Chapter2 Flashcards
(77 cards)
What is the topic for chapter2

What is text corpus?
a text corpus is a large body of text. Many corpora are designed to contain a careful balance of material in one or more genres
What is Gutenberg Corpus?
○ NLTK includes a small selection of texts from the Project Gutenberg electronic text archive, which contains some 25,000 free electronic books, hosted at http://www.gutenberg.org/
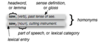
Importing words from NTLK using diff python import
import nltk >>> nltk.corpus.gutenberg.fileids() >>> emma = nltk.corpus.gutenberg.words(‘austen-emma.txt’) (Let’s pick out the first of these texts which is emma.txt)
Python provides another version of the import statement, as follows?
>>> from nltk.corpus import gutenberg >>> gutenberg.fileids() [‘austen-emma.txt’, ‘austen-persuasion.txt’, ‘austen-sense.txt’, …] >>> emma = gutenberg.words(‘austen-emma.txt’)
write program to display other information about each text, by looping over all the values of fileid corresponding to the gutenberg file and compute statistics.?
>>> for fileid in gutenberg.fileids(): … num_chars = len(gutenberg.raw(fileid)) … num_words = len(gutenberg.words(fileid)) … num_sents = len(gutenberg.sents(fileid)) … num_vocab = len(set(w.lower() for w in gutenberg.words(fileid))) … print(round(num_chars/num_words), round(num_words/num_sents), round(num_words/num_vocab), fileid) 5 25 26 austen-emma.txt 5 26 17 austen-persuasion.txt 5 28 22 austen-sense.txt 4 34 79 bible-kjv.txt 5 19 5 blake-poems.txt 4 19 14 bryant-stories.txt ○ This program displays three statistics for each text: average word length, average sentence length, and the number of times each vocabulary item appears in the text on average (our lexical diversity score). Observe that average word length appears to be a general property of English, since it has a recurrent value of 4. (In fact, the average word length is really 3 not 4, since the num_chars variable counts space characters.) By contrast average sentence length and lexical diversity appear to be characteristics of particular authors.
What does row() function does?
The raw() function gives us the contents of the file without any linguistic processing.or example, len(gutenberg.raw(‘blake-poems.txt’)) tells us how many letters occur in the text, including the spaces between words
What is sent() function ?
The sents() function divides the text up into its sentences, where each sentence is a list of words:
What is Brown corpus?
The Brown Corpus was the first million-word electronic corpus of English, created in 1961 at Brown University. This corpus contains text from 500 sources, and the sources have been categorized by genre, such as news, editorial, and so on . b. We can access the corpus as a list of words, or a list of sentences (where each sentence is itself just a list of words). We can optionally specify particular categories or files to read:
how to find categories at Brown corpus?
>>> from nltk.corpus import brown >>> brown.categories()
In which case Brown university corpus important?
ii. The Brown Corpus is a convenient resource for studying systematic differences between genres, a kind of linguistic inquiry known as stylistics.
WRITE program to compare genres in their usage of modal verbs
>>> from nltk.corpus import brown >>> news_text = brown.words(categories=’news’) >>> fdist = nltk.FreqDist(w.lower() for w in news_text) >>> modals = [‘can’, ‘could’, ‘may’, ‘might’, ‘must’, ‘will’] >>> for m in modals: … print(m + ‘:’, fdist[m], end=’ ‘) … can: 94 could: 87 may: 93 might: 38 must: 53 will: 389 We need to include end=’ ‘ in order for the print function to put its output on a single line.
If you want use FreqDistr u need to import what?
from nltk import FreqDist
What is Reuters Corpus ?
The Reuters Corpus contains 10,788 news documents totaling 1.3 million words. b. The documents have been classified into 90 topics, and grouped into two sets, called “training” and “test”; thus, the text with fileid ‘test/14826’ is a document drawn from the test set.
Inaugural Address Corpus
we looked at the Inaugural Address Corpus, but treated it as a single text . However, the corpus is actually a collection of 55 texts, one for each presidential address. An interesting property of this collection is its time dimension:
Example Inaugural corpus
>> from nltk.corpus import inaugural >>> inaugural.fileids() [‘1789-Washington.txt’, ‘1793-Washington.txt’, ‘1797-Adams.txt’, …] >>> [fileid[:4] for fileid in inaugural.fileids()] [‘1789’, ‘1793’, ‘1797’, ‘1801’, ‘1805’, ‘1809’, ‘1813’, ‘1817’, ‘1821’, …]
Annotated Text Corpora for teaching and learning
Many text corpora contain linguistic annotations, representing POS tags, named entities, syntactic structures, semantic roles, and so forth. NLTK provides convenient ways to access several of these corpora, and has data packages containing corpora and corpus samples, freely downloadable for use in teaching and research
Some of the corpora
- Movie Reviews Pang, Lee 2k movie reviews with sentiment polarity classification SentiWordNet Esuli, Sebastiani sentiment scores for 145k WordNet synonym sets Wordlist Corpus OpenOffice.org et al 960k words and 20k affixes for 8 languages WordNet 3.0 (English) Miller, Fellbaum 145k synonym sets
Loading your own Corpus
f you have your own collection of text files that you would like to access using the above methods, you can easily load them with the help of NLTK’s PlaintextCorpusReader
- The second parameter of the PlaintextCorpusReader initializer
can be a list of fileids, like [‘a.txt’, ‘test/b.txt’], or a pattern that matches all fileids, like ‘[abc]/.*.txt’
Example of importing file
>>> from nltk.corpus import PlaintextCorpusReader >>> corpus_root = ‘/usr/share/dict’
>>> wordlists = PlaintextCorpusReader(corpus_root, ‘.*’)
>>> wordlists.fileids() [‘README’, ‘connectives’, ‘propernames’, ‘web2’, ‘web2a’, ‘words’] >>> wordlists.words(‘connectives’) [‘the’, ‘of’, ‘and’, ‘to’, ‘a’, ‘in’, ‘that’, ‘is’, …]
Generating Random Text with Bigrams Eaxample?
The bigrams() function takes a list of words and builds a list of consecutive word pairs. Remember that, in order to see the result and not a cryptic “generator object”, we need to use the list()function:
>>> import nltk
>>> sent = [‘In’, ‘the’, ‘beginning’, ‘God’, ‘created’, ‘the’, ‘heaven’]
>>> list(nltk.bigrams(sent))
[(‘In’, ‘the’), (‘the’, ‘beginning’), (‘beginning’, ‘God’), (‘God’, ‘created’), (‘created’, ‘the’), (‘the’, ‘heaven’)]
>>>
Advise on testing code with an editor?
• It is often convenient to test your ideas using the interpreter, revising a line of code until it does what you expect
Once you’re ready, you can paste the code (minus any >>> or … prompts) into the text editor, continue to expand it, and finally save the program in a file so that you don’t have to type it in again later
How to name file in python?
Give the file a short but descriptive name, using all lowercase letters and separating words with underscore
Functions
A function is just a named block of code that performs some well-defined task
• We define a function using the keyword def followed by the function name and any input parameters, followed by the body of the functio