Data Analysis Flashcards
What is a p-value?
= calculated probability of observing an effect size as large or larger than the one observed between the groups, if there was no genuine difference between the groups (i.e. if all of the data points for the groups being compared actually came from the same group)
E.g. ‘p=0.05’ = if there was no genuine difference between the groups, there would be a 5% probability of observing a difference of at least as large as the one observed.
P values are compared to a threshold value to determine if an effect size is statistically significant or not.
- If p < α, e.g. p = 0.01 and α = 0.05, = the difference is statistically significant (reject H0)
- If p ≥ α, e.g. p = 0.10 and α = 0.05, = the difference is not statistically significant (retain H0)
What is a unpaired t-test?
An unpaired t-test is appropriate for analysing parametric data fromindependent samples (unpaired data)
- t-tests only are used for paprametric data as the p-value is calculated assuming the data adheres to a normal distribution

What are the factors associated with large and small p-values?

What is the difference between two-tailed and one-tailed test?

Why can’t a t-test be used to analyse non-parametric data?
Parametric methods generate p-values by assuming a specific relationship between the variation of data points to the mean and the probability of observing them.
For non-parametric data, that relationship doesn’t exist, therefore any test that assumes the relationship exists will generate an inaccurate p-value
How do we determine if a dataset is parametric?
- Evaluate the distribution of data using a histogram
* is it symetrical, skewed and what level height is it? - use a test of normality
- eg. Shapiro-Wilk test, which performs a wuantitative analysis, estimating the probability that the samples are derived from a population that is normally distrubted
- The output of test = a p-value (which estimates the probability that the samples belong to a population that follows a normal distribution)
- Null hypothesis (H0) = The data is normally distributed
- Example alpha = 0.05
- If p

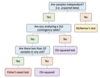
How do you work out what appropriate statistacal test to use?
(a) the distribution to which the data adheres (parametric vs. non-parametric),
(b) whether samples are independent (unpaired vs. paired data)
(c) the number of groups being compared (2 vs. 3 or more).

What do you do with non-parametric data?
Non-parametric methods such as the Mann-Whitney U test do not assume any particular distribution.
Rather than calculating p-values based on the probability of observing datapoints via reference to variation from the mean, non-parametric methods sort datapoints into ranks and calculate the probability of observing a particular distribution of ranks between the two experimental groups.
What is the difference between independent samples and non-independent samples?
Independent samples = unpaired data
Non-independent samples = paired data – this is where studies have groups consisting of the same samples, but where datapoints are generated at different timepoints
- Paired, parametric data = paired t-test
- Paired, non-parametric data = Wilcoxon Signed-Rank test
How can you increase the possibility of false positives occuring?
Performing multiple comparisons (multiple t-tests within a single study/analysis) –> increases the possibility of false positives occurring
What is analysis of vairiance? ANOVA?
standard approach used for statistical analysis of studies involving multiple comparisons.
It assumes the data is parametric and samples are independent
What is the difference between one-way ANOVA and two-way ANOVA?
One-way ANVOA is used for studies investigating the effect of 3 or more varying conditions on a single continuous variable
- Tests the null hypothesis that all groups contain random samples from the same population – ie. There is no statistical difference between any of the groups
Two-way ANOVA – used when studies also investigate whether there is an interaction between two categorical variables on a single continuous variable. It examines multiple hypotheses.
- Eg. Whether there is an interaction between the sex of patients and the effect of varying treatments on blood pressure

What are post-tests?
= used to analyse the statistical significance of specific pairs of groups when there is a significant ANOVA result
- Tukey’s test – used when a study requires pairwise comparison of every possible combination of groups
* A vs B, A vs C, A vs D, B vs C, B vs D, C vs D - Dunnett’s test – used when each pairwise comparison involves one specific group
* A vs B, A vs C, A vs D – A is the control group - Bonferroni’s test – used when the specific pairwise comparisons required do not follow a particular pattern
What are the alternative versions for using ANOVA’s and post-tests?

How would you use the two-way ANOVA with post-test?
In the event of a significant result, an appropriate post-test (e.g. Tukey’s test) can then be used to analyse multiple specific comparisons (if relevant, i.e. if either categorical variable has 3 or more groups),
Note: the standard two-way ANOVA assumes parametric data andindependent samples.
For analysing studies with non-independent samples (paired data) a‘two-way repeated measures ANOVA’ is used.
For non-parametric data, various rank-based approaches exist (e.g. aligned-rank transformation), however there validity is questionable (particularly in regard to analysing interaction effects).
How is categorical data presented?
Typically presented as a contingency table – present the possible options/states and the frequency of what each was observed
- Chi-squared test
- Fisher’s exact test
- McNemar’s test

When would you need to use a bonferroni correction?
When anaylsing using multiple comparisons, to avoid increasing the likelihood of a type-1 error occurring, we need to adjust our analysis
–> use a Bonferroni correction –> involves adjusting either the p-value to correct for the number of comparisons
- For n comparisons, multiply the p value output by n
- E.g. if study involves 3 separate comparisons and the alpha = 0.05, to assess statistical significance, each of the 3 separate raw p-value outputs generated would be multiplied by 3 (e.g. if a raw p-value output was 0.02, the adjusted value would be 0.06 and determined to be not statistically signficant).
How do you choose the appropriate statistical test to analyse categorical data?
- Has the data been collected from independent samples (i.e. is the data unpaired or paired)?
- Does the data being analysed conform to a 2x2 contingency table (i.e. only 2 groups and 2 categories)?
- Does the data feature a small* number of samples