Chapter 10: MapReduce Flashcards
(35 cards)
1
Q
Origins cont’d
A
- Task for processing large amounts of data
- Split data
- Forward data and code to participant nodes
- Check node state to react to errors
- Retrieve and reorganize results
- Need: Simple large-scale data processing
- Inspiration from functional programming
- Google published MapReduce paper in 2004
2
Q
From Lisp to MapReduce - important features
A
- Two important concepts in functional programming
- Map: do something to everything in a list
- Fold: combine results of a list in some way
3
Q
Map
A
- Map is a higher-order function (= takes one or more functions as arguments)
- How map works:
- Function is applied to every element in a list
- Result is a new list

4
Q
Fold
A
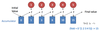
- Fold is also a higher-order function
- How fold works:
- Accumulator (generalization of a counter) set to initial value
- Function applied to list element and the accumulator
- Result stored in the accumulator
- Repeated for every item in the list
- Result is the final value in the accumulator
5
Q
Lisp -> MapReduce
A
- Let’s assume a long list of records: imagine if…
- We can distribute the execution of map operations to multiple nodes
- We have a mechanism for bringing map results back together in the fold operation
- That’s MapReduce! (and Hadoop)
- Implicit parallelism:
- We can parallelize execution of map operations since they are isolated
- We can reorder folding if the fold function is commutative and associative
- Commutative -> change order of operands: x*y = y*x
- Associative -> change order of operations: (2+3)+4 = 2+(3+4)=9
6
Q
MapReduce - basics
A
- Programming model & runtime system for processing large data-sets
- E.g., Google’s search algorithms (PageRank: 2005 – 200TB indexed)
- Goal: make it easy to use 1000s of CPUs and TBs of data
- Inspiration: Functional programming languages
- Programmer specifies only “what”
-
System determines “how”
- Schedule, parallelism, locality, communication..
-
Ingredients:
- Automatic parallelization and distribution ( # nodes ,
- Fault-tolerance
- I/O scheduling
- Status and monitoring
7
Q
Simplified View of Architecture
A
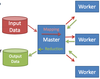
- Input data is distributed to workers (i.e., available nodes)
- Workers perform Data computation
- Master coordinates worker selection & fail-over
- Results stored in output data files
8
Q
MapReduce Programming Model
A
- Input & output: each a set of key/value pairs
- Programmer specifies two functions:
-
map (in_key, in_value) -> list(out_key, intermediate_value)
- Processes input key/ value pair
- Produces set of intermediate pairs
-
reduce (out_key, list(intermediate_value)) -> list(out_value)
- Combines all intermediate values for a particular key
- Produces a set of merged output values (usually just one)
- User also specifies I/O locations and tuning parameters
- Partition (out_key,number of partitions) -> partition for out_key
-
map (in_key, in_value) -> list(out_key, intermediate_value)
9
Q
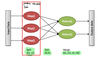
Map() function
A
- Records from the data source (lines out of files, rows of a database, etc.) are fed into the map function as key-value pairs: e.g., (filename, line)
- Map() produces one or more intermediate values along with an output key from the input
10
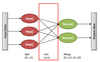
Q
Sort and schuffle
A
- Map reduce framework
- Shuffles and sorts intermediate pairs based on key
- Assigns resulting streams to reducers
11
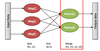
Q
Reduce()
A
- After the map phase is over, all the intermediate values for a given output key are combined together into a list
- Reduce() combines those intermediate values into one or more final values for that same output key
- In practice, usually only one final value per key)
12
Q
MapReduce execution stages
A
- Scheduling: assigns workers to map and reduce tasks
- Data distribution: moves processes to data (Map)
- Synchronization: gathers, sorts, and shuffles intermediate data (Reduce)
- Errors and faults: detects worker failures and restarts
13
Q
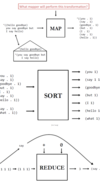
MapReduce example: Word count
A
- Word count: Count the frequency of word appearances in set of documents
-
MAP: Each map gets a document. Mapper generates key/value pairs each time the word appears (word,”1”)
- INPUT: (filename, fileContent), where FileName is the key and FileContent is the value
- OUTPUT: (word wordApparence), where word is key and wordApparence is value
-
REDUCE: Combines the values per key and computes the sum
- INPUT: (word,List) where word is the key and Listis the value
- OUTPUT: (word, sum) where word is the key and sumis the value
14
Q
Combiners
A
- Often a map task will produce many pairs of the form (k,v1), (k,v2), … for the same key k
- E.g., popular words in Word Count
- Can save network time by pre-aggregating at mapper
- For associative ops. like sum, count, max
- Decreases size of intermediate data
- Example: local counting for word count:
- def combiner(key, values): output(key, sum(values))
15
Q
Partition Function
A
- Inputs to map tasks are created by contiguous splits of input file
- For reduce, we need to ensure that records with the same
- intermediate key end up at the same worker
- System uses a default partition function e.g., hash(key) mod R
- Sometimes useful to override
- Balance the loads
- Specific requirement on which key value pairs should be in the same output files
16
Q
Parallelism
A
- map() functions run in parallel, creating different intermediate values from different input data sets
- reduce() functions also run in parallel, each working on a different output key
- All values are processed independently
- Bottleneck: reduce phase can’t start until map phase is completely finished.

17
Q
Fault Tolerance & Optimizations
A
- In a machine with 1000s of nodes, failures are common
- On worker failure:
- Detect failure via periodic heartbeats
- Re-execute completed and in-progress map tasks
- Re-execute in progress reduce tasks
- Task completion committed through master
- Not dealing with master failures so far…
- Optimization for fault-tolerance and load-balancing
- Slow workers significantly lengthen completion time
- Due to other jobs on machines, disk with errors, caching issues, …
- Other jobs consuming resources on machine
- Solution: Near end of phase, spawn backup copies of tasks
- Which ever one finishes first “wins”
- Slow workers significantly lengthen completion time
18
Q
Criticism
A
- Too low level
- Manual programming of per record manipulation
- As opposed to declarative model
-
Nothing new
- Map and reduce are classical Lisp or higher order functions
-
Low per node performance
- Due to replication and data transfer
19
Q
MapReducable?
A
- One-iteration algorithms are perfect fits
- Multiple-iteration algorithms are good fits
- But small shared data have to be synchronized across iterations (typically through filesystem)
- Some algorithms are not good for MapReduce framework
- Those algorithms typically require large shared data with a lot of synchronization (many machine learning algorithms)
- Many alternatives: Iterative MapReduce Frameworks or Bulk Synchronous
- Processing Frameworks

20
Q
One-iteration: Inverted index NN
A
- List of documents that contain a certain term – Basic structure of modern search engines
- Map process (parser)
- Tokenize documents
- Create (term, document) pairs
- Combine process
- Locally combine pairs with same term to postings lists
- Reduce process (inverter)
- Combine all postings lists for a term
21
Q
Iterative MapReduce
A
- Iterative algorithms: Repeat map and reduce jobs
- Examples: PageRank, K-means, SVM and many more
- In MapReduce, the only way to share data across jobs is stable storage -> slow !
- Some proposed solutions include: Twister and Spark

22
Q
Spark basics NN
A
- Up to 100x faster than Hadoop MapReduce
- Several programming interfaces (Java, Scala, Python, R)
- Powers a stack of useful libraries (MLlib, GprahX, Spark Streaming )
- Fault tolerance (for crashes & stragglers)
- Extremely well documented
- Based on the concept of a resilient distributed dataset (RDD):
- Read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost
- Created by transforming data in stable storage using data flow operators (map, filter, group by, …)
- A handle to an RDD contains enough information to compute the RDD starting from data in reliable storage
- Can be cached across parallel operations
23
Q
Bulk Synchronous Parallel (BSP) abstract computer
A
- BSP is a parallel programming model: Distributed-memory parallel computer
- Global vision of a number of processor/memory pairs interconnected by a communication network
- Offers several advantages over MapReduce and MPI
- Supports message passing paradigm style for application development
- Provides a flexible, simple, and easy-to-use small API
- Enables to perform better than MPI for communication-intensive applications: All communication actions considered as a unit
- Guarantees impossibility of deadlocks or collisions in the communication mechanisms: Synchronization is part of the programming model
- Predictable performance
24
Q
BSP model NN
A
- Processor-memory pairs
- Communications network that delivers messages in a point- to-point manner
- Mechanism for the efficient barrier synchronization for all or a subset of the processes
- There are no special combining, replicating, or broadcasting facilities

25
BSP programs NN
* BSP programs composed of supersteps
* In each superstep, processors execute computation
* Steps using locally stored data, and steps can send and receive messages
* Processors synchronize at end of superstep (at which time all messages have been received)
26
What is MapReduce?
Programming model and runtime for processing large data-sets (in clusters).
27
How does MapReduce differ from message-passing interface (MPI) and remote procedure calls (RPC)?
It offers a higher layer of abstraction at the cost of generality.
28
What does MapReduce offer? Provide at least three bullet points
* Automatic parallelization and distribution
* Fault-tolerance
* I/O scheduling
* Status and monitoring
29
Describe the different stages in the execution framework of MapReduce (4 bullet points).
* Scheduling: assigns workers to map and reduce tasks
* Data distribution: moves processes to data (Map)
* Synchronization: gathers, sorts, and shuffles intermediate data (Reduce)
* Errors and faults: detects worker failures and restarts
30
What type of algorithms are not good for the MapReduce framework ?
Algorithms that typically require large shared info with a lot of synchronization, e.g., SVM.
31
Word count: Count the frequency of word apperances in set of ducuments.
**MAP**: Each map gets a document. The mapper generates many key/value pairs for the apperance of a word, i.e., (word, "1")
* **Input**: (fileName, fileContent) , where fileName is the key and fileContent is the value
* **Output**: (word, wordApparence)-pairs, where word is the key, and wordApparence is the value
**REDUCE**: Combines thevalues for a key and computes the sum
* **Input**: (word, List)
* **Output**: (word, sum(wordApparence))
32
Search for a pattern: Data is a set of files containing lines of text. Output the file names that contain this pattern.
**MAP**: Given (filename, some text) and "pattern", if "text" matches "pattern" output (filename, \_)
* **Input**: The whole file, line by line (filename, some text) and pattern
* **Output**: (filename, \_)-pairs, where filename is the key and value is notrelevant
**REDUCE**: Identity function. Data is not changed
* **Input**: (filename, \_)
* **Output**: (filename, \_)
33
The MapReduce formulation of K-means usually needs a driver or wrapper around the normal execution framework. What is the reason for this?
Because of the iterations required in the K-means procedure, we need to loop MapReduce. The MapReduce K-means algorithm can be formulated using the following components:
* Driver or wrapper
* Mapper
* Combiner
* Reducer
34
Consider that a single file contains the predefined cluster centers K and the data points are distributed in several files. Provide a short description defining the task performed by each component of MapReduce K-means and define their input and output.
* **Driver** or **wrapper**
* Runs multiple iteration jobs using mapper+combiner+reducer
* **Mapper**
* Task: Assign each point to closest centroids
* Configure: A single file containing cluster centers
* Input: Input data points
* Output: (data id, cluster id)
* **Combiner**
* Input:(data id, cluster id)
* Output: (cluster id, (partial sum, number of points))
* **Reduces**
* Task: Update each centroid with its new location
* Input:(data id, cluster id)
* Output: (cluster id, cluster centroid)
35
What characteristic of K-means could cause a large computation overhead?
Since we are looping MapReduce, this means constant access to the IO (Hard-drive), if the K-means requires a large amount of iterations this could be a major source for time delay.
