DS interview questions Flashcards
Source: https://www.edureka.co/blog/interview-questions/data-science-interview-questions/ https://towardsdatascience.com/over-100-data-scientist-interview-questions-and-answers-c5a66186769a (109 cards)
50 small DT vs 1 big one
“Is a random forest a better model than a decision tree?”
- yes because a random forest is an ensemble method that takes many weak decision trees to make a strong learner.
- more accurate, more robust, and less prone to overfitting.
Administrative datasets vs Experimental studies datasets.
Administrative datasets are typically
- datasets used by governments or other organizations for non-statistical reasons.
- Usually larger and more cost-efficient than experimental studies.
- Regularly updated assuming that the organization associated with the administrative dataset is active and functioning.
- May not capture all of the data that one may want and may not be in the desired format either.
- It is also prone to quality issues and missing entries.
What is A/B testing?
A/B testing is a form of hypothesis testing and two-sample hypothesis testing to compare two versions, the control and variant, of a single variable. It is commonly used to improve and optimize user experience and marketing.
Analyze a Data
Exploratory Data Analysis to clean, explore, and understand my data.
Compose a histogram of the duration of calls to see the underlying distribution.
What is bias-variance trade-off?
Bias: Bias is an error introduced in your model due to oversimplification of the machine learning algorithm. It can lead to underfitting. When you train your model at that time model makes simplified assumptions to make the target function easier to understand.
- Low bias machine learning algorithms — Decision Trees, k-NN and SVM
- High bias machine learning algorithms — Linear Regression, Logistic Regression
Variance: Variance is error introduced in your model due to complex machine learning algorithm, your model learns noise also from the training data set and performs badly on test data set. It can lead to high sensitivity and overfitting.
Normally, as you increase the complexity of your model, you will see a reduction in error due to lower bias in the model. However, this only happens until a particular point. As you continue to make your model more complex, you end up over-fitting your model and hence your model will start suffering from high variance.
Bias-Variance trade-off: The goal of any supervised machine learning algorithm is to have low bias and low variance to achieve good prediction performance.
- The k-nearest neighbour algorithm has low bias and high variance, but the trade-off can be changed by increasing the value of k which increases the number of neighbours that contribute to the prediction and in turn increases the bias of the model.
- The support vector machine algorithm has low bias and high variance, but the trade-off can be changed by increasing the C parameter that influences the number of violations of the margin allowed in the training data which increases the bias but decreases the variance.
There is no escaping the relationship between bias and variance in machine learning. Increasing the bias will decrease the variance. Increasing the variance will decrease bias.

How do you control for biases?
Two common things include randomization, where participants are assigned by chance, and random sampling, sampling in which each member has an equal probability of being chosen.
When you sample, what bias are you inflicting?
- Sampling bias: a biased sample caused by non-random sampling
- Under coverage bias: sampling too few observations
- Survivorship bias: error of overlooking observations that did not make it past a form of selection process.
- Selection Bias - sample obtained is not representative of the population intended to be analysed.
Unbalanced Binary Classification
- First, you want to reconsider the metrics that you’d use to evaluate your model. The accuracy of your model might not be the best metric to look at because and I’ll use an example to explain why. Let’s say 99 bank withdrawals were not fraudulent and 1 withdrawal was. If your model simply classified every instance as “not fraudulent”, it would have an accuracy of 99%! Therefore, you may want to consider using metrics like precision and recall.
- Another method to improve unbalanced binary classification is by increasing the cost of misclassifying the minority class. By increasing the penalty of such, the model should classify the minority class more accurately.
- Lastly, you can improve the balance of classes by oversampling the minority class or by undersampling the majority class.
Boosting
Boosting is an ensemble method to improve a model by reducing its bias and variance, ultimately converting weak learners to strong learners.
The general idea is to train a weak learner and sequentially iterate and improve the model by learning from the previous learner.
- AdaBoost - adds weight and bias to weaker learners
- Gradient Boosting - retrained loss
- XGBoost - better/faster Gradient boosting using parallel models
Boxplot vs Histogram
Boxplots and Histograms are visualizations used to show the distribution of the data
Histograms - bar charts
- show the frequency of a numerical variable’s values and are used to approximate the probability distribution of the given variable.
- It allows you to quickly understand the shape of the distribution, the variation, and potential outliers.
Boxplots
- you can gather other information like the quartiles, the range, and outliers.
- useful when you want to compare multiple charts at the same time because they take up less space than histograms.

Central Limit Theorem
CLT - sampling distribution of the sample mean approaches a normal distribution as the sample size gets larger no matter what the shape of the population distribution.
The central limit theorem is important because it is used in hypothesis testing and also to calculate confidence intervals.
What is Cluster Sampling?
Cluster sampling is a technique used when it becomes difficult to study the target population spread across a wide area and simple random sampling cannot be applied. Cluster Sample is a probability sample where each sampling unit is a collection or cluster of elements.
For eg., A researcher wants to survey the academic performance of high school students in Japan. He can divide the entire population of Japan into different clusters (cities). Then the researcher selects a number of clusters depending on his research through simple or systematic random sampling.
Collinearity / Multi-collinearity
Multicollinearity exists when an independent variable is highly correlated with another independent variable in a multiple regression equation. This can be problematic because it undermines the statistical significance of an independent variable.
You could use the Variance Inflation Factors (VIF) to determine if there is any multicollinearity between independent variables — a standard benchmark is that if the VIF is greater than 5 then multicollinearity exists.
In a study of emergency room waiting times, investigators consider a new and the standard triage systems. To test the systems, administrators selected 20 nights and randomly assigned the new triage system to be used on 10 nights and the standard system on the remaining 10 nights. They calculated the nightly median waiting time (MWT) to see a physician. The average MWT for the new system was 3 hours with a variance of 0.60 while the average MWT for the old system was 5 hours with a variance of 0.68. Consider the 95% confidence interval estimate for the differences of the mean MWT associated with the new system. Assume a constant variance. What is the interval? Subtract in this order (New System — Old System).
https://miro.medium.com/max/776/0*QpSg349Ozhe-etIQ.png
Confidence Interval = mean +/- t-score * standard error (see above)
mean = new mean — old mean = 3–5 = -2
t-score = 2.101 given df=18 (20–2) and confidence interval of 95%
standard error = sqrt((0.⁶²*9+0.⁶⁸²*9)/(10+10–2)) * sqrt(1/10+1/10)
standard error = 0.352
confidence interval = [-2.75, -1.25]

To further test the hospital triage system, administrators selected 200 nights and randomly assigned a new triage system to be used on 100 nights and a standard system on the remaining 100 nights. They calculated the nightly median waiting time (MWT) to see a physician. The average MWT for the new system was 4 hours with a standard deviation of 0.5 hours while the average MWT for the old system was 6 hours with a standard deviation of 2 hours. Consider the hypothesis of a decrease in the mean MWT associated with the new treatment. What does the 95% independent group confidence interval with unequal variances suggest vis a vis this hypothesis? (Because there’s so many observations per group, just use the Z quantile instead of the T.)
Assuming we subtract in this order (New System — Old System):
confidence interval formula for two independent samples
mean = new mean — old mean = 4–6 = -2
z-score = 1.96 confidence interval of 95%
st. error = sqrt((0.⁵²*99+²²*99)/(100+100–2)) * sqrt(1/100+1/100)
standard error = 0.205061
lower bound = -2–1.96*0.205061 = -2.40192
upper bound = -2+1.96*0.205061 = -1.59808
confidence interval = [-2.40192, -1.59808]
You are running for office and your pollster polled hundred people. Sixty of them claimed they will vote for you. Can you relax?
- Assume that there’s only you and one other opponent.
- Also, assume that we want a 95% confidence interval. This gives us a z-score of 1.96.
p-hat = 60/100 = 0.6
z* = 1.96
n = 100
This gives us a confidence interval of [50.4,69.6]. Therefore, given a confidence interval of 95%, if you are okay with the worst scenario of tying then you can relax. Otherwise, you cannot relax until you got 61 out of 100 to claim yes.
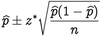
In a population of interest, a sample of 9 men yielded a sample average brain volume of 1,100cc and a standard deviation of 30cc. What is a 95% Student’s T confidence interval for the mean brain volume in this new population?
Given a confidence level of 95% and degrees of freedom equal to 8, the t-score = 2.306
Confidence interval = 1100 +/- 2.306*(30/3)
Confidence interval = [1076.94, 1123.06]
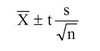
A diet pill is given to 9 subjects over six weeks. The average difference in weight (follow up — baseline) is -2 pounds. What would the standard deviation of the difference in weight have to be for the upper endpoint of the 95% T confidence interval to touch 0?
Upper bound = mean + t-score*(standard deviation/sqrt(sample size))
0 = -2 + 2.306*(s/3)
2 = 2.306 * s / 3
s = 2.601903
Therefore the standard deviation would have to be at least approximately 2.60 for the upper bound of the 95% T confidence interval to touch 0.
What is the difference between Point Estimates and Confidence Interval?
Point Estimation gives us a particular value as an estimate of a population parameter. Method of Moments and Maximum Likelihood estimator methods are used to derive Point Estimators for population parameters.
A confidence interval gives us a range of values which is likely to contain the population parameter. The confidence interval is generally preferred, as it tells us how likely this interval is to contain the population parameter. This likeliness or probability is called Confidence Level or Confidence coefficient and represented by 1 — alpha, where alpha is the level of significance.
What are confounding variables?
A confounding variable, or a confounder, is
- a variable that influences both the dependent variable and the independent variable, causing a spurious association,
- a mathematical relationship in which two or more variables are associated but not causally related.
What is a confusion matrix?
The confusion matrix is a 2X2 table that contains 4 outputs provided by the binary classifier. Various measures, such as error-rate, accuracy, specificity, sensitivity, precision and recall are derived from it.
A binary classifier predicts all data instances of a test data set as either positive or negative. This produces four outcomes:
- True-positive(TP) — Correct positive prediction
- False-positive(FP) — Incorrect positive prediction
- True-negative(TN) — Correct negative prediction
- False-negative(FN) — Incorrect negative prediction
Basic measures derived from the confusion matrix
- Error Rate = (FP+FN)/(P+N)
- Accuracy = (TP+TN)/(P+N)
- Sensitivity(Recall or True positive rate) = TP/P = TP/(TP+FN)
- Specificity(True negative rate) = TN/N = TN/(TN+FP)
- Precision(Positive predicted value) = TP/(TP+FP)
- F-Score(Harmonic mean of precision and recall) = (1+b)(PREC.REC)/(b²PREC+REC) where b is commonly 0.5, 1, 2.
F1-Score = (2 * Precision * Recall) / (Precision + Recall)
Convex vs Non-Convex cost function
A convex function is one where a line drawn between any two points on the graph lies on or above the graph. It has one minimum.
A non-convex function is one where a line drawn between any two points on the graph may intersect other points on the graph. It characterized as “wavy”.
When a cost function is non-convex, it means that there’s a likelihood that the function may find local minima instead of the global minimum, which is typically undesired in machine learning models from an optimization perspective.

What is correlation and covariance in statistics?
Both Correlation and Covariance establish the relationship and also measure the dependency between two random variables.
Correlation: Correlation is considered or described as the best technique for measuring and also for estimating the quantitative relationship between two variables. Correlation measures how strongly two variables are related.
Covariance: In covariance two items vary together and it’s a measure that indicates the extent to which two random variables change in cycle. It is a statistical term; it explains the systematic relation between a pair of random variables, wherein changes in one variable reciprocal by a corresponding change in another variable.
Cross-Validation
Cross-validation is essentially a technique used to assess how well a model performs on a new independent dataset. The simplest example of cross-validation is when you split your data into two groups: training data and testing data, where you use the training data to build the model and the testing data to test the model.
The goal of cross-validation is to limit problems like overfitting and get an insight on how the model will generalize to an independent data set.