3. Threads and Concurrency Flashcards
(28 cards)
What are threads?
Multiple execution processes within a single process.
How are threads different than processes?
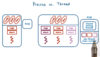
A single-threaded process has its own address space and execution context. The OS stores this info in a process control block (PCB).
Threads are part of the same address space but they represent multiple independent execution contexts. Threads have their own private copy of the stack, program counter, registers, etc. The OS stores this info in a more complex process control block (PCB).
Why are threads useful?
- Parallelization
- We can speed up the time to complete work
- Specialization
- We can give higher priority to certain types of tasks
- We can get better performance b/c if a thread is repeatedly executes a smaller portion of the code more of that state will be present in the processor cache (hotter cache)
- More memory efficient than a multi-process implementation b/c threads share an address space. (If we did as a multi-process implementation we’d have to allocate multiple address space + multiple execution context for each process vs just one address space + multiple execution contexts).
- Threads share an address space so the application is more likely to fit into memory and not require as many swaps from disk.
- Lower communication overhead
- Communicating between processes is more costly than communicating between threads.
In summary: More efficient in resource requirements and incur lower overheads for inter-thread communication than inter-process.
Are threads useful on a single CPU?
Or when the number of threads is greater than the number of CPUs?
Yes!
One of the most costly steps during a context switch is the time it takes to create the new virtual to physical address mappings for a new process. But threads don’t pay this cost b/c they share an address space so we don’t have to create new virtual to physical address mappings during a context switch!
So multi-threaing lets us hide more of the latency that’s associated with I/O opperations.

How should threads be represented by an operating system or a system library that provides multi-threading suport?
- Thread data structure (Birell proposed “Thread type”)
- e.g., Thread ID, register values (program counter, stack pointer), stack, attributes
What concurrency and coordination mechanisms (aka synchronization mechanisms) do we need to support threads?
-
Mutual Exclusion: exclusive access to only one thread at a time
- Mutex
-
Waiting on other threads for a specific condition before proceeeding
- Condition variables
- Waking up other threads from a waiting state
What is necessary for thread creation? And what did Birell propose?
- A way to create a thread
- Birell proposed
fork (procedure, args)- Note: This is NOT a UNIX fork.
- Birell proposed
- A way to determine if a thread is done and retrieve it’s result or at least determine it’s status (e.g., success or failure)
- Birell proposed
join(thread_id) - When the parent calls join with the id of the child thread it will be blocked until the child completes. Join returns to the parent the result of the child’s computation. It exits, its resources are freed, and its terminated.
- Birell proposed
What’s the difference between mutual exclusion and mutex?
Mutual exclusion is a mechanism.
A mutex is a construct by which mutual exclusion is achieved.
What is a mutex?
A mutex is a construct for mutual exclusion among the execution of concurrent threads.
Use whenever accessing data or state that’s shared among threads.
When a thread locks a mutex it has exclusive access to the shared resource. Other threads will be suspended until the mutex owner releases the lock and they can aquire the lock.
The mutex specification doesn’t make any guarantees about the order of the lock request queue (i.e., requesting first doesn’t guarantee you’ll get it first)
Also, just because there are requests in the queue doesn’t mean the lock will go to one of those. If a thread requests a lock just as its being released it’s possible it could aquire it even though there are pending requests.
What data structure do we need to support a mutex?
- locked status
- owner
- list of blocked threads
What is the critical section?
A critical section is the portion of the code protected by the mutex.
It should be the part of the code that requires that only one thread at a time perform this operation.
Other than the cirtical section, the rest of the code in the program the threads may execute concurrently.
Birel proposed that the critical section is the part between the curly braces of the lock function. In his semantics, calling Lock locks the mutex and then exiting the curly brace unlocks it. In most APIs today you must explicity call Lock and Unlock.
What is a condition variable?
A construct that can be used in conjunction with mutexes to control the behavior concurrent threads.
e.g., It allows us to wait for an event before doing something
What is the condition variable API?
- Condition type
-
Wait(mutex, condition)- mutex is automatically released and re-aquired on wait
-
Signal(cond)- notify only one thread waiting on condition
-
Broadcast(cond)- notify all waiting threads
What data structure is required to support a condition variable?
- mutex reference
- list of waiting threads
What is a spurious wake up?
An unnecessary wake up e.g., waking up a thread when it can’t actually aquire the lock and will have to go immediately back into a waiting state.
What is a deadlock
Two or more competing threads are waiting on each other to complete but non of them ever do.
Deadlocks can happen when there’s a cycle in the wait graph. For example If thread 1 will try to lock mutex A then mutex B and thread 2 will try to lock mutex B then mutex A, then we can have a scenario where two threads have one mutex and are waiting on aquiring the other.
How does a deadlock happen?
Deadlocks can happen when there’s a cycle in the wait graph. For example If thread 1 will try to lock mutex A then mutex B and thread 2 will try to lock mutex B then mutex A, then we can have a scenario where two threads have one mutex and are waiting on aquiring the other.
What can we do about deadlocks?
- Deadlock prevention (can be expensive)
- Deadlock detection and recovery (requires ability to rollback)
- Apply the Ostrich Algorithm (do nothing…if all else fails just reboot)
Explain kernel-level vs user-level threads
Kernel level threads imply that the OS itself is multi-threaded. Kernel-level threads are visible to the kernel, and are managed by kernel-level components like the kernel-level scheduler.
It’s the OS scheduler that decides how the kernel-level threads will be mapped onto the underlying physical CPUs and which one will execute at any given time.
At the user-level the processes themselves are multi-threaded and these are the user-level threads. For a user-level thread to execute, it must be associated with a kernel-level thread, then the OS scheduler must schedule the kernel-level thread onto a CPU.
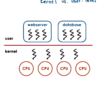
Explain the One-to-One Multithreading Model and it’s pros/cons.
Each user-level thread has a kernel-level thread associated with it.
Pros:
- OS sees/understands threads, sychronization, scheduling, blocking. Since the OS already supports these mechanisms to support its threads then the user-level processes directly benefit from the threading support that’s already available in the kernel
Cons:
- Every operation must go to the kernel crossing the user to kernel boundary, which can be expensive.
- Since we’re relying on the kernel to do the thread level management (sychronization, scheduling, etc.) we’re limited by the policies that are supported at the kernel level
- Portability. If an application has certain needs about how its threads should be managed, we’re limited to running the process only on kernels that provide that kind of support.
Explain the Many-to-One Multithreading Model and it’s pros/cons.
All user-level threads (w/in a process?) are mapped onto a single kernel-level thread. Those user-level threads will only run when the kernel-level thread they’re mapped to are scheduled to the CPU.
Pros:
- Portable. Doesn’t depend on OS limits and policies.
- B/c threads are managed by a user-level threading library, we don’t have to rely on the kernel and thus don’t have to cross the user/kernel boundary.
Cons:
- OS has no insight into the application needs. It doesn’t even know the applicaiton is mulit-threaded.
- So if one thread needs to do I/O and goes idle, the OS may context switch to a different thread even though there were other user-level threads that could have done work.

Explain the Many-to-Many Multithreading Model and it’s pros/cons.
Allows some user-level threads to be associated with one kernel-level thread, others to have a one-to-one mapping. The kernel knows the process is multi-threaded so if one user-level thread blocks on I/O and as a result the kernel-level thread is blocked on I/O, the process over all will have other kernel-level threads onto which the other user-level threads can be scheduled.
Pros:
- The user-level threads may be scheduled onto any of the underlying kernel-level threads (unbound) or we can have a certain user-level thread that’s mapped one-to-one permanently with a kernel-level thread (bound).
Cons:
- requires coordination between user and kernel level thread managers
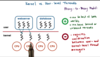
Explain process scope vs system scope w/ regards to multithreading
Process Scope: User-level library manages threads within a single process
System Scope: System-wide thread management by OS-level thread managers (e.g., CPU scheduler)
If user-level threads have a process scope, the operating system can’t see all of them so it may not give them as many resources as they need.
If user-level threads have a system scope, they’ll be visible at the kernel level, so it’s better able to give them the resources they need.
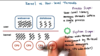
Explain the Boss/Workers Pattern
One thread is the boss, and many threads are the workers.
The boss assigns work. The workers do the work.
Throughput of the system is limited by the boss thread (throughput = 1 / boss_time_per_order) so we must keep the boss efficient.
We can limit the time the boss spends on assigning work by placing work in a producer/consumer queue (as opposed to handing off the work directly).



