Chapter 6: Decision Trees Flashcards
(32 cards)
Decision Trees
- An internal node is a test on an attribute.
- A branch represents an outcome of the test, e.g., Color=red.
- A leaf node represents a class label or class label distribution.
- At each node, one attribute is chosen to split training examples into distinct classes as much as possible.
- A new case is classified by following a matching path to a leaf node
Building Decision Tree
- Top-down tree construction (Recursive Algo ⇒ End up with huge tree. If model is over fitted means it does not generalize well )
- At start, all training examples are at the root.
- Partition the examples recursively by choosing one attribute each time.
- Bottom-up tree pruning
- Remove subtrees or branches, in a bottom-up manner, to improve the estimated accuracy on new cases
Choosing the Splitting Attribute
- At each node, available attributes are evaluated on the basis of separating the classes of the training examples.
- A “goodness” function is used for this purpose. Typical goodness functions:
- information gain (ID3/C4.5)
- information gain ratio
- gini index (CART)
- Pcrkct split criteria: Splits data in two sides - Yes and No. ⇒ clean subnodes
A Criterion for Attribute Selection
- Which is the best attribute?
- The one which will result in the smallest tree
- Heuristic: choose the attribute that produces the “purest” nodes
- Popular impurity criterion: information gain
- Information gain increases with the average purity of the subsets that an attribute produces
- Strategy: choose attribute that results in greatest information gain
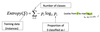
Computing Information
- Information is measured in bits
- Given a probability distribution, the info required to predict an event, i.e. if play is yes or no, is the distribution’s entropy
- Entropy gives the information required in bits (this can involve fractions of bits!)
- Formula for computing the information entropy:
- Defines how ordered a system is

Example: attribute “Outlook”

Computing the Information Gain

Continuing to Split
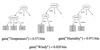
The Final Decision Tree
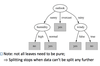
Wish List for a Purity Measure
- Properties we require from a purity measure:
- When node is pure, measure should be zero (=0)
- When impurity is maximal (i.e. all classes equally likely), measure should be maximal (e.g., 1 for boolean values)
- Multistage property: Info[2,3,4]=Info[2,7]+7/9 Info[3,4]
- Entropy is a function that satisfies these properties
Entropy
- Entropy in general, describes the randomness of a system
- Entropy = 0 describes a perfectly ordered system
- The term was used in thermodynamics and and statistical mechanics „ A Mathematical Theory of Communication“ by Claude Shannon 1948 defines entropy and information theory
- „uncertainty about the contents of a message“
Expected Information Gain
Gain(S,a) is the information gained adding a sub-tree (Reduction in number of bits needed to classify an instance)
Problems?

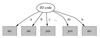
Highly-Branching Attributes
- Problematic: attributes with a large number of values (extreme case: ID code) Subsets are more likely to be pure if there is a large number of values
- Information gain is biased towards choosing attributes with a large number of values
- This may result in overfitting (selection of an attribute that is non-optimal for prediction)
Split for ID Code Attribute
Entropy of split = 0 (since each leaf node is “pure”), having only one case. Information gain is maximal for ID code
Gain Ratio
- Gain ratio: a modification of the information gain that reduces its bias on high-branch attributes 4 ->Corrects ID problem
- Gain ratio takes number and size of branches into account when choosing an attribute
- It corrects the information gain by taking the intrinsic information of a split into account (i.e. how much info do we need to tell which branch an instance belongs to)
Computing the Gain Ratio
Example: intrinsic information for ID code
intrinsic_info(1,1, ,1) = 14 x( - 1/14 x log1/14)= 3.807 bits Importance of attribute decreases as intrinsic information grows.

More on the Gain Ratio
- „Outlook” still comes out top
- However:
- “ID code” has still greater gain ratio (0.246)
- Standard fix: ad hoc test to prevent splitting on that type of attribute
- Problem with gain ratio: it may overcompensate
- May choose an attribute just because its intrinsic information is very low
- Standard fix:
- First, only consider attributes with greater than average information gain
- Then, compare them on gain ratio
The Splitting Criterion in CART
- Classification and Regression Tree (CART)
- Developed 1974-1984 by 4 statistics professors
- Leo Breiman (Berkeley), Jerry Friedman (Stanford), Charles Stone (Berkeley), Richard Olshen (Stanford)
- Gini Index is used as a splitting criterion
- Both C4.5 and CART are robust tools
- No method is always superior – experiment!
Gini Index for 2 Attribute Values
- For example, two classes, Pos(itive) and Neg(ative), and dataset S with p Pos-elements and n Neg-elements.
- fp = p / (p+n)
- fn = n / (p+n)
- Gini(S) = 1 – fp2 - fn2
- If dataset S is split into S1, S2 then Ginisplit(S1, S2) = (p1+n1)/(p+n) ·Gini(S1) + (p2+n2)/(p+n) · Gini(S2)
Gini Index for 2 Attribute Values Example

Gini Index 2 Attributes Example 2
Select the split that decreases the Gini Index most. This is done over all possible places for a split and all possible variables to split.

Generate_DT(samples, attribute_list)
- Create a new node N;
- If samples are all of class C then label N with C and exit;
- If attribute_list is empty then label N with majority_class(samples) and exit;
- Select best_split from attribute_list;
- For each value v of attribute best_split:
- Let S_v = set of samples with best_split=v ;
- Let N_v = Generate_DT(S_v, attribute_list \ best_split) ;
- Create a branch from N to N_v labeled with the test best_split=v;
Time Complexity of Basic Algorithm
- Let m be the number of attributes
- Let n be the number of instances
- Assumption: Depth of tree is O(log n)
- Usual assumption if the tree is not degenerate
- For each level of the tree all n instances are considered (best = vi)
- O(n log n) work for a single attribute over the entire tree
- Total cost is O(mn log n) since all attributes are eventually considered.
- Without pruning (see next class)
Scalability of DT Algorithms
- Need to design for large amounts of data Two things to worry about
- Large number of attributes
- Leads to a large tree
- Takes a long time
- Large amounts of data
- Can the data be kept in memory?
- Some new algorithms do not require all the data to be memory resident
