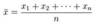Exam 2 Flashcards
(87 cards)
What are dependent variables and what are examples?
The outcome variable measured
May be changed or influenced by manipulation of the independent variable
What are conceptual defined dependent variables?
Conceptual variable - the general idea of what needs to be measured in a study: i.e. strength
Must be defined in specific measurable terms for use in the study (once defined, becomes the operational variable)
What are the levels of precision of measurement and what are examples?
The level of measurement/precision of the dependent variable is one factor that determines the choice of statistical tests that can be used to analyze the data
- Nominal (Count Data)
- Ordinal (Rank Order)
- Interval
- Ratio
What is reliability and why is it important?
Reliability: An instrument or test is said to be reliable if it yields consistent results when repeated measurements are taken
3 Forms of Reliability:
- Intra-rater reliability
- Inter-rater reliability
- Parallel-forms reliability
All three forms require comparisons of two or more measures taken from the same set of subjects
Requires a statistical measure of this comparison – correlation
Results of these statistical tests are 0 to 1, with 1 being a perfect correlation and 0 being no correlation
For a reliable comparison the association must be as close to 1 as possible and at least > 0.8
What is validity and why is it important?
Validity - the measure or instrument (measuring tool) is described as being valid when it measures what it is supposed to measure
A measure/instrument cannot be considered universally valid.
- Validity is relative to the purpose of testing
- Validity is relative to the subjects tested
Validity is a matter of degree; instruments or tests are described by how valid they are, not whether they are valid or not
Validity assessments can be made by judgment (judgmental validity) or by measurements (empirical validity)
Judgmental Validity
Based upon professional judgment of the appropriateness of a measurement or instrument
2 principle forms:
- Face validity
- Content validity
What are Sensitivity, Specificity and Predictive Values?
Clinical research often investigates the statistical relationship between symptoms (or test results) and the presence of disease
There are 4 measures of this relationship:
- Sensitivity
- Specificity
- Positive Predictive Values
- Negative Predictive Values
What are extraneous/confounding variables and what are examples?
Confounding or Extraneous Variables: Biasing variables – produce differences between groups other than the independent variables
These variables interfere with assessment of the effects of the independent variable because they, in addition to the independent variable, potentially affect the dependent variable
Analysis of the Dependent Variable
A single research study may have many dependent variables
Most analyses only consider one dependent variable at a time
Univariate Analyses- each dependent variable analysis is considered a separate study for the purposes of statistical analysis
What are operationally defined dependent variables and what are examples?
The specific, measurable form of the conceptual variable
The same conceptual variable could be measured many different ways; defined in each study
i.e: to define strength = Maximum amount of weight (in kilograms) that could be lifted 1 time (1 rep max)
Nominal Level of Precision
Score for each subject is placed into one of two or more, mutually exclusive categories
Most commonly, nominal data are frequencies or counts of the number of subjects or measurements which fall into each category.
Also termed discontinuous data because each category is discrete and there is no continuity between categories
There is also no implied order in these categories
Examples:
- Color of cars in parking lot
- Gender of subjects
- Stutter – yes/no
Can only indicate equal (=) or not equal (≠)
Ordinal Level of Precision
Score is a discrete measure or category (discontinuous) but there is a distinct and agreed upon order of these measures, categories
The order is symbolized with the use of numbers, but there is no implication of equal intervals between the numbers
Examples include any ordered scale
Can say = & ≠, and greater than (>) or less than (<)
Interval Level of Precision
Numbers in an agreed upon order and there are equal intervals between the numbers
Continuous data ordered in a logical sequence with equal intervals between all of the numbers and intervening numbers have a meaningful value
There is no true beginning value – there is a 0 but it is an arbitrary point
Examples:
- Temperature
- Dates
- Latitude (from +90° to −90° with equator being 0
Interval level can say = or ≠; < or >; and how much higher (+) or how much lower (−)
(Interval does not have a true 0 value; Ratio does)
Ratio Level of Precision
Numbers in an agreed upon order and there are equal intervals between the numbers
Continuous data ordered in a logical sequence with equal intervals between all of the numbers and intervening numbers have a meaningful value
There is a true beginning value – a true 0 value
Ratio level – can do everything with interval but also can us terms like 2X or double (×) or half (÷) when comparing values
(Interval does not have a true 0 value; Ratio does)
Mathematical Comparison of Precision Levels
Nominal level – can only indicate equal (=) or not equal (≠)
Ordinal level – can say not only = & ≠ but also greater than (>) or less than (< or >; and how much higher (+) or how much lower (−)
Interval level can say = or ≠; < or >; and how much higher (+) or how much lower (−)
Ratio level – can do everything with interval but also can us terms like 2X or double (×) or half (÷) when comparing values
Statistical Reasoning for the Precision Levels
Nominal level – unit of central tendency is the mode and any variability is assessed using range of values
Ordinal level – unit of central tendency is the median and any variability is assessed using range of values
Interval or Ratio (Metric) - unit of central tendency is the mean and any variability is assessed using standard deviation if normally distributed
Intra-Rater Reliability
Tested by having a group of subjects tested and then re-tested by the same person and/or instrument after an appropriate period of time
Inter-Rater Reliability
Reliability between measurements taken by two or more investigators or instruments
Different instruments or different investigators
Objective Testing
Usually has both high intra-rater and inter-rater reliabilities
Example: isokinetic dynamometer to measure muscle force (torque)
Raters are trained in the use and calibration of the instrument
Parallel Forms Reliability
Specific type of reliability used when the initial testing itself may affect the second testing.
Two separate forms of the exam covering the same material, or testing the same characteristic, are used
Investigators must first do testing to demonstrate that the two forms of the test are, in fact, equivalent
Face Validity (Judgmental)
Judgment of whether an instrument appears to be valid on the face of it - on superficial inspection, does it appear to measure what it purports to measure?
To accurately assess this requires a good deal of knowledge about the instrument and what it is to measure.
That is why professional judgment is emphasized in the definition of judgmental validity
Content Validity (Judgmental)
Judgment on the appropriateness of its contents.
The overall instrument and parts of the instrument are reviewed by experts to determine that the content of the instrument matches what the instrument is designed to measure
Empirical Validity (Criterion-Related Validity)
Use of data, or evidence, to see if a measure (operational definition) yields scores that agree with a direct measure of performance
2 forms of Empirical Validity:
- Predictive
- Concurrent
Predictive Validity (Empirical)
Measures to what extent the instrument predicts an outcome variable.