates from the top 100 U.S. business schools. Use the T.TEST function to test whether those attending a top 50 business school have higher earnings than those who do not. Remember that this is a one-tailed test.
Remember that this is a one-tailed test, so we should set the tails variable to 1. Also, make sure to use test type 3 to indicate a two-sample test with unequal variances.
Before conducting a hypothesis test we…..
-
Determine whether to analyze a change in a single population or compare two populations.
- We perform a single-population hypothesis test when we want to determine whether a population’s mean is significantly different from its historical average.
- We perform a two-population hypothesis test when we want to compare the means of two populations—for example, when we want to conduct an experiment and test for a difference between a control and treatment group.
-
Determine whether to perform a one-sided or two-sided hypothesis test.
- We perform two-sided tests when we do not have strong convictions about the direction of a change. Therefore we test for a change in either direction
- We perform a one-sided test when we have strong convictions about the direction of a change—that is, we know that the change is either an increase or a decrease.
To conduct a hypothesis test, we must follow these steps:
To conduct a hypothesis test, we must follow these steps:
- State the null and alternative hypotheses.
- Choose the level of significance for the test.
- Gather data about a sample or samples.
- To determine whether the sample is highly unlikely under the assumption that the null hypothesis is true, construct the range of likely sample means or calculate the p-value.
- The p-value is the likelihood of obtaining a sample as extreme as the one we’ve obtained, if the null hypothesis is true.
- The p-value of a one-sided hypothesis test is half the p-value of a two-sided hypothesis test.
- If the sample mean falls in the range of likely sample means, or if its p-value is greater than the stated significance level, we do not have sufficient evidence to reject the null hypothesis.
- If the sample mean falls in the rejection region, or if it has a p-value lower than the stated significance level, we have sufficient evidence to reject the null hypothesis.
- We can never accept the null hypothesis.
- Trade-offs: The higher the confidence level (and therefore the lower the significance level), the lower the chance of rejecting the null hypothesis when it is true (type I error or false positive). But the higher the confidence level, the higher the chance of not rejecting it when it is false (type II error or false negative).
If you are performing a hypothesis test based on a 20% significance level, what are your chances of making a type I error?
20%
The probability of a type I error is equal to the significance level, which is 1–confidence level.
If you are performing a hypothesis test based on a 90% confidence level, what are your chances of making a type I error?
10%
The probability of a type I error is equal to the significance level, which is 1–confidence level. A 90% confidence level indicates that the significance level is 10%. Therefore there is a 10% chance of making a type I error.
If you are performing a hypothesis test based on a 90% confidence level, what are your chances of making a type II error?
It is not possible to tell without more information
The confidence level does not provide any information about the likelihood of making a type II error. Calculating the chances of making a type II error is quite complex and beyond the scope of this course.
