Why is data now accessible to nearly every business?
Easier to collect and cheaper to host Software technologies and platforms can help facilitate collection, analysis, and storage of valuable information
What is data?
Collection of facts such a numbers, descriptions and observations
What is a common way of classifying data?
Stuctured, semi-structured, unstructured
What is structured data?
Tabular data represented by rows and columns with predefined data types in a database
What is a relational database?
Databases that hold tabular data
What is semi-structured data
Information that doesn’t reside in a relational database but still has some structure to it. Examples: JSON format documents, key-value stores, graph databases
What is a key-value database
Store Associative arrays Key serves as a unique identifier to retrieve a specific value. Value can be anything from a number or a string or a complex object like a JSON file Stores data as a single collection without structure or relation

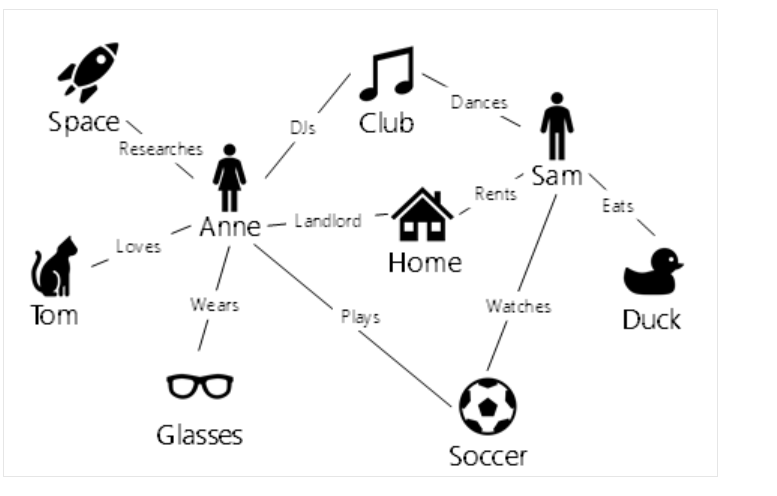
What is a graph database?
Used to store and query information about complex relationships
Graph contains nodes (information about objects) and edges (information about the relationships between objects)
How is structured data typically stored?
Relational database such as SQL Server or Azure SQL Database
How is unstructured data typically stored?
Azure Blob (Binary Large Object)
How is semi-structure data typically stored?
Azure Cosmos DB
What are teh level of access that users can be given to data?
Read-only - can’t modify or create new
Read/write - can view and modify
Owner - can add new users and remove existing users
What are the two broad data processing solutions?
Transaction processing
Analytical
What is a transactional system?
Records transactions which is the primary function of business computing
Examples include movement of money between accounts in a banking system,
or in a retail system tracking payments for goods and services from customers
A transaction is a small, discrete unit of work
Usually high volume, sometimes handling many millions of transactions in a single day
Often referred to as OLTP (Online Transactional Processing)
Data being processed has to be accessible very quickly
How is fast processing supported in a transactional system?
Data often dividedi into small pieces, i.e. each table involved in a transaction only contains the columns necessary to perform the transactional task, i.e
in for bank transfers, a table holding information about the funds in the account might only contain hte account number and current balance
Splitting tables out into separate groups of columns like this is called normalized
Normalization can enable a transactional system to cache much of the information required to perform transactions in memory and speed throughput
What is a downside of transactional systems for querying?
Queries involving normalized tables will frequently need to join data across several tables back together again?
This makes it difficult fo rbusiness users who might need to examine the data.
What is an analytical system?
Designed to support business users who need to query data and gain a big picture view of the information held in a database
Capture raw data and use it to generate insights
Most need to perform the following tasks:
- data ingestion
- data transformation
- data querying
- data visualization
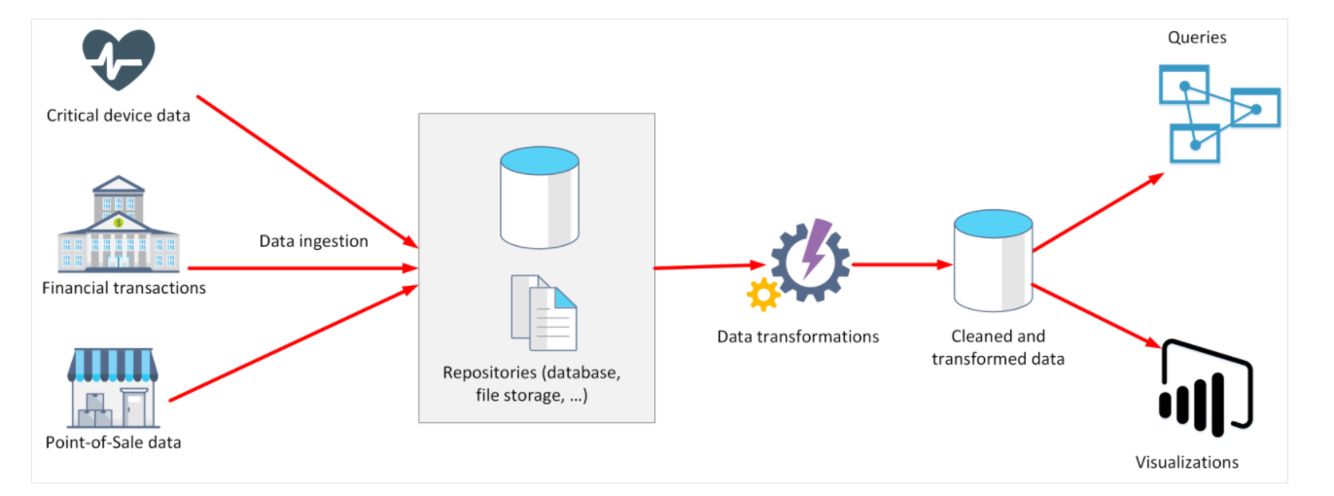
What is data ingestion
Process of capturing raw data
Can be taken from control devices, point-of-sale devices, weather stations, recording of the movement of money between bank accounts, etc.
Can come from a separate OLTP system
Data needs to be stored in a repository which could be a file store, a document database, or even a relational database
Why is data transformation/processing needed?
Raw data might not be in a format suitable for querying
Data might contain anomolies that should be filtered out or standardized
Data might need to be agregated to KPIs (Key Performance Indicators). Key Performance Indicators are how businesses are measured for growth and performance
Why is data querying needed?
Most database management systems provide tools to enable you to perform ad-hoc queries against data and generate regular reports
May be looking for trends or attempting to determine cause of problems in your system
Why is data visualization needed?
Data represented in tables aren’t always intuitive
Describe benefits, problems of relational data as well as solutions to known potential issues
Tables with rows and columns
Rigid structure can cause some problems, i.e. how to handle multiple addresses for one person - is it 4 columns because assume can’t be more than that
Normalization will solve these types of problems
Primarily used to handle transaction processing
What is normalization? What is the downside
In relational data, data is split into a large number of narrow (few columns), well-defined tables with references from one table to another.
Querying data often requires reassembling data from multiple tbles by joining the data back together at run-time. These types of queries can be expensive.

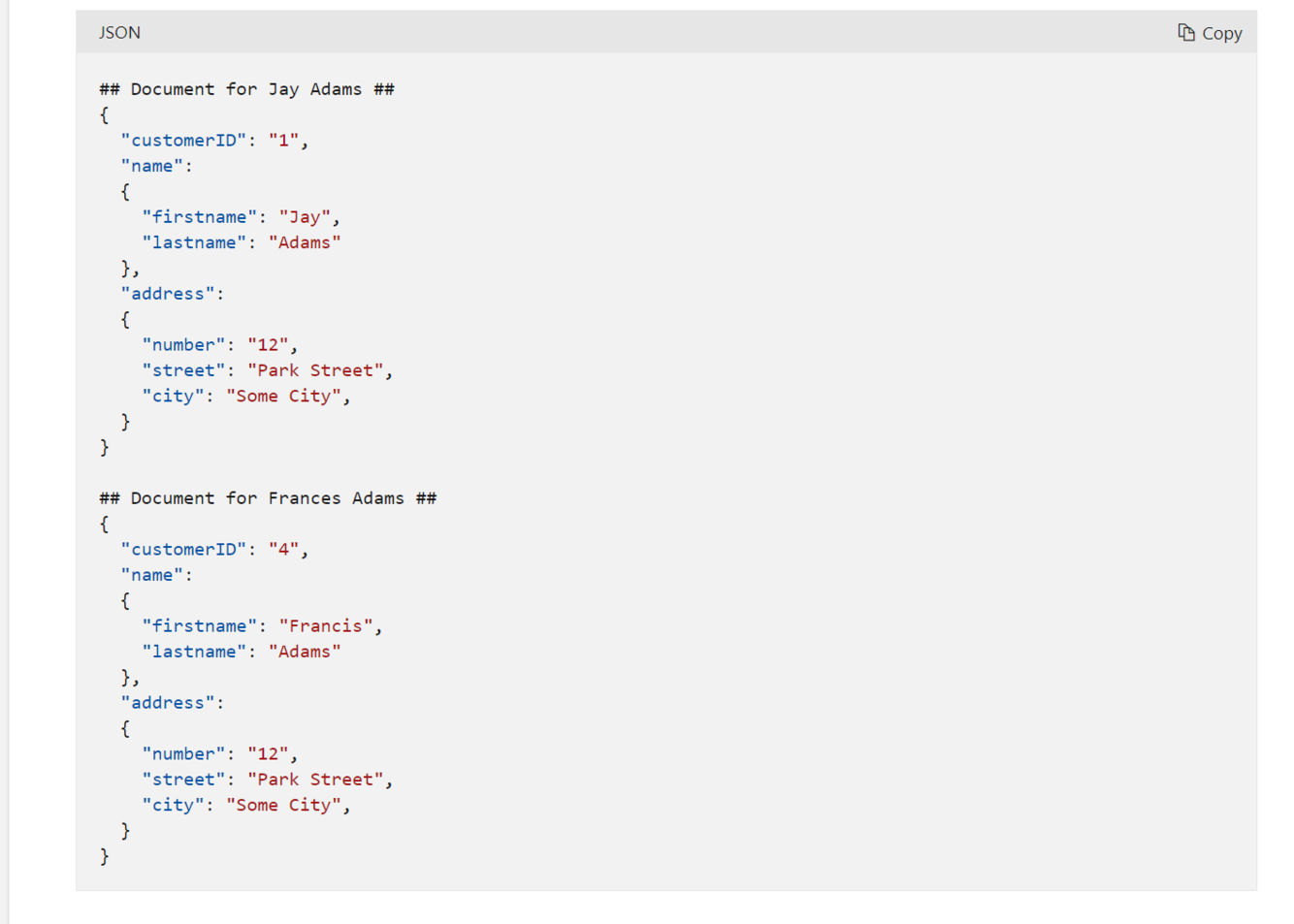
Describes non-relational database as well as its positive and negative features
Store dat in a format tat more closely matches the original structure,i.e. in a document database
So to retrieve the details of a customer, incuding the address, just need to read a single document
But means information can be duplicated (i.e. 2 customers share an address) and make maintenance more complex (2 documents must be updated when a couple changes address)